记一次失败的kaggle比赛(3):失败在什么地方,贪心筛选特征、交叉验证、blending
今天这个比赛结束了,结果可以看:https://www.kaggle.com/c/santander-customer-satisfaction/leaderboard
public结果:
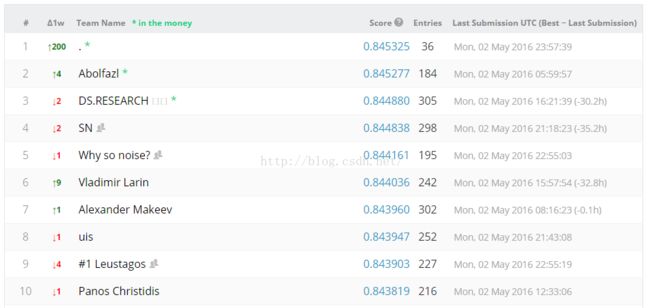
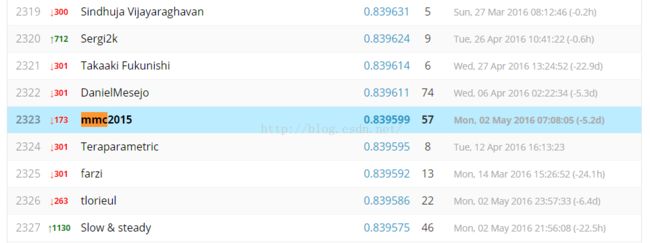
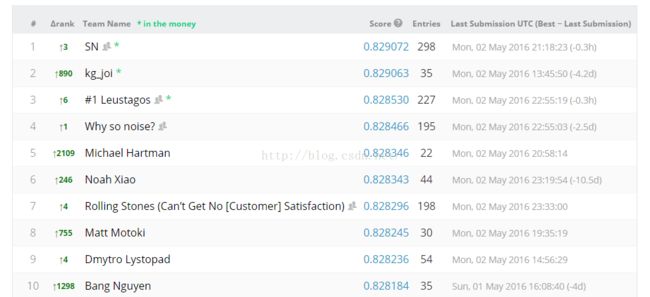
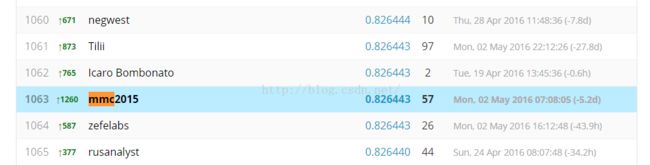
private结果:
首先对比private和public的结果,可以发现:
1)几乎所有的人都overfitting了;或者说private的另一半测试数据比public的那一半测试数据更不规律。
2)private的前十名有5个是在public中排不进前几百,有四个甚至排在1000名到2000名之间;说明使用一个正确的方法比一味地追求public上的排名更重要!!!
3)我自己从public的第2323名调到private的1063名,提高了1260个名次;作为第一次参加这种比赛的人,作为一个被各种作业困扰的人,能在有5236个队伍中、5831个选手中取得这样的成绩,个人还比较满意,毕竟经验不足,做了很多冤枉工作。
4)说回最关键的,什么叫做“一个正确的方法”???这也是我想探讨的失败之处:
1、选择正确的模型:因为对数据不了解,所以直接尝试了以下模型:
models=[
RandomForestClassifier(n_estimators=1999, criterion='gini', n_jobs=-1, random_state=SEED),
RandomForestClassifier(n_estimators=1999, criterion='entropy', n_jobs=-1, random_state=SEED),
ExtraTreesClassifier(n_estimators=1999, criterion='gini', n_jobs=-1, random_state=SEED),
ExtraTreesClassifier(n_estimators=1999, criterion='entropy', n_jobs=-1, random_state=SEED),
GradientBoostingClassifier(learning_rate=0.1, n_estimators=101, subsample=0.6, max_depth=8, random_state=SEED)
]2、上来不经过任何思考就开始使用各种复杂的模型,甚至连一个baseline都没有:对,我就是这样,因为第一次,确实缺乏经验;因为复杂的模型容易过拟合,所以你越比陷得越深;而且复杂模型一般花费时间比较多,真是浪费青春;这一点我是在快要没时间的时候才意识到的;另外,我的最终结果确实是通过一个非常简单的模型得到的。所以说,开始时先鲁一个简单的模型,以此为参照构建之后的模型。什么是简单的模型:原始数据集(或者稍微做了一点处理的数据集,比如去常数列、补缺失值、归一化等)、logistic regression或者简单的svm、xgBoost。
3、相信交叉验证的结果:不要只将数据集划分成两份,因为交叉验证时你会发现有些fold效果非常好,AUC可以到0.85左右,而有些fold则非常差,0.82都不到。
4、关于noise的问题:一直没找到好的处理办法,所以最终效果不是很好也正常。
5、关于一堆零的处理办法:归一化特征,这个非常有必要!否则你之后的特征工程都会发现效果很差,因为0+k=k、0*k=0、0^2=0;具体怎么归一化,我就不多说了,点到为止。
6、另外还有一些小细节,比如筛选特征时,因为你的最终模型是GBDT,那你筛选特征时就使用GBDT,否则你使用LR筛选的有效特征可能对GBDT模型来说并不是有效的;还有很多很多,真的是在实践中才能意识到,比如特征处理是在train+test上还是单独在train上这些问题,理论上只应该在train上,因为我们认为test数据集是不知道的,但是对于这种比赛,你知道了test,那还是用上的好。。。。不多说了,大家还是多实践好;科研再忙,一学期玩一个比赛还是有时间的。。。。。。。。
7、说了这么多没用的,给大家上一点代码,主要包括贪心筛选特征、交叉验证、blending三部分关键点,但是整个代码是完整的:
#!usr/bin/env python
#-*- coding:utf-8 -*-
import pandas as pd
import numpy as np
from sklearn import preprocessing, cross_validation, metrics
from sklearn.ensemble import RandomForestClassifier, ExtraTreesClassifier, GradientBoostingClassifier
from sklearn.cross_validation import StratifiedKFold
from sklearn.linear_model import LogisticRegression
from sklearn.externals import joblib
SEED=1126
nFold=5
def SaveFile(submitID, testSubmit, fileName="submit.csv"):
content="ID,TARGET";
for i in range(submitID.shape[0]):
content+="\n"+str(submitID[i])+","+str(testSubmit[i])
file=open(fileName,"w")
file.write(content)
file.close()
def CrossValidationScore(data, label, clf, nFold=5, scoreType="accuracy"):
if scoreType=="accuracy":
scores=cross_validation.cross_val_score(clf,data,label,cv=nFold)
#print("mean accuracy: %0.4f (+/- %0.4f)" % (scores.mean(), scores.std() * 2))
return scores.mean()
elif scoreType=="auc":
meanAUC=0.0
kfcv=StratifiedKFold(y=label, n_folds=nFold, shuffle=True, random_state=SEED)
for j, (trainI, cvI) in enumerate(kfcv):
print "Fold ", j, "^"*20
Xtrain=data[trainI]
Xcv=data[cvI]
Ytrain=label[trainI]
Ycv=label[cvI]
clf.fit(Xtrain,Ytrain)
probas=clf.predict_proba(Xcv)
aucScore=metrics.roc_auc_score(Ycv, probas[:,1])
#print "auc (fold %d/%d): %0.4f" % (i+1,nFold, aucScore)
meanAUC+=aucScore
#print "mean auc: %0.4f" % (meanAUC/nFold)
return meanAUC/nFold
def GreedyFeatureAdd(clf, data, label, scoreType="accuracy", goodFeatures=[], maxFeaNum=100, eps=0.00005):
scoreHistorys=[]
while len(scoreHistorys)<=2 or scoreHistorys[-1]>scoreHistorys[-2]+eps:
if len(goodFeatures)==maxFeaNum:
break
scores=[]
for testFeaInd in range(data.shape[1]):
if testFeaInd not in goodFeatures:
#tempFeaInds=goodFeatures.append(testFeaInd);
tempFeaInds=goodFeatures+[testFeaInd]
tempData=data[:,tempFeaInds]
score=CrossValidationScore(tempData, label, clf, nFold, scoreType)
scores.append((score,testFeaInd))
print "feature: "+str(testFeaInd)+"==>mean "+scoreType+": %0.4f" % score
goodFeatures.append(sorted(scores)[-1][1]) #only add the feature which get "the biggest gain score"
scoreHistorys.append(sorted(scores)[-1][0]) #only add the biggest gain score
#print scoreHistorys
print "current features: %s" % sorted(goodFeatures)
if len(goodFeatures) trainAuc=%f" % (c, trainAuc)
'''
C => trainProba
0.0001 => 0.126..
0.001 => 0.807188
0.01 => 0.815833
0.03 => 0.820674
0.04 => 0.821295
0.05 => 0.821439 ***
0.06 => 0.821129
0.07 => 0.820521
0.08 => 0.820067
0.1 => 0.819036
0.3 => 0.813210
1.0 => 0.809002
10.0 => 807334
'''
model.C=sortedtrainAucList[-1][1] #0.05
model.fit(dataset_trainBlend,trainY)
trainProba=model.predict_proba(dataset_trainBlend)[:,1]
print "train auc: %f" % metrics.roc_auc_score(trainY, trainProba) #0.821439
print "model.coef_: ", model.coef_
print "Predict and saving results..."
submitProba=model.predict_proba(dataset_testBlend)[:,1]
df=pd.DataFrame(submitProba)
print df.describe()
SaveFile(submitID, submitProba, fileName="1submit.csv") #0.815536 [blending makes result < GBC 0.8199]
#!!!!!!!!!!!!!!!!!!!!!!!!!!!!!! Blending models ISN'T a good idea when one model OBVIOUSLY better than others...
'''
count 75818.000000
mean 0.039187
std 0.033691
min 0.024876
25% 0.028400
50% 0.029650
75% 0.034284
max 0.806586
'''
print "MinMaxScaler predictions to [0,1]..."
mms=preprocessing.MinMaxScaler(feature_range=(0, 1))
submitProba=mms.fit_transform(submitProba)
df=pd.DataFrame(submitProba)
print df.describe()
SaveFile(submitID, submitProba, fileName="1submitScale.csv") #0.815536
'''
count 75818.000000
mean 0.018307
std 0.043099
min 0.000000
25% 0.004509
50% 0.006107
75% 0.012035
max 1.000000
''' 其实还有很多话想说,不过这个文章就到这边吧,毕竟一个1000+的人的说教会让人觉得烦;以后再参加其他比赛了一起说吧。
http://blog.kaggle.com/2016/02/22/profiling-top-kagglers-leustagos-current-7-highest-1/
和大牛不谋而合:
What does your iteration cycle look like?
- Understand the dataset. At least enough to build a consistent validation set.
- Build a consistent validation set and test its relationship with the leaderboard score.
- Build a very simple model.
- Look for approaches used in similar competitions in the past.
- Start feature engineering, step by step to create a strong model.
- Think about ensembling, be it by creating alternate versions of the feature set or using different modeling techniques (xgb, rf, linear regression, neural nets, factorization machines, etc).
https://www.kaggle.com/c/santander-customer-satisfaction/forums/t/20647/congrats?page=2
Some strategies we used to reduce overfitting are as follows: 1) use both local CV and public LB test to identify a couple of potentially good model candidates; 2) in our final solution, mainly use those model candidates which give "quite large" improvements and ignore those models that only provide small improvements, since those tiny improvements might be quite possible due to overfiting to the noise. For example, our best public LB score ensemble include >=60 individual models, and most of them only provide about <0.000050 tiny improvement. In our final ensemble which gave us #1 place on the private LB, I kicked out most of these models with tiny improvements, and the final ensemble only include about 5 models (here some of these 5 models are an average of running a model with many different random seeds); 3) for xgb models, run it with a couple of different seeds and slightly different parameters, and then take the average, this will also make its performance a bit more stable. 4) For those features like age<23 to identify 0 records, only used them very conservatively.
https://www.kaggle.com/c/santander-customer-satisfaction/forums/t/20662/overtuning-hyper-parameters-especially-re-xgboost
My question: How far should one tune the various parameters of xgboost? Here are my current limits:
- max_depth: to the nearest 1.
- min_child_weight: to the nearest 1.
- reg_alpha: to 1 significant figure (max 3 decimal places).
- reg_lambda: to 1 significant figure (max 3 decimal places).
- subsample: to the best 0.05
- colsample_bytree: to the best 0.05
- gamma: to the nearest 0.1 (in every case I have tried gamma < 1)
As mentioned above, I find that tuning further may cause a lower score against a held out test set.
To understand tuning, it helps to understand how tree based ensemble algorithms work. See Prettenhofer and Louppe slides among many, many others. Then it becomes a question about fitting the parameters to the data without overfitting (i.e. tuning the algorithm so far that it finds too many features that are specific only to the currently known data). Each parameter offers it's own unique opportunity to mess things up. Specifically
-
max_depth:
It's how many levels deep a tree is allowed to go. Each level allows you to catch an interaction between the previous split and a new variable. If a value < 3 works really well, you probably want to look at the data again to see why there aren't useful interactions. On the other side, the larger this value, the more possible it is to overfit training data. A good place to start is between 4 and 6. For higher values think about using one of the other parameters to add robustness. (Robustness means that the algorithm doesn't get tripped up by outliers in the training set which won't generalize well.) -
min_child_weight:
This is how big each group in the tree has to be. Larger values are more robust than smaller values (less likely to result in overfitting). Use the largest value you can that doesn't seem to hurt performance. Unfortunately, this value is also sensitive to the size of the training set. Namely min_child_weight/size_train is a lower bound on the probability of a type of event trees can hope to find. (In this case the ML estimate of this probability was .0396). If max_depth is not too high, you can start with 1, however the higher max_depth is, the higher this value should also be in order to avoid overfitting. -
reg_alpha, reg_lambda: These only apply if you are using the linear model as the base model in boosting and not the default tree model.
-
subsample:
-
colsample_bytree:
-
gamma: Never tried this one. No help here. Nada. Got nothink.
It's very suspicious if small changes in any of these parameters make large changes in CV. We should all have the robot that goes 'Danger! Danger Will Robinson' when that happens. Also good parameters should perform well regardless of the random seed used. The script only worked well with 1234. Now it was possible that 1234 could be magic on both the public and private sets....