VAR变量(3)
经典案例
该部分内容,其实是变量替代 EARLIER(当前行),也就是构建DAX条件筛选时的模式例子:
(1)同比增长
先看一个大家都非常熟悉的求同比增长的经典模式:
还是以前面的包含三个表:产品表、销售表、时期表的数据模型举例。现在要计算每个产品的同比销售增长率。如果不使用VAR,我们的计算步骤:
第一步:元度量([销售]);
[销售] = SUM(Sales[销售额])
第二步:去年销售额(在[销售]度量里添加“上一年”的筛选器);
[上一年销售]= CALCULATE ([Sales],SAMEPERIODLASTYEAR(日期表[日期])
第三步:同比增长率(分别将第一步、第二步作为同比的分子分母);
[YoY%]=DIVIDE([销售]-[上一年销售] , [ 上一年销售])
像这种公式由多个步骤构建的情况,我们可以使用VAR语法,将每个步骤事先存储起来,然后作为公式引擎的引用数据。公式如下:
[YoY%]=
VAR Sale = SUM(Sales[销售额]) -- 存储一个值列表
VAR Sale_year= CALCULATE(Sale, SAMEPERIODLASTYEAR(日期表[日期])-- 存储一个上一年的计算结果列表;
RETURN -- 取出来定义的变量列表
DIVIDE(Sale , Sale_year) -- 将取出来的变量列表用于公式参于计算。
注意:因为变量不能使用中文字,以及避免与其他度量重名,这里的两个变量使用了与上例不同的名称。
本例中,我们先定义的第一个变量--Sale,用来替代原[销售]度量(同比中的分子表达式),然后定义第二个变量(同比中的分母),同时第二个变量引用了第一个变量。
两个变量定义完成后,相当于事先由存储引擎在内存中存储了这两个值,之后就通过RETURN后面的表达式,调用这两个值。例如,对于每个产品,都对应有两个存储数据(两个变量定义的值--这里是分子、分母计算式),分别用于由公式引擎请求执行的除法运算(行计算)。
通过这个例子可以看出,运用VAR变量语法,可以简化度量值的书写,并便于理解公式包含的逻辑步骤。并且,由于它是在公式执行计算前,就事先被存储的存储数据,即它完成运算以后,结果就可随时被公式引擎调用,而无需重新运算,从而大大提升了DAX的性能。这些在前面已经提到。
(2)累计类聚合计算
这类计算离不开EARLIER函数(当前行),EARLIER函数意思可理解为:存储引擎先将某个列存储为行列表,然后依据EARLIER 定义的“行”,从数据模型里请求引用对应的该列的行值(可理解为同一个列的列值引用,即当前行。可以理解EARLIER ()将某个列虚拟了一个该列的“分身”,以用于对比筛选,由于是分身,所以其基数总是少于原列的基数)。这也符合:“变量的实际是一个存储数据(内存虚拟数据),存在于公式引擎之前,并能被公式引用的数据”的定义。
我们已经知道,当变量被赋值后,即在被公式引用后的执行过程中,该值不会改变。基于此,先不管DAX内部是如何运行的,这时候EARLIER()更像一个常量(一个个被存储的列值),并作为DAX的行筛选条件。
例01:一个经典的求一列中基值对应的行值出现的次数(频次计算)
比如求两个订单时期之间的时间间隔:
计算条件:用下一个订单的日期减去当前订单的日期。当前订单的日期自然就是原表的订单时期列,为了定义相减,需要新建一列--[下次订单日期],即先把下一行的订单日期提取过来,我们输入该计算列的DAX公式:
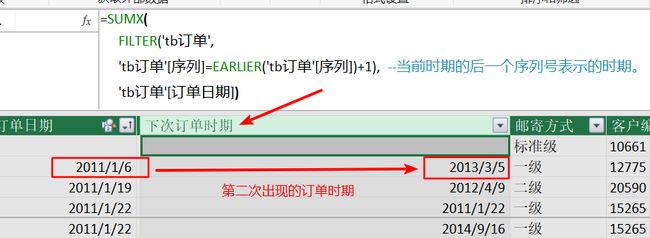
第一步:求当前时期的第二次出现的时期:(需要'tb订单表里有[序号]列)
= SUMX(FILTER('tb订单',
' tb订单'[序号]= EARLIER(' tb订单'[序号])+1),
' tb订单'[订单日期])
使用EARLIER(' tb订单'[序号])获取当前行的序号,然后找到当前序号+1(往后一个序号)的那一行的订单日期,即获得第二次(或下一次)订单时期;因为是直接引用' tb订单'[订单日期]的值,因此,将该列直接作为SUMX的第二参数:计算式,结果如下:
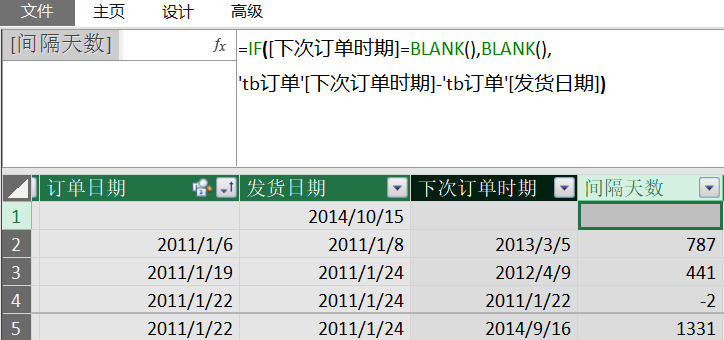
然后,新建一列,两列日期再相减,即得到两次订单时期间隔的天数:[间隔天数]列。
使用变量替代前面的公式(这时候,只需要一个计算列,即将中间过渡的计算列定义为了变量):

注意:既然上图公式里的Date01变量定义使用的是 ' tb订单'[订单日期] 列,那么,上图公式中加红色底线标识的部分:' tb订单'[订单日期] ,能不能也使用变量Date01替代?
事实上,如下图,它会得出一个错误的结果:全部值为零(空值),请思考这是为什么?
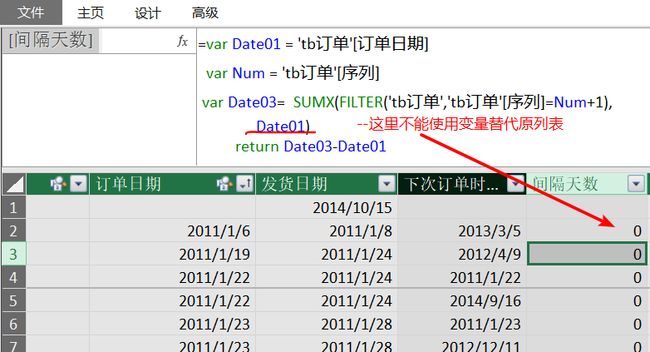
简单解释一下前面的问题:我们说过,变量被赋值之后,一般不会再变化,其实更像是“常量”,因而它可以用来定义行筛选条件。上例中的Date01变量位置,是SUMX的第二参数计算式,如果放置一个变量,其实相当于一个固定的存储数据(“常量”)被放在了计算式的位置,这是没有意义的。当然,上个公式中的Date01变量可以不用,即最后计算式改为:Date02 - ' tb订单'[订单日期] 。
例02:求每个订单日期、客户的累计销售金额
一个经典的计算累计销售的例子,用的是下面的DAX编写的新建列:
SUMX (FILTER('tb订单'[序列]<=EARLIER([序列])
&&'tb订单'[客户ID]=EARLIER('tb订单'[客户ID])),[销售])
使用VAR改写,返回同样的结果:
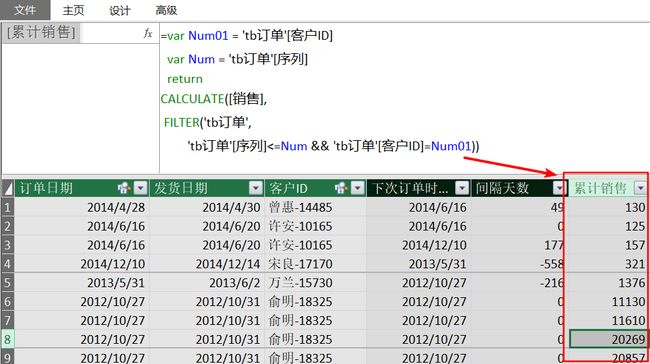
例03:求累计求和
将例02的多列变量模式改为针对某个计算列求累计聚合,例如帕累托累计求和的场景;

例04:求累计值的排名
这与例03中的累计求和的模式相同,只不过是将CALCULATE后面的计算式聚合函数改为使用COUNT(计数),而不是SUM(求和)。

例05:求移动时期段的度量计算
(如移动平均、前或后N天销售等)
只需将计算改为求平均,并给出当前行筛选定义:

有了累计值,可以求累计值占总值的百分比,再依据该累计占比值,定义ABC,这是典型的ABC之类的分组计算,这里从略。
通过以上几个实例,你已经了解到,这些DAX都具有使用变量来替代“当前行”,并作为行筛选的特点,我们将它总结成一个模式:
VAR V_1 = 列表、列值或函数计算式01
VAR V_2 = 列表、列值或函数计算式02
……
VAR V_N = 列表、列值或函数计算式N
RETURN
CALCULATE( 计算列表,
FILTER(ALL('被筛选表'),
'01>V_1 && 02<=V_2))
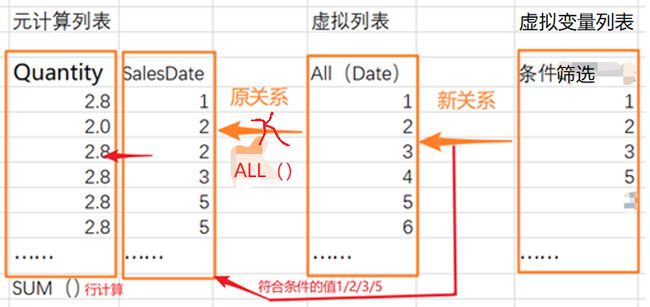
我们将上述公式用一个图简单说明一下该变量模式。

前面的几个公式都是在CALCULATE里构建一个由:FILTER(ALL( ), 条件筛选)) 模式定义的筛选器,它通过ALL( )先去掉该表原有的任何关系,这时,所有针对此表的筛选(因为没有关系)将不起作用(即删除了该表上的所有筛选器),然后,再添加新的、由变量与变量所在列(如列=以该列定义的变量,这里的=号可以是其他操作符)构建的条件筛选。如果你理解不了,那就记住该模式就好。
这与之前在说ALL()函数时,曾提到一个图一样。把条件改一下即可:
本部分提供公式案例文件,需要的请到QQ群:490799485 Power BI 非官方群文件里下载。
未完待续