kaggle实例学习-Titanic(1)
比赛地址:https://www.kaggle.com/c/titanic/data?train.csv
部分内容来源于(尤其是代码)http://blog.csdn.net/han_xiaoyang/article/details/49797143
import pandas as pd
import numpy as np
from pandas import Series,DataFrame
data_train=pd.read_csv("F:/Machine Learning/kaggle/Titanic/train.csv")
data_train结果如下:
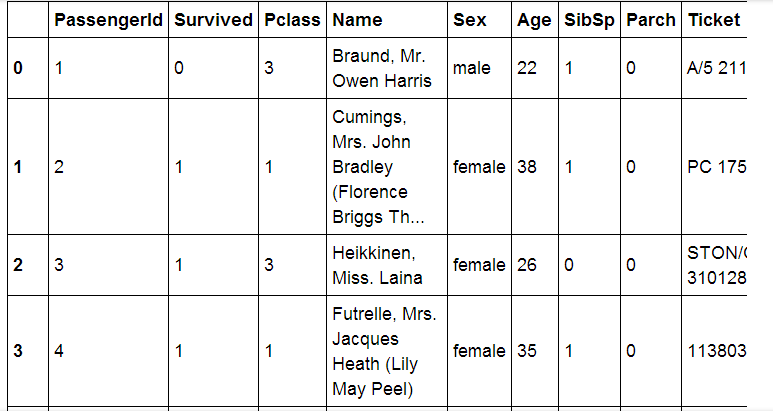
data_train.info()#Dataframe 的info方法可以显示数据的主要信息data_train.describe()
对数据了解又多了一点了
接下来对数据进行可视化:
import matplotlib.pyplot as plt
fig=plt.figure()
fig.set(alpha=0.2)#设定图表颜色
fig.set_size_inches(18.5, 10.5)
plt.subplot2grid((2,3),(0,0))#画几个镶嵌的小图
data_train.Survived.value_counts().plot(kind='bar')#将Survived画成柱状图
plt.title(u"rescue")
plt.ylabel(u"numbers")
plt.subplot2grid((2,3),(0,1))#同样对Pclass进行处理
data_train.Pclass.value_counts().plot(kind='bar')
plt.title(u"Pclass distribution")
plt.ylabel(u"numbers")
plt.subplot2grid((2,3),(0,2))#查看Survived与Age的关系
plt.scatter(data_train.Survived,data_train.Age)
plt.grid(b=True,which='major',axis='y')
plt.title(u"Age and rescue")
plt.ylabel(u"Age")
plt.subplot2grid((2,3),(1,0),colspan=2)
data_train.Age[data_train.Pclass==1].plot(kind='kde')
data_train.Age[data_train.Pclass==2].plot(kind='kde')
data_train.Age[data_train.Pclass==3].plot(kind='kde')
plt.xlabel(u"Age")
plt.ylabel(u"density")
plt.title(u"Pclass and Age distribution")
plt.legend((u'first class',u'second class',u'third class'),loc='best')
plt.subplot2grid((2,3),(1,2))#对Embarked进行处理
data_train.Embarked.value_counts().plot(kind='bar')
plt.title(u"numbers of rescued on land")
plt.ylabel(u"numbers")
plt.show()
效果图:
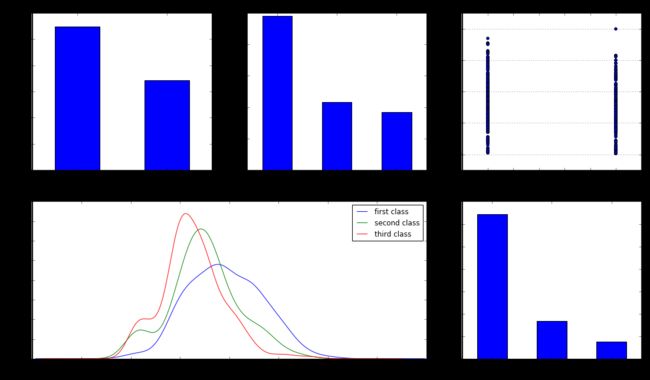
下面来看看乘客的等级和获救情况是否有关:
fig=plt.figure()
fig.set(alpha=0.2)
Survived_0=data_train.Pclass[data_train.Survived==0].value_counts()
Survived_1=data_train.Pclass[data_train.Survived==1].value_counts()
df=pd.DataFrame({u'rescued':Survived_1,u'unrescued':Survived_0})
df.plot(kind='bar',stacked=True)
plt.title(u"Pclass and the rescued distribution")
plt.xlabel(u"Pclass")
plt.ylabel(u"numbers")
plt.show()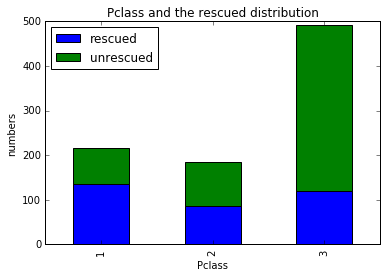
确实有关系,明显Pclass==3的未获救的更多。
同样地,看看性别对获救情况的影响:
fig=plt.figure()
fig.set(alpha=0.2)
Survived_male=data_train.Survived[data_train.Sex=='male'].value_counts()
Survived_female=data_train.Survived[data_train.Sex=='female'].value_counts()
df=pd.DataFrame({u'Survived male':Survived_male,u'Survived female':Survived_female})
df.plot(kind='bar',stacked=True)
plt.title(u"gender and rescue")
plt.xlabel(u"gender")
plt.ylabel(u"numbers")
plt.show()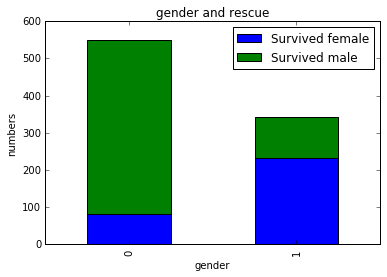
可以看出,女性的获救人数明显多于男性。
下面做一个综合一点的图表:
fig=plt.figure()
fig.set(alpha=0.45)
plt.title(u"Pclass,gender and Survive")
fig.set_size_inches(16.5, 8.5)
ax1=fig.add_subplot(141)
data_train.Survived[data_train.Sex=='female'][data_train.Pclass!=3].value_counts().p\
lot(kind='bar',label='female,high class',color='#FA2479')
ax1.set_xticklabels([u"unsurvived",u"survived"],rotation=0)
ax1.legend([u"female/Pclass3"],loc='best')
ax2=fig.add_subplot(142)
data_train.Survived[data_train.Sex=='female'][data_train.Pclass==3].value_counts().p\
lot(kind='bar',label='female,lower class',color='#FA2479')
ax2.set_xticklabels([u"unsurvived",u"survived"],rotation=0)
ax2.legend([u"female/Pclass"],loc='best')
ax3=fig.add_subplot(143,sharey=ax1)
data_train.Survived[data_train.Sex=='male'][data_train.Pclass!=3].value_counts().p\
lot(kind='bar',label='male,high class',color='lightblue')
ax3.set_xticklabels([u"unsurvived",u"survived"],rotation=0)
ax3.legend([u"male/Pclass3"],loc='best')
ax4=fig.add_subplot(144,sharey=ax1)
data_train.Survived[data_train.Sex=='male'][data_train.Pclass==3].value_counts().p\
lot(kind='bar',label='male,low class',color='lightblue')
ax4.set_xticklabels([u"unsurvived",u"survived"],rotation=0)
ax4.legend([u"male/Pclass"],loc='best')
效果图
接下来检查Cabin属性:
data_train.Cabin.value_counts()C23 C25 C27 4
B96 B98 4
G6 4
E101 3
C22 C26 3
F2 3
D 3
F33 3
C124 2
C65 2
C93 2
D20 2
C83 2
B35 2
D35 2
B77 2
E33 2
D33 2
E121 2
B28 2
B51 B53 B55 2
D26 2
E25 2
B58 B60 2
C2 2
E24 2
C126 2
C68 2
D17 2
D36 2
..
D49 1
E31 1
A34 1
C70 1
C45 1
C104 1
C7 1
D9 1
C110 1
C50 1
B4 1
C46 1
D30 1
A6 1
D21 1
E34 1
D7 1
B71 1
T 1
B38 1
C111 1
E50 1
B69 1
A36 1
B79 1
D45 1
A10 1
A32 1
C49 1
C103 1
Name: Cabin, dtype: int64
数据代表的具体意义不是很清楚,来看看对Survive是否有影响
fig=plt.figure()
fig.set(alpha=0.2)
Survived_cabin=data_train.Survived[pd.notnull(data_train.Cabin)].value_counts()
Survived_nocabin=data_train.Survived[pd.isnull(data_train.Cabin)].value_counts()
df=pd.DataFrame({u'isCabin':Survived_cabin,u'noCabin':Survived_nocabin}).transpose()
df.plot(kind='bar',stacked=True)
plt.title(u'Cabin and Survived')
plt.xlabel(u"Cabin")
plt.ylabel(u"numbers")
plt.show()结果如下:

对数据的大体情况就了解到这里