大数据组件及其环境搭建
说明:该搭建文档是实践流程,是我当初刚入门时的安装文档,如果想快速搭建环境/快速开时业务开发,可以参考。不过现在很多公司要么直接购买大数据组件云服务,要么基于ambera等搭建/管理大数据集群环境,要么基于k8s、rancher等基于容器技术实现大数据集群环境。
这里只发布了部分大数据组件的部署安装流程,后面还有不定期更新 spark、flink、flume、redis、mongo、ambera等的搭建流程以及相关的java版本接入教程。
另:该文档没有经过精心排版和校正,可能存在部分语法、错别字错误等,请大家留言指正。
CDH各软件下载地址
http://archive.cloudera.com/cdh5/cdh/5/
http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/hadoop-2.6.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/hbase-1.2.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/hive-1.1.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/hue-3.9.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/kite-1.0.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/mahout-0.9-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/oozie-4.1.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/pig-0.12.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/solr-4.10.3-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/sqoop2-1.99.5-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/whirr-0.9.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/zookeeper-3.4.5-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/avro-1.7.6-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/bigtop-jsvc-1.0.10-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/bigtop-tomcat-6.0.45-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/crunch-0.11.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/datafu-1.1.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/flume-ng-1.6.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/hbase-solr-1.5-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/llama-1.0.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-1.5.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-format-2.1.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/spark-1.6.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/sentry-1.5.1-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-1.5.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-1.5.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-1.5.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-1.5.0-cdh5.9.3.tar.gz
http://archive.cloudera.com/cdh5/cdh/5/parquet-1.5.0-cdh5.9.3.tar.gz
Hadoop
企业级版本:Hadoop在大数据领域的应用前景很大,不过因为是开源技术,实际应用过程中存在很多问题。于是出现了各种Hadoop发行版,国外目前主要是三家创业公司在做这项业务:Cloudera、Hortonworks和MapR
CDH:全称Cloudera’s Distribution Including Apache Hadoop ( CDH版本衍化 )
hadoop是一个开源项目,所以很多公司在这个基础进行商业化,Cloudera对hadoop做了相应的改变。loudera公司的发行版,我们将该版本称为CDH(Cloudera Distribution
Hadoop)。截至目前为止,CDH共有5个版本,其中,前两个已经不再更新,最近的两个,分别是CDH4,在Apache Hadoop 2.0.0版本基础上演化而来的,CDH5,它们每隔一段时间便会更新一次。
安装
(备注:以下hadoop安装教程在3.1.2版本下验证无误,启动hadoop钱先启动zookeeper)
前置要求:java8以上版本 尽量开启SSH免密登录
查看openjdk安装路径:
which java
ls -lrt /usr/bin/java
ls -lrt /etc/alternatives/java
卸载自带openJDK:
rpm -qa | grep jdk
yum -y remove java-1.8.0-openjdk-headless-1.8.0.161-0.b14.el7_4.x86_64s
http://www.mamicode.com/info-detail-1683752.html
http://blog.csdn.net/woshisunxiangfu/article/details/44026207
为了方便集群,先使主机名和IP映射,host文件;(hosts 文件不用执行source /etc/hosts 生效,因为他就不是执行脚本)
对于hdfs非HA模式,hadoop不依赖zookeeper,但如果想实现hdfs的HA(namenode的HA),还是需要zookeeper的;
先在一台机器上执行以下操作,然后scp将hadoop目录copy到其他机器上;
解压
建立目录 :在hadoop根目录下,建立tmp、hdfs/name、hdfs/data目录
修改配置文件:共需要配置/opt/hadoop/hadoop-3.1.2/etc/hadoop/下的六个个文件,分别是
hadoop-env.sh、core-site.xml、hdfs-site.xml、yarn-site.xml、mapred-site.xml、workers
hadoop-env.sh
export JAVA_HOME=/opt/java/jdk1.8.0_172/
export HDFS_NAMENODE_USER="root"
export HDFS_DATANODE_USER="root"
export HDFS_SECONDARYNAMENODE_USER="root"
export YARN_RESOURCEMANAGER_USER="root"
export YARN_NODEMANAGER_USER="root"
yarn-site.xml
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
Workers
修改 ./etc/hadoop/workers指定集群机器的主机名;
whf128
whf129
whf130
配置环境变量
vim /etc/profile
export Hadoop_home=
export PATH=$ZOOKEEPER_HOME/bin:$HADOOP_HOME/bin:$PATH
scp -r /opt/Hadoop-2.8.4 [email protected]:/opt
启动:
择机启动一台机器,集群即可启动;
1) 格式化namenode: $ ./bin/hdfs namenode -format (注意是bin目录)
2)启动NameNode 和 DataNode 守护进程: $ ./sbin/start-dfs.sh (sbin目录)
3)启动ResourceManager 和 NodeManager 守护进程: $ ./sbin/start-yarn.sh (sbin目录)
注意事项:
Hadoop dfs ---命令不推荐使用, 而是推荐用hdfs。对于hdfs的操作,如果在主机上操作,可以不用写全路径,如 : >hdfs dfs –ls ‘hdfs://192.168.116.128:9000/tmp’ #这里是全路径
还有sbin/start-all.sh stop-all.sh也不推荐使用,而是推荐使用start-dfs.sh 和start-yarn.sh ;
在上面hadoop安装时,对于配置文件的修改,以一台机器的参数为主:不能是:test-hadoop1节点机器是一个参数,test-hadoop2节点机器是另一个参数;
验证
jps (正常情况下,启动以下5个进程)
5717 SecondaryNameNode
5481 NameNode
5580 DataNode
5884 ResourceManager
5980 NodeManager
对于node01节点
对于node02节点:
对于node03节点:
向hdfs写入数据
[hadoop@bgs-5p173-wangwenting hadoop-2.8.3]$ hdfs dfs -help
Usage: hadoop fs [generic options]
[-appendToFile
[-cat [-ignoreCrc]
[-checksum
[-chgrp [-R] GROUP PATH...]
[-chmod [-R]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] [-l] [-d]
[-copyToLocal [-f] [-p] [-ignoreCrc] [-crc]
[-count [-q] [-h] [-v] [-t [
[-cp [-f] [-p | -p[topax]] [-d]
[-createSnapshot
[-deleteSnapshot
[-df [-h] [
[-du [-s] [-h] [-x]
[-expunge]
[-find
[-get [-f] [-p] [-ignoreCrc] [-crc]
[-getfacl [-R]
[-getfattr [-R] {-n name | -d} [-e en]
[-getmerge [-nl] [-skip-empty-file]
[-help [cmd ...]]
[-ls [-C] [-d] [-h] [-q] [-R] [-t] [-S] [-r] [-u] [
[-mkdir [-p]
[-moveFromLocal
[-moveToLocal
[-mv
[-put [-f] [-p] [-l] [-d]
[-renameSnapshot
[-rm [-f] [-r|-R] [-skipTrash] [-safely]
[-rmdir [--ignore-fail-on-non-empty]
[-setfacl [-R] [{-b|-k} {-m|-x
[-setfattr {-n name [-v value] | -x name}
[-setrep [-R] [-w]
[-stat [format]
[-tail [-f]
[-test -[defsz]
[-text [-ignoreCrc]
[-touchz
[-truncate [-w]
[-usage [cmd ...]]
Yarn
| resourceManager |
分配任务 |
| Nodemanager |
领取/执行任务;resourceManahger在每台机器上的代理,负责容器管理,并监控他们的资源使用情况。以及向resourceManahger报告他们的资源使用报告,内存,CPU生命周期管理 |
| Namenode |
存储hdfs元数据信息matadata |
| Datanode |
数据存储节点 1.0默认块大小128M,hadoop2.0默认块大小256M |
| Secondarynamenode |
用来合并fsimage和edits文件来更新namenode的matadata |
| Fsimage |
元数据镜像文件。 |
| Secondarynamenode |
Hadoop负责维护fsimage,但是fsimage不会随时与namenode内存中的matadata一致,而是每隔一段时间合并edits文件来更新内容,secondarynamenode就是用来合并fsimage和edits文件来更新namenode的matadata |
| Edits |
操作日志文件 |
| Fstime |
保存最近一次checkpoint的时间(还原点) |
| Container |
是Yarn对计算机计算资源的抽象,它其实就是一组CPU和内存资源,所有的应用都会运行在Container中。 |
| ApplicationMaster |
是Yarn对计算机计算资源的抽象,它其实就是一组CPU和内存资源,所有的应用都会运行在Container中。 |
| Scheduler |
ResourceManager专门进行资源管理的一个组件,负责分配NodeManager上的Container资源, |
在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的 ``mapred-site.xml`` 配置。
老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsManager,它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
各个服务作用
.hadoop有三个主要的核心组件:
HDFS(分布式文件存储)、
MAPREDUCE(分布式的计算)、
YARN(资源调度)
五个后台进程:
resourcemanager
namenode
secondarynamenode
datanode
nodemanager
其中:
namenode 、resourcemanager运行在主节点上
nodemanager运行在在从节点上
datanode在所有节点上都运行
每个集群都有一个secondarynamenode和namenode
对于jobtrack和tasktrack (map task reduce task)是mapreduce里的概念,在MRv2版本的yarn里不存在这个概念了;
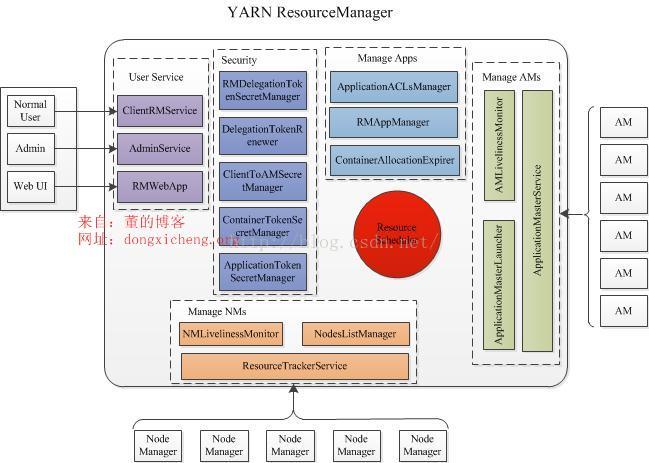
Resourcemanager
ResourceManage 即资源管理,在YARN中,ResourceManager负责集群中所有资源的统一管理和分配,它接收来自各个节点(NodeManager)的资源汇报信息,并把这些信息按照一定的策略分配给各个应用程序(实际上是ApplicationManager)。
RM包括Scheduler(定时调度器)和ApplicationManager(应用管理器)。Schedular负责向应用程序分配资源,它不做监控以及应用程序的状态跟踪,并且不保证会重启应用程序本身或者硬件出错而执行失败的应用程序。ApplicationManager负责接受新的任务,协调并提供在ApplicationMaster容器失败时的重启功能。
nodemanager
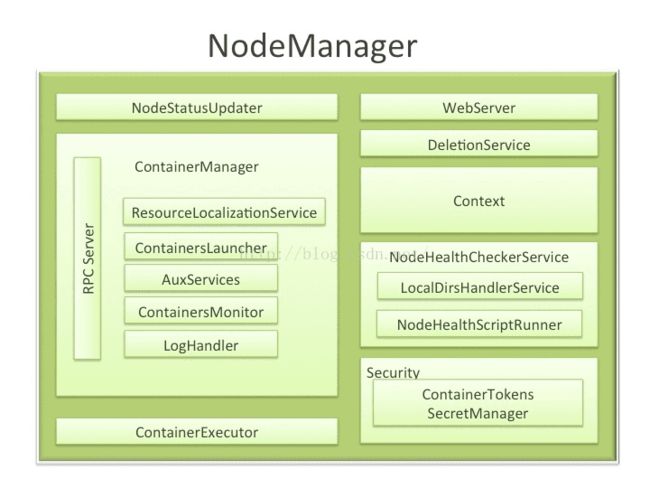
NM是ResourceManager在每台机器上的代理,负责容器管理,并监控它们的资源使用情况,以及向ResourceManager/Scheduler提供资源使用报告
它是YARN中每个节点上的代理,它管理Hadoop集群中单个计算节点,包括与ResourceManger保持通信,监督Container的生命周期管理,监控每个Container的资源使用(内存、CPU等)情况,追踪节点健康状况,管理日志和不同应用程序用到的附属服务(auxiliary service)。
namenode
Namenode 管理者文件系统的Namespace。它维护着文件系统树(filesystem tree)以及文件树中所有的文件和文件夹的元数据(metadata)。管理这些信息的文件有两个,分别是Namespace 镜像文件(Namespace image)和操作日志文件(edit log),这些信息被Cache在RAM中,当然,这两个文件也会被持久化存储在本地硬盘。Namenode记录着每个文件中各个块所在的数据节点的位置信息,但是他并不持久化存储这些信息,因为这些信息会在系统启动时从数据节点重建。
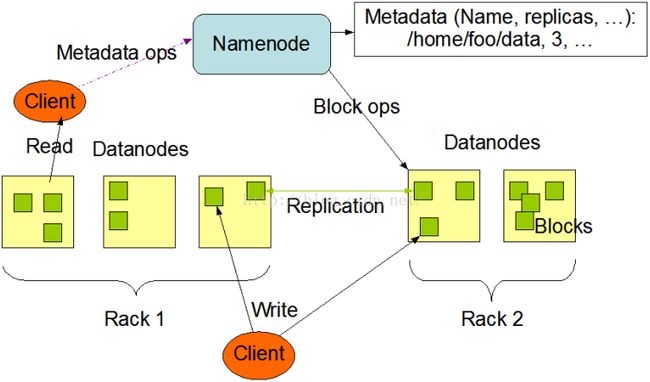
Namenode容错机制
没有Namenode,HDFS就不能工作。事实上,如果运行namenode的机器坏掉的话,系统中的文件将会完全丢失,因为没有其他方法能够将位于不同datanode上的文件块(blocks)重建文件。因此,namenode的容错机制非常重要,Hadoop提供了两种机制。
第一种方式是将持久化存储在本地硬盘的文件系统元数据备份。Hadoop可以通过配置来让Namenode将他的持久化状态文件写到不同的文件系统中。这种写操作是同步并且是原子化的。比较常见的配置是在将持久化状态写到本地硬盘的同时,也写入到一个远程挂载的网络文件系统。
第二种方式是运行一个辅助的Namenode(Secondary Namenode)。 事实上Secondary Namenode并不能被用作Namenode它的主要作用是定期的将Namespace镜像与操作日志文件(edit log)合并,以防止操作日志文件(edit log)变得过大。通常,Secondary Namenode 运行在一个单独的物理机上,因为合并操作需要占用大量的CPU时间以及和Namenode相当的内存。辅助Namenode保存着合并后的Namespace镜像的一个备份,万一哪天Namenode宕机了,这个备份就可以用上了。
但是辅助Namenode总是落后于主Namenode,所以在Namenode宕机时,数据丢失是不可避免的。在这种情况下,一般的,要结合第一种方式中提到的远程挂载的网络文件系统(NFS)中的Namenode的元数据文件来使用,把NFS中的Namenode元数据文件,拷贝到辅助Namenode,并把辅助Namenode作为主Namenode来运行。
当然在hadoop 2.x 中,已经有了新的解决方案,那就是NameNode HA(因为Hadoop还包括 ResourceManage HA),hadoop联邦, Hadoop HA是指同时启动两个NameNode,一个处于工作状态,另外一个处于随时待命状态,这样在处于工作状态的NameNode所在的服务器宕机时,可在数据不丢失的情况下,手工或者自动切换到另外一个NameNode提供服务。
secondaryNamenode
Secondary NameNode是一个用来监控HDFS状态的辅助后台程序。就想NameNode一样,每个集群都有一个Secondary NameNode,并且部署在一个单独的服务器上。Secondary NameNode不同于NameNode,它不接受或者记录任何实时的数据变化,但是,它会与NameNode进行通信,以便定期地保存HDFS元数据的 快照。由于NameNode是单点的,通过Secondary NameNode的快照功能,可以将NameNode的宕机时间和数据损失降低到最小。同时,如果NameNode发生问题,Secondary NameNode可以及时地作为备用NameNode使用。
辅助NameNode,分担其工作量;定期合并fsimage和fsedits,推送给NameNode;紧急情况下,可辅助恢复NameNode,但Secondary NameNode并非NameNode的热备。
datanode
Datanode是文件系统的工作节点,他们根据客户端或者是namenode的调度存储和检索数据,并且定期向namenode发送他们所存储的块(block)的列表。
集群中的每个服务器都运行一个DataNode后台程序,这个后台程序负责把HDFS数据块读写到本地的文件系统。当需要通过客户端读/写某个 数据时,先由NameNode告诉客户端去哪个DataNode进行具体的读/写操作,然后,客户端直接与这个DataNode服务器上的后台程序进行通 信,并且对相关的数据块进行读/写操作。
hdfs的HA
hdfs命令
- 文件列表:hdfs dfs –ls [目录]
- 创建目录: hdfs dfs –mkdir [文件夹目录]
- 上传文件:hdfs dfs –put [本地目录] [HDFS文件目录]
- 下载文件: hdfs dfs –get [文件目录]
- 查看文件:hdfs dfs –cat [文件目录]
- 注:HDFS目录可以是绝对目录,如‘hdfs://
: /’,也可以是相对目录(相对HDFS文件系统),如‘ /’代表根目录
Mapreduce / yarn
mapreduce
- 一个用来编写处理并行分布式数据程序的框架
- 基于主/从模式架构
- 由一个单独的MRAppMaster (JobTracker) 和多个Task(slaveTaskTracker)共同组成
- MRAppMaster负责调度构成一个作业的所有任务,这些任务分布在不同的nodemanager上, MRAppMaster监控它们的执行,重新执行已经失败的任务。而nodemanager仅负责执行由MRAppMaster指派的任务
JobTracker后台程序用来连接应用程序与Hadoop。用户代码提交到集群以后,由JobTracker决定哪个文件将被处理,并且为 不同的task分配节点。同时,它还监控所有的task,一旦某个task失败了,JobTracker就会自动重新开启这个task,在大多数情况下这 个task会被放在不用的节点上。每个Hadoop集群只有一个JobTracker,一般运行在集群的Master节点上。
Yarn
Hadoop2.0对MapReduce框架做了彻底的设计重构,我们称Hadoop2.0中的MapReduce为MRv2或者YARN(Yet Another Resource Negotiator,另一种资源协调者)
Yarn拓展了Hadoop,使得它不仅仅可以支持MapReduce计算,还能很方便的管理诸如Hive、Hbase、Pig、Spark/Shark等应用。这种新的架构设计能够使得各种类型的应用运行在Hadoop上面,并通过Yarn从系统层面进行统一的管理
- ResourceManager
- 处理客户端请求
- 启动/监控ApplicationMaster
- 监控NodeManager
- 资源分配与调度
- NodeManager
- 单个节点上的资源管理
- 处理来自ResourceManager的命令
- 处理来自ApplicationMaster的命令
- ApplicationMaster(以MRAppMaster为例)
- 数据切分
- 为应用程序向ResourceManager申请资源
- 与NodeManager通信以启动Container
- 任务监控与容错
Yarn由以下组件构成
ResourceManager:Global(全局)的进程
NodeManager:运行在每个节点上的进程
ApplicationMaster:Application-specific(应用级别)的进程
- *Scheduler:是ResourceManager的一个组件*
- *Container:节点上一组CPU和内存资源*
Container是Yarn对计算机计算资源的抽象,它其实就是一组CPU和内存资源,所有的应用都会运行在Container中。ApplicationMaster是对运行在Yarn中某个应用的抽象,它其实就是某个类型应用的实例,ApplicationMaster是应用级别的,它的主要功能就是向ResourceManager(全局的)申请计算资源(Containers)并且和NodeManager交互来执行和监控具体的task。Scheduler是ResourceManager专门进行资源管理的一个组件,负责分配NodeManager上的Container资源,NodeManager也会不断发送自己Container使用情况给ResourceManager。
ResourceManager和NodeManager两个进程主要负责系统管理方面的任务。ResourceManager有一个Scheduler,负责各个集群中应用的资源分配。对于每种类型的每个应用,都会对应一个ApplicationMaster实例,ApplicationMaster通过和ResourceManager沟通获得Container资源来运行具体的job,并跟踪这个job的运行状态、监控运行进度。
http://www.cnblogs.com/edisonchou/p/4298423.html
该链接讲解很详细,多看几遍
Hadoop的shuffle过程就是从map端输出到reduce端输入之间的过程,这一段应该是Hadoop中最核心的部分,因为涉及到Hadoop中最珍贵的网络资源,所以shuffle过程中会有很多可以调节的参数,也有很多策略可以研究
(1)在map端首先接触的是InputSplit,在InputSplit中含有DataNode中的数据,每一个InputSplit都会分配一个Mapper任务,Mapper任务结束后产生
(2)写磁盘前,要进行partition、sort和combine等操作。通过分区,将不同类型的数据分开处理,之后对不同分区的数据进行排序,如果有Combiner,还要对排序后的数据进行combine。等最后记录写完,将全部溢出文件合并为一个分区且排序的文件。
(3)最后将磁盘中的数据送到Reduce中,从图中可以看出Map输出有三个分区,有一个分区数据被送到图示的Reduce任务中,剩下的两个分区被送到其他Reducer任务中。而图示的Reducer任务的其他的三个输入则来自其他节点的Map输出。
Hadoop的几个端口
Hadoop 的 W eb 管理主要分为两块,一块是对文件系统的监控,一块是对任务的监控。
文件系统监控:
- namenode 的日志列表以及查看日志;
- 集群的概况,包括配置容量、 DFS 占用容量、非 DFS 占用容量、 DFS 的可使用容量、 DFS 已使用百分比、 DFS 可使用百分比、活结点数、死节点数、 namenode 的存储目录及类型和状态;
- 点击活节点或者死节点数可以看到所有对应节点的类表,以及他们的节点名称, Last Contact 的值( Last Contact 的意思是表明 DataNode 有多少秒时间未向 NameNode 发送心跳包了),管理状态,配置容量,已使用容量,非 DFS 使用容量,剩余容量,已使用百分比,已使用的进度条,剩余百分比,块数。
任务监控:
-
- 集群摘要信息(堆的大小,所占的比例), Map 任务数, Reduce 任务数,共有意见书,节点数量, Map 任务能力, Reduce 任务能力,平均任务和节点(这点我不明白什么意思,原文: Avg. Task/Node ),列入黑名单的节点;
- 调度信息:队列名称,调度信息;
- 过滤查询:可根据 Jobid ,优先级,用户名等信息查询任务;
- 可以查看正在运行,已经完成或者执行失败的 Job 的信息:状态,完成所需时间,该 Job 的 map 和 reduce信息:完成进度,总任务数,待完成任务数,正在执行的,已完成的,死掉的,失败的和死掉的个数比(按照我的理解应该是失败后并再次尝试并成功的与死掉的个数比);
Map/Reduce管理端口50030
HDFS文件管理系统 50070
ResourceManager的http服务接口 8088 运行在主节点master上,可以Web控制台查看状态
这里介绍8088的来源,yarn-site.xml中的属性:
NodeManager管理端口8042
运行在从节点上,可以通过Web控制台查看对应节点的资源状态
组件 :YARN
节点 :NodeManager
默认端口:8042
配置 :yarn.nodemanager.webapp.address
JobHistory Server管理端口19888
还有各种数据的统计包括 Job 、 FileSystem 、 Map-Reduce Framework ,统计具体小点太多还是上图 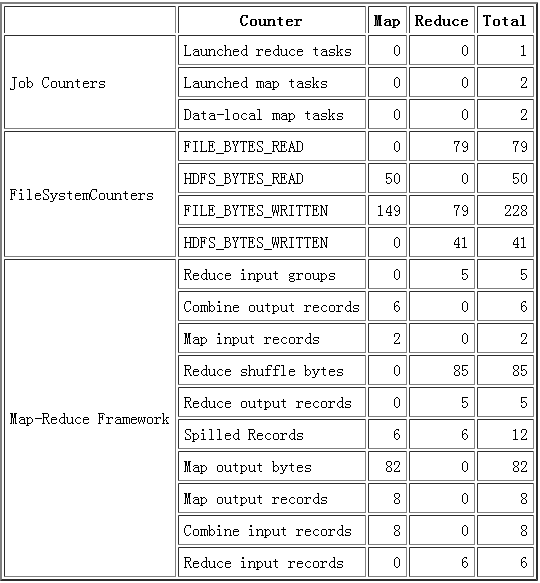
hadoop生态组件的端口
Hadoop集群的各部分一般都会使用到多个端口,有些是daemon之间进行交互之用,有些是用于RPC访问以及HTTP访问。而随着Hadoop周边组件的增多,完全记不住哪个端口对应哪个应用,特收集记录如此,以便查询。这里包含我们使用到的组件:HDFS, YARN, HBase, Hive, ZooKeeper:
| 组件 |
节点 |
默认端口 |
配置 |
用途说明 |
| HDFS |
DataNode |
50010 |
dfs.datanode.address |
datanode服务端口,用于数据传输 |
| HDFS |
DataNode |
50075 |
dfs.datanode.http.address |
http服务的端口 |
| HDFS |
DataNode |
50475 |
dfs.datanode.https.address |
https服务的端口 |
| HDFS |
DataNode |
50020 |
dfs.datanode.ipc.address |
ipc服务的端口 |
| HDFS |
NameNode |
50070 |
dfs.namenode.http-address |
http服务的端口 |
| HDFS |
NameNode |
50470 |
dfs.namenode.https-address |
https服务的端口 |
| HDFS |
NameNode |
8020 |
fs.defaultFS |
接收Client连接的RPC端口,用于获取文件系统metadata信息。 |
| HDFS |
journalnode |
8485 |
dfs.journalnode.rpc-address |
RPC服务 |
| HDFS |
journalnode |
8480 |
dfs.journalnode.http-address |
HTTP服务 |
| HDFS |
ZKFC |
8019 |
dfs.ha.zkfc.port |
ZooKeeper FailoverController,用于NN HA |
| YARN |
ResourceManager |
8032 |
yarn.resourcemanager.address |
RM的applications manager(ASM)端口 |
| YARN |
ResourceManager |
8030 |
yarn.resourcemanager.scheduler.address |
scheduler组件的IPC端口 |
| YARN |
ResourceManager |
8031 |
yarn.resourcemanager.resource-tracker.address |
IPC |
| YARN |
ResourceManager |
8033 |
yarn.resourcemanager.admin.address |
IPC |
| YARN |
ResourceManager |
8088 |
yarn.resourcemanager.webapp.address |
http服务端口 |
| YARN |
NodeManager |
8040 |
yarn.nodemanager.localizer.address |
localizer IPC |
| YARN |
NodeManager |
8042 |
yarn.nodemanager.webapp.address |
http服务端口 |
| YARN |
NodeManager |
8041 |
yarn.nodemanager.address |
NM中container manager的端口 |
| YARN |
JobHistory Server |
10020 |
mapreduce.jobhistory.address |
IPC |
| YARN |
JobHistory Server |
19888 |
mapreduce.jobhistory.webapp.address |
http服务端口 |
| HBase |
Master |
60000 |
hbase.master.port |
IPC |
| HBase |
Master |
60010 |
hbase.master.info.port |
http服务端口 |
| HBase |
RegionServer |
60020 |
hbase.regionserver.port |
IPC |
| HBase |
RegionServer |
60030 |
hbase.regionserver.info.port |
http服务端口 |
| HBase |
HQuorumPeer |
2181 |
hbase.zookeeper.property.clientPort |
HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase |
HQuorumPeer |
2888 |
hbase.zookeeper.peerport |
HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| HBase |
HQuorumPeer |
3888 |
hbase.zookeeper.leaderport |
HBase-managed ZK mode,使用独立的ZooKeeper集群则不会启用该端口。 |
| Hive |
Metastore |
9083 |
/etc/default/hive-metastore中export PORT= |
|
| Hive |
HiveServer |
10000 |
/etc/hive/conf/hive-env.sh中export HIVE_SERVER2_THRIFT_PORT= |
|
| ZooKeeper |
Server |
2181 |
/etc/zookeeper/conf/zoo.cfg中clientPort= |
对客户端提供服务的端口 |
| ZooKeeper |
Server |
2888 |
/etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 |
follower用来连接到leader,只在leader上监听该端口。 |
| ZooKeeper |
Server |
3888 |
/etc/zookeeper/conf/zoo.cfg中server.x=[hostname]:nnnnn[:nnnnn],标蓝部分 |
用于leader选举的。只在electionAlg是1,2或3(默认)时需要。 |
所有端口协议均基于TCP。
对于存在Web UI(HTTP服务)的所有hadoop daemon,有如下url:
/logs 日志文件列表,用于下载和查看
/logLevel 允许你设定log4j的日志记录级别,类似于hadoop daemonlog
/stacks 所有线程的stack trace,对于debug很有帮助
/jmx 服务端的Metrics,以JSON格式输出。
/jmx?qry=Hadoop:*会返回所有hadoop相关指标。
/jmx?get=MXBeanName::AttributeName 查询指定bean指定属性的值,例如/jmx?get=Hadoop:service=NameNode,name=NameNodeInfo::ClusterId会返回ClusterId。
这个请求的处理类:org.apache.hadoop.jmx.JMXJsonServlet
而特定的Daemon又有特定的URL路径特定相应信息。
NameNode:http://:50070/
/dfshealth.jsp HDFS信息页面,其中有链接可以查看文件系统
/dfsnodelist.jsp?whatNodes=(DEAD|LIVE) 显示DEAD或LIVE状态的datanode
/fsck 运行fsck命令,不推荐在集群繁忙时使用!
DataNode:http://:50075/
/blockScannerReport 每个datanode都会指定间隔验证块信息
Zookeeper:
来简单说说原理:Zookeeper是以Fast Paxos算法为基础的,paxos算法存在活锁问题,即当用多个proposer交错提交时,有可能出现相互排斥导致没有一个proposer能够提交成功的情况,而Fast Poxos则做了优化,通过选举产生一个leader,只有leader才能提交proposal。
leader的选择机制,zookeeper提供了三种方式:
LeaderElection
AuthFastLeaderElection
FastLeaderElection 默认的算法是FastLeaderElection
在Zookeeper集群中,主要分为三者角色,而每一个节点同时只能扮演一种角色,这三种角色分别是:
(1). Leader 接受所有Follower的提案请求并统一协调发起提案的投票,负责与所有的Follower进行内部的数据交换(同步);
(2). Follower 直接为客户端服务并有选举权和被选举权,同时与Leader进行数据交换(同步);
(3). Observer 直接为客户端服务但无选举权和被选举权,同时与Leader进行数据交换(同步);
Zookeeper对于每个节点QuorumPeer的设计相当的灵活,QuorumPeer主要包括四个组件:客户端请求接收器(ServerCnxnFactory)、数据引擎(ZKDatabase)、选举器(Election)、核心功能组件(Leader/Follower/Observer)。其中:
(1). ServerCnxnFactory负责维护与客户端的连接(接收客户端的请求并发送相应的响应);
(2). ZKDatabase负责存储/加载/查找数据(基于目录树结构的KV+操作日志+客户端Session);
(3). Election负责选举集群的一个Leader节点;
(4). Leader/Follower/Observer一个QuorumPeer节点应该完成的核心职责;
Zookeeper的一下特点:
1、在ZooKeeper中,znode是一个跟Unix文件系统路径相似的结点,并且具有唯一的路径标识。
2、Znode可以有子znode,并且可以存放数据,但是EPHEMERAL类型的节点不能有子节点。
3、对于EPHEMERAL类型的znode节点,一旦创建这个znode的客户端与服务器失去联系,这个znode也会自动删除,ZooKeeper的客户端和服务器通信采用长连接的方式,每个客户端和服务器通过心跳来保持这个连接,这个连接状态被称为session。
4、Znode中的数据可以有多个版本。
5、Znode可以被监控,下次更新这个被监控的znode的时候,服务器就会通知客户端这个znode发生了变化,但是只会通知一次,再次更新时就不会通知了,除非再次设置监控。这个功能是zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理以及分布式锁等等。
Zookeeper安装
解压tar -zxvf ./zookeerper-3.4.10.tar.gz -C /opt
修改zoo_sample.cfg为zoo.cfg
cp ./conf/zoo_sample.cfg ./conf/zoo.cfg
在zookeeper根目录下新建目录 :mkdir ./data ./logs
修改配置文件:vim ./conf/zoo.cfg
dataDir=/opt/zookeeper-3.4.10/data
dataLogDir=/opt/zookeeper-3.4.10/logs
server.1=192.168.80.132:2888:3888
server.2=192.168.80.133:2888:3888
server.3=192.168.80.134:2888:3888
在./data目录下新建myid文件:myid里写的X就是server.X=ip:2888:3888 中的X
注意:
zk的集群机器数要为奇数,最少三台;
有时机器启动后状态还是失败,等把集群所有机器都启动后状态就会变为成功;
防火墙问题会造成zookeeper原子消息广播的失败,关闭防火墙systemctl stop firewalld
或者开启特定端口;
firewall-cmd --zone=public --add-port=2888/tcp --permanent
firewall-cmd --zone=public --add-port=3888/tcp –permanent
zookeeepr有客户端:./zkCli.sh,在客户端写可以进行目录和数据的管理
添加环境变量,每个节点本机环境变量是在 /etc/profile 目录中添加,如下:
export ZOOKEEPER_HOME=/opt/zookeeper-3.4.10
export PATH=$ZOOKEEPER_HOME/bin:$PATH
修改 ./bin/zkEnv.sh文件:
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="."
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,CONSOLE"
fi
改为
if [ "x${ZOO_LOG_DIR}" = "x" ]
then
ZOO_LOG_DIR="$ZOOBINDIR/../logs"
fi
if [ "x${ZOO_LOG4J_PROP}" = "x" ]
then
ZOO_LOG4J_PROP="INFO,ROLLINGFILE"
fi
source ./bin/zkEnv.sh
在每台集群上启动ZooKeeper Server:./bin/zkServer.sh start
执行jps命令可看到QuorumPeerMain进程,即表示启动成功
报错一例:
[root@node02 zookeeper-3.4.12]# ./bin/zkServer.sh start
ZooKeeper JMX enabled by default
Using config: /opt/zookeeper-3.4.12/bin/../conf/zoo.cfg
mkdir: cannot create directory ‘’: No such file or directory
Starting zookeeper ... STARTED
最后原因是在zoo.cfg文件中dataDir的“Dir”写成小写了, dataDir属性值前面多了一个空格;
export 环境变量的变量值后面多了一个空格;
server.x其中server头字母大写;
一定要仔细,不要直接复制文档,要在文本编辑器里编辑好再复制进linux命令行
验证:
配置环境变量ZOOKEEPER_HOME,以使zkServer.sh zkCli.sh各处都可运行
运行zkCli.sh 查看zookeeper中的数据:
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port
Paxos算法
Paxos是能够基于一大堆完全不可靠的网络条件下却能可靠确定地实现共识一致性的算法。也就是说:它允许一组不一定可靠的处理器(服务器)在某些条件得到满足情况下就能达成确定的安全的共识,如果条件不能满足也确保这组处理器(服务器)保持一致。
Paxos解决共识思路
Paxos是一个解决共识问题consensus problem的算法,现实中Paxos的实现以及成为一些世界级软件的心脏,如Cassandra, Google的 Spanner数据库, 分布式锁服务Chubby. 一个被Paxos管理的系统实际上谈论的是值 状态和跟踪等问题,其目标是建造更高可用性和强一致性的分布式系统。
Paxos完成一次写操作需要两次来回,分别是prepare/promise, 和 propose/accept:
第一次由提交者Leader向所有其他服务器发出prepare消息请求准备,所有服务器中大多数如果回复诺言承诺就表示准备好了,可以接受写入;第二次提交者向所有服务器发出正式建议propose,所有服务器中大多数如果回复已经接收就表示成功了。
算法优化(fast paxos)
Paxos算法在出现竞争的情况下,其收敛速度很慢,甚至可能出现活锁的情况,例如当有三个及三个以上的proposer在发送prepare请求后,很难有一个proposer收到半数以上的回复而不断地执行第一阶段的协议。因此,为了避免竞争,加快收敛的速度,在算法中引入了一个Leader这个角色,在正常情况下同时应该最多只能有一个参与者扮演Leader角色,而其它的参与者则扮演Acceptor的角色,同时所有的人又都扮演Learner的角色。
在这种优化算法中,只有Leader可以提出议案,从而避免了竞争使得算法能够快速地收敛而趋于一致,此时的paxos算法在本质上就退变为两阶段提交协议。但在异常情况下,系统可能会出现多Leader的情况,但这并不会破坏算法对一致性的保证,此时多个Leader都可以提出自己的提案,优化的算法就退化成了原始的paxos算法。
ZAB原子消息广播
(zookeeper Atomic Broadcast)原子消息广播
ZAB 协议是为分布式协调服务 ZooKeeper 专门设计的一种支持崩溃恢复的原子广播协议。 ZooKeeper 主要依赖 ZAB 协议来实现分布式数据一致性,基于该协议,ZooKeeper 实现了一种主备模式的系统架构来保持集群中各个副本之间的数据一致性。
ZAB协议包括两种基本的模式:崩溃恢复和消息广播
当整个服务框架在启动过程中,或是当Leader服务器出现网络中断崩溃退出与重启等异常情况时,ZAB就会进入恢复模式并选举产生新的Leader服务器。
当选举产生了新的Leader服务器,同时集群中已经有过半的机器与该Leader服务器完成了状态同步之后,ZAB协议就会退出崩溃恢复模式,进入消息广播模式(开始服务)。
当有新的服务器加入到集群中去,如果此时集群中已经存在一个Leader服务器在负责进行消息广播,那么新加入的服务器会自动进入数据恢复模式,找到Leader服务器,并与其进行数据同步,然后一起参与到消息广播流程中去。
以上其实大致经历了三个步骤:
1.崩溃恢复:主要就是Leader选举过程
2.数据同步:Leader服务器与其他服务器进行数据同步
3.消息广播:Leader服务器将数据发送给其他服务器
1.消息广播
Zookeeper 客户端会随机连接到 Zookeeper 集群的一个节点,
如果是读请求,就直接从当前节点中读取数据;
如果是写请求,那么节点就会向 leader 提交事务,Leader服务器为其生成对应的的Propose(详见paxos算法),并将其发送给其他服务器,然后再分别收集选票,只要有超过半数节点写入成功,该写请求就会被提交(类 2PC 协议)。
在广播Propose之前,Leader会为这个Propose分配一个全局单调递增的唯一ID,称之为事务ID(ZXID);由于ZAB协议需要保证每一个消息严格的因果关系,因此必须将每一个Propose按照其ZXID的先后顺序来进行排序与处理。
具体做法就是Leader为每一个Follower都各自分配一个单独的队列,然后将需要广播的Propose依次放入队列中。
2.崩溃恢复
消息广播中如果Leader出现网络中断、崩溃退出与重启等异常,将进入崩溃恢复,恢复的过程中有2个问题需要解决:
1.ZAB协议需要确保那些已经在Leader服务器上提交的事务,最终被所有服务器都提交
2.ZAB协议需要确保丢弃那些只在Leader服务器上被提交的事务
针对以上两个问题,如果让Leader选举算法能够保证新选出来的Leader服务器拥有集群中所有机器最高编号(ZXID)的Propose,那么就可以保证这个新选出来的Leader一定具有所有已经提交的提案;如果让具有最高编号的机器成为Leader,就可以省去Leader服务器检查Propose的提交和抛弃了。
3.数据同步
Leader服务器会为每个Follower服务器都准备一个队列,并将那些没有被各Follower同步的事务以propose消息的形式逐个发送给Follower服务器,并在每个消息的后面发送一个commit消息,表示提交事务;等到同步完成之后,leader服务器会将该服务器加入到真正的可用Follower列表中。
崩溃恢复中提到2个问题,看看如何解决ZAB协议需要确保丢弃那些只在Leader服务器上被提交的事务:
在 ZAB 协议的事务编号 Zxid 设计中,Zxid 是一个 64 位的数字,其中低 32 位是一个简单的单调递增的计数器,针对客户端每一个事务请求,计数器加 1;而高 32 位则代表 Leader 周期 epoch 的编号,每个当选产生一个新的 Leader 服务器,就会从这个 Leader 服务器上取出其本地日志中最大事务的ZXID,并从中读取 epoch 值,然后加 1,以此作为新的 epoch,并将低 32 位从 0 开始计数。 epoch:可以理解为当前集群所处的年代或者周期,每个 leader 就像皇帝,都有自己的年号,所以每次改朝换代,leader 变更之后,都会在前一个年代的基础上加 1。这样就算旧的 leader 崩溃恢复之后,也没有人听他的了,因为 follower 只听从当前年代的 leader 的命令。
AB协议通过epoch编号来区分Leader周期变化的策略,来保证丢弃那些只在上一个Leader服务器上被提交的事务。
分析:如果在崩溃的leader中存在只在Leader服务器上被提交的事务,那么在follower中不存在该事务,我们只选举follower中最大的事务号,因为这个事务是从崩溃的leader传递过来的,只是只传递到部分follower,但不妨碍它是当前已经被提交这样的“事实”
Zookeeper提供了什么/能做什么
文件系统
Zookeeper维护一个类似文件系统的数据结构:
通知机制
客户端注册监听它关心的目录节点,当目录节点发生变化(数据改变、被删除、子目录节点增加删除)时,zookeeper会通知客户端。
1、 命名服务
这个似乎最简单,在zookeeper的文件系统里创建一个目录,即有唯一的path。在我们使用tborg无法确定上游程序的部署机器时即可与下游程序约定好path,通过path即能互相探索发现,不见不散了。
2、 配置管理
程序总是需要配置的,如果程序分散部署在多台机器上,要逐个改变配置就变得困难。好吧,现在把这些配置全部放到zookeeper上去,保存在 Zookeeper 的某个目录节点中,然后所有相关应用程序对这个目录节点进行监听,一旦配置信息发生变化,每个应用程序就会收到 Zookeeper 的通知,然后从 Zookeeper 获取新的配置信息应用到系统中就好。
3、 集群管理
所谓集群管理无在乎两点:是否有机器退出和加入、选举master。
对于第一点,所有机器约定在父目录GroupMembers下创建临时目录节点,然后监听父目录节点的子节点变化消息。一旦有机器挂掉,该机器与zookeeper的连接断开,其所创建的临时目录节点被删除,所有其他机器都收到通知:某个兄弟目录被删除,于是,所有人都知道:它上船了。新机器加入也是类似,所有机器收到通知:新兄弟目录加入,highcount又有了。
对于第二点,我们稍微改变一下,所有机器创建临时顺序编号目录节点,每次选取编号最小的机器作为master就好。
4、 分布式锁
有了zookeeper的一致性文件系统,锁的问题变得容易。锁服务可以分为两类,一个是保持独占,另一个是控制时序。
对于第一类,我们将zookeeper上的一个znode看作是一把锁,通过createznode的方式来实现。所有客户端都去创建 /distribute_lock 节点,最终成功创建的那个客户端也即拥有了这把锁。
对于第二类, 控制时序,就是所有试图来获取这个锁的客户端,最终都是会被安排执行,只是有个全局时序了。做法和上面基本类似,只是这里/distribute_lock 已经预先存在,客户端在它下面创建临时有序节点(这个可以通过节点的属性控制:CreateMode.EPHEMERAL_SEQUENTIAL来指定)。Zk的父节点(/distribute_lock)维持一份sequence,保证子节点创建的时序性,从而也形成了每个客户端的全局时序。
完全分布式锁是全局同步的,这意味着在任何时刻没有两个客户端会同时认为它们都拥有相同的锁,使用 Zookeeper 可以实现分布式锁,需要首先定义一个锁节点(lock root node)。
需要获得锁的客户端按照以下步骤来获取锁:
1、保证锁节点(lock root node)这个父根节点的存在,这个节点是每个要获取lock客户端共用的,这个节点是PERSISTENT的。
2、第一次需要创建本客户端要获取lock的节点,调用 create( ),并设置 节点为EPHEMERAL_SEQUENTIAL类型,表示该节点为临时的和顺序的。如果获取锁的节点挂掉,则该节点自动失效,可以让其他节点获取锁。
3、在父锁节点(lock root node)上调用 getChildren( ) ,不需要设置监视标志。 (为了避免“羊群效应”).
4、按照Fair竞争的原则,将步骤3中的子节点(要获取锁的节点)按照节点顺序的大小做排序,取出编号最小的一个节点做为lock的owner,判断自己的节点id是否就为owner id,如果是则返回,lock成功。如果不是则调用 exists( )监听比自己小的前一位的id,关注它锁释放的操作(也就是exist watch)。
5、如果第4步监听exist的watch被触发,则继续按4中的原则判断自己是否能获取到lock。
释放锁:需要释放锁的客户端只需要删除在第2步中创建的节点即可。
注意事项:
一个节点的删除只会导致一个客户端被唤醒,因为每个节点只被一个客户端watch,这避免了“羊群效应”。
5、队列管理
队列方面,简单地讲有两种,
一种是常规的先进先出队列,另一种是要等到队列成员聚齐之后的才统一按序执行。
对于第一种先进先出队列,和分布式锁服务中的控制时序场景基本原理一致。
为了在 Zookeeper 中实现分布式队列,首先需要指定一个 Znode 节点作为队列节点(queue node), 各个分布式客户端通过调用 create() 函数向队列中放入数据,调用create()时节点路径名带"qn-"结尾,并设置顺序(sequence)节点标志。 由于设置了节点的顺序标志,新的路径名具有以下字符串模式:"_path-to-queue-node_/qn-X",X 是唯一自增号。需要从队列中获取数据/移除数据的客户端首先调用 getChildren() 函数,有数据则获取(获取数据后可以删除也可以不删),没有则在队列节点(queue node)上将 watch 设置为 true,等待触发并处理最小序号的节点(即从序号最小的节点中取数据)。
实现步骤基本如下:
1、前提:需要一个队列root节点dir
2、入队:使用create()创建节点,将共享数据data放在该节点上,节点类型为PERSISTENT_SEQUENTIAL,永久顺序性的(也可以设置为临时的,看需求)。
3、出队:因为队列可能为空,2种方式处理:一种如果为空则wait等待,一种返回异常。4、等待方式:这里使用了CountDownLatch的等待和Watcher的通知机制,使用了TreeMap的排序获取节点顺序最小的数据(FIFO)。
抛出异常:getChildren()获取队列数据时,如果size==0则抛出异常。
第二种队列其实是在FIFO队列的基础上作了一个增强。
通常可以在 /queue 这个znode下预先建立一个/queue/num 节点,并且赋值为n(或者直接给/queue赋值n),表示队列大小,之后每次有队列成员加入后,就判断下是否已经到达队列大小,决定是否可以开始执行了。这种用法的典型场景是,分布式环境中,一个大任务Task A,需要在很多子任务完成(或条件就绪)情况下才能进行。这个时候,凡是其中一个子任务完成(就绪),那么就去 /taskList 下建立自己的临时时序节点 (CreateMode.EPHEMERAL_SEQUENTIAL),当 /taskList 发现自己下面的子节点满足指定个数,就可以进行下一步按序进行处理了
集群的羊群效应:
一个需要避免的问题是当一个特定的znode 改变的时候ZooKeper 触发了所有watches 的事件。
举个例子,如果有1000个客户端watch 一个znode的exists调用,当这个节点被创建的时候,将会有1000个通知被发送。这种由于一个被watch的znode变化,导致大量的通知需要被发送,将会导致在这个通知期间的其他操作提交的延迟。因此,只要可能,我们都强烈建议不要这么使用watch。仅仅有很少的客户端同时去watch一个znode比较好,理想的情况是只有1个。
举个例子,有n 个clients 需要去拿到一个全局的lock.一种简单的实现就是所有的client 去create 一个/lock znode.如果znode 已经存在,只是简单的watch 该znode 被删除。当该znode 被删除的时候,client收到通知并试图create /lock。这种策略下,就会存在上文所说的问题,每次变化都会通知所有的客户端。
另外一种策略就是每个client去创建一个顺序的znode /lock/lock-xxx .ZooKeeper 会自动添加顺序号/lock/lock-xxx.我们可以通过/lock getChildren 去拿到最小的顺序号。如果client不是最小的序列号,就再比自己小一点的znode上添加watch.
比如我们按照上述逻辑创建了有三个znodes.
/lock/lock-001,
/lock/lock-002,
/lock/lock-003.
/lock/lock-001 的这个客户端获得了lock ;
/lock/lock-002 的客户端watch /lock/lock-001
/lock/lock-003 的客户端watch /lock/lock-002
通过这种方式,每个节点只watch 一个变化。s
数据发布与订阅(配置中心)
发布与订阅模型,即所谓的配置中心,顾名思义就是发布者将数据发布到ZK节点上,供订阅者动态获取数据,实现配置信息的集中式管理和动态更新。例如全局的配置信息,服务式服务框架的服务地址列表等就非常适合使用。
应用中用到的一些配置信息放到ZK上进行集中管理。
这类场景通常是这样:应用在启动的时候会主动来获取一次配置,同时,在节点上注册一个Watcher,这样一来,以后每次配置有更新的时候,都会实时通知到订阅的客户端,从来达到获取最新配置信息的目的。
分布式搜索服务中,索引的元信息和服务器集群机器的节点状态存放在ZK的一些指定节点,供各个客户端订阅使用。
分布式日志收集系统。这个系统的核心工作是收集分布在不同机器的日志。收集器通常是按照应用来分配收集任务单元,因此需要在ZK上创建一个以应用名作为path的节点P,并将这个应用的所有机器ip,以子节点的形式注册到节点P上,这样一来就能够实现机器变动的时候,能够实时通知到收集器调整任务分配。
系统中有些信息需要动态获取,并且还会存在人工手动去修改这个信息的发问。通常是暴露出接口,例如JMX接口,来获取一些运行时的信息。引入ZK之后,就不用自己实现一套方案了,只要将这些信息存放到指定的ZK节点上即可。
负载均衡
这里说的负载均衡是指软负载均衡。在分布式环境中,为了保证高可用性,通常同一个应用或同一个服务的提供方都会部署多份,达到对等服务。而消费者就须要在这些对等的服务器中选择一个来执行相关的业务逻辑,其中比较典型的是消息中间件中的生产者,消费者负载均衡。
消息中间件中发布者和订阅者的负载均衡,linkedin开源的KafkaMQ和阿里开源的metaq都是通过zookeeper来做到生产者、消费者的负载均衡。这里以metaq为例如讲下:
生产者负载均衡:metaq发送消息的时候,生产者在发送消息的时候必须选择一台broker上的一个分区来发送消息,因此metaq在运行过程中,会把所有broker和对应的分区信息全部注册到ZK指定节点上,默认的策略是一个依次轮询的过程,生产者在通过ZK获取分区列表之后,会按照brokerId和partition的顺序排列组织成一个有序的分区列表,发送的时候按照从头到尾循环往复的方式选择一个分区来发送消息。
消费负载均衡:
在消费过程中,一个消费者会消费一个或多个分区中的消息,但是一个分区只会由一个消费者来消费。MetaQ的消费策略是:
每个分区针对同一个group只挂载一个消费者。
如果同一个group的消费者数目大于分区数目,则多出来的消费者将不参与消费。
如果同一个group的消费者数目小于分区数目,则有部分消费者需要额外承担消费任务。
在某个消费者故障或者重启等情况下,其他消费者会感知到这一变化(通过 zookeeper watch消费者列表),然后重新进行负载均衡,保证所有的分区都有消费者进行消费。
命名服务(Naming Service)
命名服务也是分布式系统中比较常见的一类场景。在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息。被命名的实体通常可以是集群中的机器,提供的服务地址,远程对象等等——这些我们都可以统称他们为名字(Name)。其中较为常见的就是一些分布式服务框架中的服务地址列表。通过调用ZK提供的创建节点的API,能够很容易创建一个全局唯一的path,这个path就可以作为一个名称。
阿里巴巴集团开源的分布式服务框架Dubbo中使用ZooKeeper来作为其命名服务,维护全局的服务地址列表,点击这里查看Dubbo开源项目。在Dubbo实现中:
服务提供者在启动的时候,向ZK上的指定节点/dubbo/${serviceName}/providers目录下写入自己的URL地址,这个操作就完成了服务的发布。
服务消费者启动的时候,订阅/dubbo/${serviceName}/providers目录下的提供者URL地址, 并向/dubbo/${serviceName} /consumers目录下写入自己的URL地址。
注意,所有向ZK上注册的地址都是临时节点,这样就能够保证服务提供者和消费者能够自动感应资源的变化。
另外,Dubbo还有针对服务粒度的监控,方法是订阅/dubbo/${serviceName}目录下所有提供者和消费者的信息。
分布式通知/协调
ZooKeeper中特有watcher注册与异步通知机制,能够很好的实现分布式环境下不同系统之间的通知与协调,实现对数据变更的实时处理。使用方法通常是不同系统都对ZK上同一个znode进行注册,监听znode的变化(包括znode本身内容及子节点的),其中一个系统update了znode,那么另一个系统能够收到通知,并作出相应处理
另一种心跳检测机制:检测系统和被检测系统之间并不直接关联起来,而是通过zk上某个节点关联,大大减少系统耦合。+6
另一种系统调度模式:某系统有控制台和推送系统两部分组成,控制台的职责是控制推送系统进行相应的推送工作。管理人员在控制台作的一些操作,实际上是修改了ZK上某些节点的状态,而ZK就把这些变化通知给他们注册Watcher的客户端,即推送系统,于是,作出相应的推送任务。
另一种工作汇报模式:一些类似于任务分发系统,子任务启动后,到zk来注册一个临时节点,并且定时将自己的进度进行汇报(将进度写回这个临时节点),这样任务管理者就能够实时知道任务进度。 总之,使用zookeeper来进行分布式通知和协调能够大大降低系统之间的耦合
集群管理与Master选举 LeaderElection选举算法
选举线程由当前Server发起选举的线程担任,他主要的功能对投票结果进行统计,并选出推荐的Server。选举线程首先向所有Server发起一次询问(包括自己),被询问方,根据自己当前的状态作相应的回复,选举线程收到回复后,验证是否是自己发起的询问(验证xid 是否一致),然后获取对方的id(myid),并存储到当前询问对象列表中,最后获取对方提议 的leader 相关信息(id,zxid),并将这些 信息存储到当次选举的投票记录表中。
当向所有Server都询问完以后,对统计结果进行筛选并进行统计,计算出当次询问后获胜的是哪一个Server,并将当前zxid最大的Server 设置为当前Server要推荐的Server(有可能是自己,也有可以是其它的Server,根据投票结果而定,但是每一个Server在第一次投票时都会投自己),如果此时获胜的Server获得.n/2 + 1的Server票数,设置当前推荐的leader为获胜的Server。根据获胜的Server相关信息设置自己的状态。每一个Server都重复以上流程直到选举出Leader。
初始化选票(第一张选票): 每个quorum节点一开始都投给自己;
收集选票: 使用UDP协议尽量收集所有quorum节点当前的选票(单线程/同步方式),超时设置200ms;
统计选票:
1).每个quorum节点的票数;
2).为自己产生一张新选票(zxid、myid均最大);
选举成功: 某一个quorum节点的票数超过半数;
更新选票: 在本轮选举失败的情况下,当前quorum节点会从收集的选票中选取合适的选票(zxid、myid均最大)作为自己下一轮选举的投票
集群机器监控:这通常用于那种对集群中机器状态,机器在线率有较高要求的场景,能够快速对集群中机器变化作出响应。这样的场景中,往往有一个监控系统,实时检测集群机器是否存活。过去的做法通常是:监控系统通过某种手段(比如ping)定时检测每个机器,或者每个机器自己定时向监控系统汇报“我还活着”。 这种做法可行,但是存在两个比较明显的问题:
集群中机器有变动的时候,牵连修改的东西比较多。有一定的延时。
利用ZooKeeper有两个特性,就可以实时另一种集群机器存活性监控系统:
客户端在节点 x 上注册一个Watcher,那么如果 x的子节点变化了,会通知该客户端。
创建EPHEMERAL类型的节点,一旦客户端和服务器的会话结束或过期,那么该节点就会消失。
例如,监控系统在 /clusterServers 节点上注册一个Watcher,以后每动态加机器,那么就往 /clusterServers 下创建一个 EPHEMERAL类型的节点:/clusterServers/{hostname}. 这样,监控系统就能够实时知道机器的增减情况,至于后续处理就是监控系统的业务了。
Master选举则是zookeeper中最为经典的应用场景了。 在分布式环境中,相同的业务应用分布在不同的机器上,有些业务逻辑(例如一些耗时的计算,网络I/O处理),往往只需要让整个集群中的某一台机器进行执行,其余机器可以共享这个结果,这样可以大大减少重复劳动,提高性能,于是这个master选举便是这种场景下的碰到的主要问题。
利用ZooKeeper的强一致性,能够保证在分布式高并发情况下节点创建的全局唯一性,即:同时有多个客户端请求创建 /currentMaster 节点,最终一定只有一个客户端请求能够创建成功。利用这个特性,就能很轻易的在分布式环境中进行集群选取了。
上文中提到,所有客户端创建请求,最终只有一个能够创建成功。在这里稍微变化下,就是允许所有请求都能够创建成功,但是得有个创建顺序,于是所有的请求最终在ZK上创建结果的一种可能情况是这样: /currentMaster/{sessionId}-1 ,/currentMaster/{sessionId}-2 ,/currentMaster/{sessionId}-3 ….. 每次选取序列号最小的那个机器作为Master,如果这个机器挂了,由于他创建的节点会马上小时,那么之后最小的那个机器就是Master了。
在搜索系统中,如果集群中每个机器都生成一份全量索引,不仅耗时,而且不能保证彼此之间索引数据一致。因此让集群中的Master来进行全量索引的生成,然后同步到集群中其它机器。另外,Master选举的容灾措施是,可以随时进行手动指定master,就是说应用在zk在无法获取master信息时,可以通过比如http方式,向一个地方获取master。
在Hbase中,也是使用ZooKeeper来实现动态HMaster的选举。在Hbase实现中,会在ZK上存储一些ROOT表的地址和HMaster的地址,HRegionServer也会把自己以临时节点(Ephemeral)的方式注册到Zookeeper中,使得HMaster可以随时感知到各个HRegionServer的存活状态,同时,一旦HMaster出现问题,会重新选举出一个HMaster来运行,从而避免了HMaster的单点问题
Kafka
架构
Kafka对消息保存时根据Topic进行归类,发送消息者成为Producer,消息接受者成为Consumer;
Kafka集群由多个实例组成,每个实例称为broker;
无论是kafka集群还是producer和consumer都依赖于zookeeper来保证系统可用性,为集群保存一些meta信息。
Topic
一个Topic可以认为是一类消息,每个topic将被分成多个partition(区),每个partition在存储层面是append log文件。任何发布到此partition的消息都会被直接追加到log文件的尾部,每条消息在文件中的位置称为offset(偏移量),offset为一个long型数字,它是唯一标记一条消息。它唯一的标记一条消息。kafka并没有提供其他额外的索引机制来存储offset,因为在kafka中几乎不允许对消息进行“随机读写”。
Producers
Producer将消息发布到指定的Topic中,同时Producer也能决定将此消息归属于哪个partition;比如基于"round-robin"方式或者通过其他的一些算法等。
Consumers
本质上kafka只支持Topic。每个consumer属于一个consumer group;反过来说, 每个group中可以有多个consumer.发送到Topic的消息, 只会被订阅此Topic的每个group中的一个consumer消费。如果所有的consumer都具有相同的group,这种情况和queue模式很像;消息将会在consumers之间负载均衡。如果所有的consumer都具有不同的group, 那这就是"发布-订阅";消息将会广播给所有的消费者。
Kafka数据备份
kafka将每个partition数据复制到多个server上,任何一个partition有一个leader和多个follower(可以没有); 备份的个数可以通过broker配置文件来设定。leader处理所有的read-write请求, follower需要和leader保持同步.Follower和consumer一样, 消费消息并保存在本地日志中; leader负责跟踪所有的follower状态, 如果follower"落后"太多或者失效,leader将会把它从replicas同步列表中删除.当所有的follower都将一条消息保存成功, 此消息才被认为是"committed", 那么此时consumer才能消费它。即使只有一个replicas实例存活,仍然可以保证消息的正常发送和接收,只要zookeeper集群存活即可。
日志结构
如果一个topic的名称为"my_topic", 它有2个partitions, 那么日志将会保存在my_topic_0和my_topic_1两个目录中; 日志文件中保存了一序列"log entries"(日志条目), 每个log entry格式为"4个字节的数字N表示消息的长度" + "N个字节的消息内容";
每个日志都有一个offset来唯一的标记一条消息, offset的值为8个字节的数字, 表示此消息在此partition中所处的起始位置.
每个partition在物理存储层面, 有多个log file组成(称为segment)。segmentfile的命名为"最小offset".kafka.例如"00000000000.kafka"; 其中"最小offset"表示此segment中起始消息的offset。
安装:
解压
修改 ./config/server.properties文件
log.dirs=/opt/kafka_2.11-1.1.0/logs
host.name=172.24.5.174
listeners=PLAINTEXT://whf128:9092
advertised.listeners=PLAINTEXT://whf128:9092
log.dirs=/home/hadoop/kafka_2.11-1.1.0/logs
zookeeper.connect=172.24.5.173:2181,172.24.5.174:2181,172.24.5.175:2181
生产者配置文件修改
vim ./producer.properties
bootstrap.servers=192.168.88.132:9092,192.168.88.133:9092,192.168.88.134:9092
compression.type=async
消费者配置文件修改
vim ./consumer.properties
bootstrap.servers=192.168.88.132:9092,192.168.88.133:9092,192.168.88.134:9092
将kafka目录加入环境变量
export KAFKA_HOME=
启动
./kafka-server-start.sh -daemon ./config/server.properties &
验证:jps命令出现kafka进程
因为kafka会注册到zk中去,所以理论上kafka可以随时添加,集群安装也很方便就以上配置文件几个参数做修改;
#创建Topic
bin/kafka-topics.sh --create --topic test --zookeeper 192.168.110.128:2181,192.168.110.129:2181,192.168.110.130:2181 --config max.message.bytes=12800000 --config flush.messages=1 --partitions 3 --replication-factor 1
说明:
--topic后面的test0是topic的名称
--zookeeper应该和server.properties文件中的zookeeper.connect一样
--config指定当前topic上有效的参数值
--partitions指定topic的partition数量,如果不指定该数量,默认是server.properties文件中的num.partitions配置值
--replication-factor指定每个partition的副本个数,默认1个
查看所有topic
kafka-topics.sh --list --zookeeper 192.168.110.128:2181,192.168.110.129:2181,192.168.110.130:2181
查看指定topic
kafka-topics.sh --zookeeper 192.168.110.128:2181,192.168.110.129:2181,192.168.110.130:2181 --describe --topic logger-channel
控制台向topic生产数据,创建发布者
kafka-console-producer.sh --broker-list 192.168.110.128:2181,192.168.110.129:2181,192.168.110.130:2181 --topic logger-channel
消费者消费数据,创建订阅者
kafka-console-consumer.sh --zookeeper 192.168.110.128:192.168.110.129:2181,192.168.110.130:2181 --topic logger-channel --from-beginning
下线broker
bin/kafka-run-class.sh kafka.admin.ShutdownBroker --zookeeper 127.0.0.1:2181 --broker 0 --num.retries 3 --retry.interval.ms 60
shutdown broker如果需要迁移,需要其他额外的操作
删除kafka的topic
kafka-topics.sh --delete --zookeeper 127.0.0.1:2181 --topic test0
如果server.properties中没有把delete.topic.enable设为true,那么此时的删除并不是真正的删除,而是把topic标记为:marked for deletion
删除kafka中该topic相关的目录
在server.properties中找到配置log.dirs,把该目录下test0相关的目录删掉
删除zookeeper中该topic相关的目录
rm -r /kafka/config/topics/test0
rm -r /kafka/brokers/topics/test0
rm -r /kafka/admin/delete_topics/test0 (topic被标记为marked for deletion时需要这个命令)
修改topic的partition数量(只能增加不能减少)
bin/kafka-topics.sh --alter --zookeeper 127.0.0.1:2183 --partitions 10 --topic test0
查看topic某分区偏移量最大(小)值
kafka-run-class.sh kafka.tools.GetOffsetShell --topic toLogstash --time -1 --broker-list bgs-5p174-wangwenting:9092 --partitions 0
--broker-list 指定kafka的节点地址
--topic 指定topic
--time time为-1时表示最大值,time为-2时表示最小值
--partitions 指定分区
运行结果:
test0:0:177496
test0:1:61414
#创建一个publish
bin/kafka-console-producer.sh --broker-list 172.24.5.174:9092 --topic test
--replication-factor 2 #复制两份
--partitions 1 #创建1个分区
--topic #主题为shuaige
#查看所有的topic
kafka-topics.sh --zookeeper 192.168.88.133:2181 –list
connect-distributed.sh
connect-standalone.sh
Kafka Connect是一种用于在Kafka和其他系统之间可扩展的、可靠的流式传输数据的工具。它使得能够快速定义将大量数据集合移入和移出Kafka的连接器变得简单。 Kafka Connect可以获取整个数据库或从所有应用程序服务器收集指标到Kafka主题,使数据可用于低延迟的流处理。导出作业可以将数据从Kafka topic传输到二次存储和查询系统,或者传递到批处理系统以进行离线分析。
kafka-acls.sh kafka topic的acl权限。
修改server.properties
authorizer.class.name = kafka.security.auth.SimpleAclAuthorizer
#设置超级用户
super.users=User:admin
allow.everyone.if.no.acl.found参数,默认是false。如果一个资源R没有任何acl设置,那么默认是除了超级用户之外,其他用户都不可见。设置为true可以改变这个情况。
kafka-broker-api-versions.sh
kafka-configs.sh
kafka-console-consumer.sh
kafka-console-producer.sh
kafka-consumer-groups.sh
kafka-consumer-perf-test.sh
kafka-delegation-tokens.sh
kafka-delete-records.sh
kafka-log-dirs.sh
kafka-mirror-maker.sh
kafka-preferred-replica-election.sh
kafka-producer-perf-test.sh
kafka-reassign-partitions.sh
kafka-replay-log-producer.sh
kafka-replica-verification.sh
kafka-run-class.sh
kafka-server-start.sh
kafka-server-stop.sh
kafka-simple-consumer-shell.sh
kafka-streams-application-reset.sh
kafka-topics.sh
kafka-verifiable-consumer.sh
kafka-verifiable-producer.sh
trogdor.sh
zookeeper-security-migration.sh
zookeeper-server-start.sh
zookeeper-server-stop.sh
zookeeper-shell.sh
kafka-topics.sh --zookeeper 172.24.5.175:2181 [action] [param]
动作和参数可以通过-help获得
--list
--create
--config
--delete
--delete-config
--describe
--alter
--disable-rack-aware
--force
--if-exists
--if-not-exists
命令:kafka-topics.sh --describe --zookeeper 127.0.0.1:2181 --topic test0
运行结果:
Topic:test0 PartitionCount:16 ReplicationFactor:3 Configs:
Topic: test0 Partition: 0 Leader: 0 Replicas: 0,2,1 Isr: 1,0,2
Topic: test0 Partition: 1 Leader: 1 Replicas: 1,2,0 Isr: 1,0,2
Topic: test0 Partition: 2 Leader: 2 Replicas: 2,0,1 Isr: 1,0,2
第一行显示partitions的概况,列出了Topic名字,partition总数,存储这些partition的broker数
以下每一行都是其中一个partition的详细信息:
leader 是该partitons所在的所有broker中担任leader的broker id,每个broker都有可能成为leader
replicas 显示该partiton所有副本所在的broker列表,包括leader,不管该broker是否是存活,不管是否和leader保持了同步。
isr in-sync replicas的简写,表示存活且副本都已同步的的broker集合,是replicas的子集
举例:比如上面结果的第一行:
Topic: test0 Partition:0 Leader: 0 Replicas: 0,2,1 Isr: 1,0,2
Partition: 0 该partition编号是0
Replicas: 0,2,1 代表partition0 在broker0,broker1,broker2上保存了副本
Isr: 1,0,2 代表broker0,broker1,broker2都存活而且目前都和leader保持同步
Leader: 0 代表保存在broker0,broker1,broker2上的这三个副本中,leader是broker0
leader负责读写,broker1、broker2负责从broker0同步信息,平时没他俩什么事
当producer发送一个消息时,producer自己会判断发送到哪个partiton,如果发到了partition0上,消息会发到leader,也就是broker0上,broker0处理这个消息,broker1、broker2从broker0同步这个消息.如果这个broker0挂了,那么kafka会在Isr列表里剩下的broker1、broker2中选一个新的leader
Spring-kakfa-2.2.3 连接:
配置文件如下:
spring:
kafka:
bootstrap-servers: 192.168.110.129:9092,192.168.110.130:9092,192.168.110.131:9092
producer:
key-serializer: org.apache.kafka.common.serialization.StringSerializer
value-serializer: org.apache.kafka.common.serialization.StringSerializer
consumer:
group-id: test
enable-auto-commit: true
auto-commit-interval: 1000
key-deserializer: org.apache.kafka.common.serialization.StringDeserializer
value-deserializer: org.apache.kafka.common.serialization.StringDeserializer
Hive单节点安装
下载tar包,解压
进入./conf目录
cp ./hive-default.xml.template ./hive-site.xml
cp ./hive-log4j.properties.template ./hive-log4j.properties
cp hive-env.sh.template hive-env.sh
vim ./hive-site.xml
修改这几项:
javax.jdo.option.ConnectionURL=jdbc:mysql://172.24.5.173:3306/hive?createDatabaseIfNotExit=true
javax.jdo.option.ConnectionDriverName=com.mysql.jdbc.Driver
javax.jdo.option.ConnectionUserName=hive
javax.jdo.option.ConnectionPassword=hive
hive.exec.scratchdir=/user/hive/tmp
hive.metastore.warehouse.dir=/user/hive/warehouse
hive.querylog.location=/user/hive/log
把所有的${system:java.io.tmpdir} 都替换为:/opt/apache-hive-1.2.2-bin/tmp/
${system:user.name}替换为${user.name}
Hdfs文件系统创建对应的几个文件:
hdfs dfs -mkdir -p /user/hive/warehouse
hdfs dfs -mkdir -p /user/hive/tmp
hdfs dfs -mkdir -p /user/hive/log
hdfs dfs -chmod -R 777 /user/hive/warehouse
hdfs dfs -chmod -R 777 /user/hive/tmp
hdfs dfs -chmod -R 777 /user/hive/log
vim ./conf/hive-env.sh
export HADOOP_HOME=${HADOOP_HOME}
export HIVE_HOME=
export JAVA_HOME=
export HIVE_CONF_DIR=
vim ./bin/hive
sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`
改为
sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`
因为spark升级到spark2以后,原有lib目录下的大JAR包被分散成多个小JAR包,原来的spark-assembly-*.jar已经不存在,所以hive没有办法找到这个JAR包。如果不进行修改,将报以下错误:
cannot access /home/hadoop/spark-2.2.0-bin-hadoop2.7/lib/spark-assembly-*.jar: No such file or directory
上传mysql-connector-java.jar包到./lib下
创建hive数据库和用户:
mysql>create database hive;
mysql>create user ‘hive’ identified by ‘hive’;
mysql> GRANT ALL PRIVILEGES ON hive.* TO 'hive'@'%' identified by 'hive' with grant option;
mysql>flush privileges;
将hive目录添加到环境变量,以方便在任何地方都可以直接使用hive beeline 等命令:
export HIVE_HOME=
初始化hive:
schematool -dbType mysql -initSchema
启动hiveServer2
./bin/hive --service hiveserver2
beeline连接: !connect jdbc:hive2://172.24.5.174:10000/hive
对比:
如果是hive HA/集群,则对应的连接方式是这样的:!connect jdbc:hive2://172.24.5.173:2181,172.24.5.174:2181,172.24.5.175:2181/default;serviceDiscoveryMode=zooKeeper;zooKeeperNamespace=hiveserver2
FAQ
WARN conf.HiveConf: HiveConf of name hive.conf.hidden.list does not exist
该提示是hive-site.xml中的hive.conf.hidden.list属性已经被遗弃,系统无法识别该属性,注释掉该属性就好
ls: cannot access /home/hadoop/spark-2.2.0-bin-hadoop2.7/lib/spark-assembly-*.jar: No such file or directory
vim ./bin/hive
sparkAssemblyPath=`ls ${SPARK_HOME}/lib/spark-assembly-*.jar`
改为
sparkAssemblyPath=`ls ${SPARK_HOME}/jars/*.jar`