今天用半小时为小伙伴们简单分享了Flink Streaming中窗口的一些基础扩展用法(增量聚合、触发器和双流join),将Markdown版讲义贴在下面。
Introducing Apache Flink - Part 3
Extended Usage of DataStream Windowing

Section A - Revision
Time Characteristics
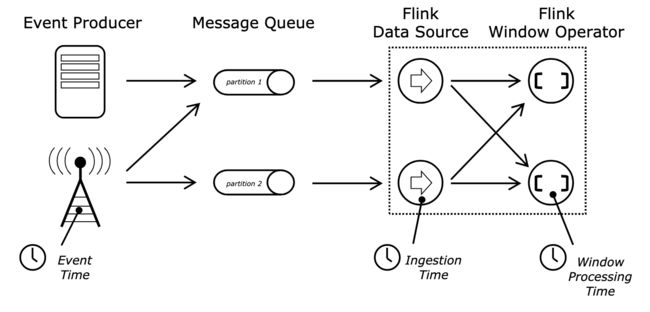
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setStreamTimeCharacteristic(TimeCharacteristic.ProcessingTime); // EventTime / IngestionTimeEvent Time & Watermarking

- A watermark containing timestamp T declares that all data with event time t <= T have arrived
DataStream watermarkedStream = recordStream
.assignTimestampsAndWatermarks( // AssignerWith[Periodic / Punctuated]Watermarks
// This provides a certain tolerance interval for out-of-ordering
new BoundedOutOfOrdernessTimestampExtractor(Time.seconds(10)) {
@Override
public long extractTimestamp(OrderDoneLogRecord element) {
return element.getTs();
}
}
); Windowing Basics
- Windows split the unbounded stream into bounded 'buckets' of finite size, over which users can apply computations
- 3 types [Tumbling / Sliding / Session] with 2 time characteristics [Processing time / Event time]
- Keyed windows are more common in real-world applications


KeyedStream siteKeyedStream = watermarkedStream
.keyBy("siteId", "siteName");
WindowedStream siteWindowedStream = siteKeyedStream
.window(SlidingEventTimeWindows.of(Time.seconds(10), Time.seconds(5))); Section B - Window Aggregation
- Aggregation is the most generalized use case for keyed stream windowing
- (e.g. Calculate buyer count & GMV grouping by sites)
- Core API:
WindowedStream.aggregate(AggregateFunction, WindowFunction)
AggregateFunction
- 3 type parameters:
-
IN(input data) -
ACC(accumulator) -
OUT(output result)
-
- 4 methods to implement:
createAccumulator()-
add()(adds an input record to the accumulator instance) getResult()-
merge()(merges two accumulator instances into one)
- Accumulator & result instances are both simple POJOs
@Getter
@Setter
public class BuyerAndGmvAccumulator {
private Set buyerIds;
private long gmv;
public BuyerAndGmvAccumulator() {
buyerIds = new HashSet<>();
gmv = 0;
}
public void addGmv(long gmv) { this.gmv += gmv; }
public void addBuyerId(long buyerId) { this.buyerIds.add(buyerId); }
public void addBuyerIds(Collection buyerIds) { this.buyerIds.addAll(buyerIds); }
}
@Getter
@Setter
@NoArgsConstructor
@ToString
public class BuyerAndGmvResult {
private long siteId;
private String siteName;
private long buyerCount;
private long gmv;
private long windowStartTs;
private long windowEndTs;
} - Let's fill in some blanks...
private static class BuyerAndGmvAggregateFunc
implements AggregateFunction {
@Override
public BuyerAndGmvAccumulator createAccumulator() {
return new BuyerAndGmvAccumulator();
}
@Override
public BuyerAndGmvAccumulator add(OrderDoneLogRecord record, BuyerAndGmvAccumulator acc) {
acc.addBuyerId(record.getUserId());
acc.addGmv(record.getQuantity() * record.getMerchandisePrice());
return acc;
}
@Override
public BuyerAndGmvResult getResult(BuyerAndGmvAccumulator acc) {
BuyerAndGmvResult result = new BuyerAndGmvResult();
result.setBuyerCount(acc.getBuyerIds().size());
result.setGmv(acc.getGmv());
return result;
}
@Override
public BuyerAndGmvAccumulator merge(BuyerAndGmvAccumulator acc1, BuyerAndGmvAccumulator acc2) {
acc1.addBuyerIds(acc2.getBuyerIds());
acc1.addGmv(acc2.getGmv());
return acc1;
}
} WindowFunction
- The result of AggregateFunction doesn't seem to have any 'metadata' about the window
- Calls for a WindowFunction, which needs 4 type parameters:
-
IN(input data) -
OUT(output result) -
KEY(type of key, depending on the KeySelector, mostly it is a Tuple) -
W(type of window, mostly it is a TimeWindow)
-
- Only 1 method
apply()to implement
private static class BuyerAndGmvResultWindowFunc
implements WindowFunction {
@Override
public void apply(
Tuple keys,
TimeWindow window,
Iterable agg,
Collector out
) throws Exception {
// Fetch the result produced by AggregateFunction above
BuyerAndGmvResult result = agg.iterator().next();
// Explicit conversions here
result.setSiteId(((Tuple2) keys).f0);
result.setSiteName(((Tuple2) keys).f1);
// Get window borders
result.setWindowStartTs(window.getStart() / 1000);
result.setWindowEndTs(window.getEnd() / 1000);
// Emit the 'true' result
out.collect(result);
}
} Do Aggregation
DataStream gmvResultStream = siteWindowedStream
.aggregate(new BuyerAndGmvAggregateFunc(), new BuyerAndGmvResultWindowFunc()); - Records flow into AggregateFunction and are computed incrementally, thus keeping the result instance only
- If we use WindowFunction alone, all records will be kept in memory until evaluation
- When the window fires, the result of AggregateFunction is provided to WindowFunction
- The result stream can be keyed or processed (e.g. with a ProcessFunction) afterwards
private static class GmvTopProcessFunc
extends KeyedProcessFunction {
private final int topN;
private PriorityQueue minHeap;
public GmvTopProcessFunc(int topN) {
this.topN = topN;
}
@Override
public void open(Configuration parameters) throws Exception {
super.open(parameters);
minHeap = new PriorityQueue<>(topN, Comparator.comparingLong(BuyerAndGmvResult::getGmv));
}
@Override
public void close() throws Exception {
minHeap.clear();
super.close();
}
@Override
public void processElement(BuyerAndGmvResult value, Context ctx, Collector out) throws Exception {
if (minHeap.size() < topN) {
minHeap.offer(value);
} else if (minHeap.peek().getGmv() >= value.getGmv()) {
minHeap.poll();
minHeap.offer(value);
}
ctx.timerService().registerEventTimeTimer(value.getWindowEndTs() + 1);
}
@Override
public void onTimer(long timestamp, OnTimerContext ctx, Collector out) throws Exception {
List ranking = new ArrayList<>();
for (int k = 0; k < topN && !minHeap.isEmpty(); k++) {
ranking.add(minHeap.poll());
}
Collections.reverse(ranking);
StringBuilder output = new StringBuilder();
output.append("-----------------\n");
for (BuyerAndGmvResult result : ranking) {
output.append(result.toString() + "\n");
}
output.append("-----------------\n");
out.collect(output.toString());
}
} - ProcessFunction involves function lifecycle, state & timers, thus won't be further discussed in this part
Section C - Window Trigger
Revisit Window Life Cycle

- By default, a window is evaluated when timestamp/watermark passes the end
- Trigger enables early-fire mechanism for (especially long) windows
- Call
trigger()method on WindowedStream, built-in & customization available
Built-in Triggers
-
ContinuousProcessingTimeTrigger/ContinuousEventTimeTrigger
- A trigger that continuously fires based on a given time interval (according to timestamps/watermarks)
siteIdWindowedStream.trigger(ContinuousEventTimeTrigger.of(Time.seconds(3)))
-
CountTrigger
- A trigger that fires once the count of elements in a window pane reaches a given limit
siteIdWindowedStream.trigger(CountTrigger.of(100))
-
DeltaTrigger
- A trigger that fires based on a DeltaFunction and a threshold
- The DeltaFunction calculates an offset between the data point which triggered last and the currently arrived data point...
- ...and will trigger if the offset is higher than the threshold, e.g.
siteIdWindowedStream.trigger(DeltaTrigger.of(
100.0, // Order ID offset threshold of 100
(oldPoint, newPoint) -> newPoint.getOrderId() - oldPoint.getOrderId(),
TypeInformation.of(OrderDoneLogRecord.class).createSerializer(env.getConfig())
));Customize Trigger
- TBD =。=
- Please refer to the official documentation for details
Section D - Window Joining
- Join operation exists in batching as well as streaming
- Windowing converts infinite data set to multiple blocks of finite data sets for joining
- Only equi-joins are available
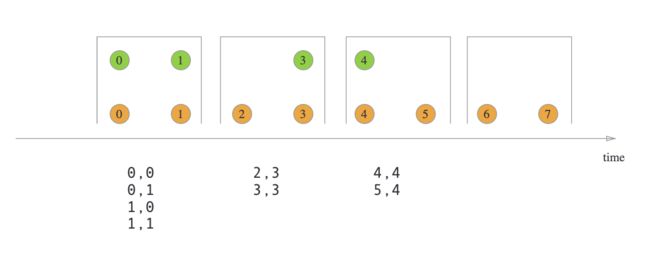
Inner Join
- With tumbling window
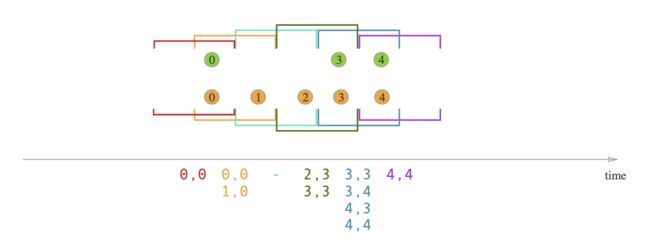
- With sliding window
- Using
join()API with JoinFunction
clickRecordStream
.join(orderRecordStream)
.where(record -> record.getMerchandiseId()) // key from left stream
.equalTo(record -> record.getMerchandiseId()) // key from right stream
.window(TumblingEventTimeWindows.of(Time.seconds(10)))
.apply(new JoinFunction() {
@Override
public String join(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord) throws Exception {
return StringUtils.join(Arrays.asList(
accessRecord.getMerchandiseId(),
orderRecord.getPrice(),
orderRecord.getCouponMoney(),
orderRecord.getRebateAmount()
), '\t');
}
}); Interval Inner Join
- The two streams may fall out of step regarding to event time
- Interval inner join allows relative time association
- i.e.
right.timestamp ∈ [left.timestamp + lowerBound, left.timestamp + upperBound]

- No need for explicit windowing, but using
intervalJoin()API and ProcessJoinFunction
clickRecordStream
.keyBy(record -> record.getMerchandiseId())
.intervalJoin(orderRecordStream.keyBy(record -> record.getMerchandiseId()))
.between(Time.seconds(-5), Time.seconds(15)) // lower & upper bounds
.process(new ProcessJoinFunction() {
@Override
public void processElement(AnalyticsAccessLogRecord accessRecord, OrderDoneLogRecord orderRecord, Context context, Collector collector) throws Exception {
collector.collect(StringUtils.join(Arrays.asList(
accessRecord.getMerchandiseId(),
orderRecord.getPrice(),
orderRecord.getCouponMoney(),
orderRecord.getRebateAmount()
), '\t'));
}
}); Left/Right Outer Join
- No native implementations, using
coGroup()as an alternative - Co-groups two data streams on a given key and a common window
- Illustrating left outer join logic as below
clickRecordStream
.coGroup(orderRecordStream)
.where(record -> record.getMerchandiseId()) // key from left stream
.equalTo(record -> record.getMerchandiseId()) // key from right stream
.window(TumblingProcessingTimeWindows.of(Time.seconds(10)))
.apply(new CoGroupFunction>() {
@Override
public void coGroup(Iterable accessRecords, Iterable orderRecords, Collector> collector) throws Exception {
for (AnalyticsAccessLogRecord accessRecord : accessRecords) {
boolean isMatched = false;
for (OrderDoneLogRecord orderRecord : orderRecords) {
collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), orderRecord.getPrice()));
isMatched = true;
}
if (!isMatched) {
collector.collect(new Tuple2<>(accessRecord.getMerchandiseName(), null));
}
}
}
}); - Naive nested-loop join --- Iterating through both streams & emitting equi-records
THE END
- To be followed: State & fault tolerance
- Keyed state & operator state
- Usage of managed states
- Checkpointing & state backends
- Checkpointing internals: Chandy-Lamport algorithm, ABS (Asynchronous Barrier Snapshotting) mechanism
