python爬取豆瓣电影Top250并进行数据分析
源码:Gitee
欢迎star~
实现爬取数据,存储到sqlite3,使用flask进行展示,同时,使用wordcloud生成词云图片和使用Echart进行图表展示
一、requirements
beautifulsoup4==4.9.1
bs4==0.0.1
click==7.1.2
cycler==0.10.0
Flask==1.1.2
itsdangerous==1.1.0
jieba==0.42.1
Jinja2==2.11.2
kiwisolver==1.2.0
MarkupSafe==1.1.1
matplotlib==3.2.1
numpy==1.18.4
Pillow==7.1.2
pyparsing==2.4.7
python-dateutil==2.8.1
six==1.15.0
soupsieve==2.0.1
Werkzeug==1.0.1
wordcloud @ file:python_reptile/flask/static/extend/wordcloud-1.7.0-cp36-cp36m-win32.whl
xlwt==1.3.0
二、获取并存储数据
爬取豆瓣TOP250数据,并存储到数据库
步骤:
-
定义爬取地址
-
获取URL的数据列表
通过User-Agent,得到指定一个URL的网页内容
-
存储到sqlite数据库(数据库名:
movie.db,表名:movie250)
# -*- coding:utf-8 -*-
# date: 2020-5-10
# author: jingluo
import sys
from bs4 import BeautifulSoup
import sqlite3
import re
import urllib.request, urllib.error
import xlwt
# 搜索规则
findLink = re.compile(r'')
findImageSrc = re.compile(r', re.S) # re.S让换行符包含在字符中
findTitle = re.compile(r'(.*)')
findRating = re.compile(r'')
findJudge = re.compile(r'(\d*)人评价')
findInq = re.compile(r'(.*)')
findBd = re.compile(r'(.*?)
', re.S)
def main():
# 1. 定义爬取网址
base_url = "https://movie.douban.com/top250?start="
# 2. 获取数据列表
data_list = getData(base_url)
# 3. 定义数据库名称
dbpath = "movie.db"
# 4. 存储到sqlite数据库
saveData2DB(data_list, dbpath)
# 获取数据列表
def getData(base_url):
data_list = []
for i in range(0, 10):
url = base_url + str(i*25)
html = askURl(url)
# 逐一解析网页
soup = BeautifulSoup(html, "html.parser")
for item in soup.find_all("div", class_="item"):
data = []
item = str(item)
link = re.findall(findLink, item)[0]
data.append(link)
imgSrc = re.findall(findImageSrc, item)[0]
data.append(imgSrc)
titles = re.findall(findTitle, item)
if len(titles) == 2:
ctitle = titles[0]
data.append(ctitle)
otitle = titles[1].replace("/", "")
data.append(otitle)
else:
data.append(titles[0])
data.append('')
rating = re.findall(findRating, item)[0]
data.append(rating)
judege = re.findall(findJudge, item)[0]
data.append(judege)
inq = re.findall(findInq, item)
if len(inq) != 0:
data.append(inq[0].replace("。", ""))
else:
data.append('')
bd = re.findall(findBd, item)[0]
bd = re.sub(' 三、获取词云
- 读取数据库
- 使用
jieba进行分割 - 使用
word_length.txt存储词云长度 - 将原始图转成数组
- 使用
Image和WordCloud初始化图片 - 使用
pyplot生成和保存图片
def makeWordCloud():
# 准备词云所需的词
con = sqlite3.connect('movie.db')
cur = con.cursor()
sql = 'select instroduction from movie250'
data = cur.execute(sql)
text = ""
for item in data:
text = text + item[0]
cur.close()
con.close()
cut = jieba.cut(text)
string = ' '.join(cut)
filename = 'word_length.txt'
with open(filename, 'w') as file:
file.write(str(len(string)))
file.close()
img = Image.open(r'../static/assets/img/tree.jpg')
img_arry = np.array(img) # 将图片转换成数组
wc = WordCloud(
background_color = 'white',
mask = img_arry,
font_path = 'STCAIYUN.TTF' # 字体锁在位置: C:\Windows\Fonts
)
wc.generate_from_text(string)
# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 是否显示坐标轴
# plt.show() # 显示生成的词云图片
# 输出词云图片到文件
plt.savefig(r'../static/assets/img/word.jpg', dpi=800)
plt.close()
四、完成业务代码
# -*- coding:utf-8 -*-
# date: 2020-5-30
# author: jingluo
from flask import Flask, render_template,request, session
import get_douban_databses
import sqlite3
import os
# 分词
import jieba
# 绘图,数据可视化
from matplotlib import pyplot as plt
# 词云
from wordcloud import WordCloud
# 图片处理
from PIL import Image
# 矩阵运算
import numpy as np
# 自定义template路径
app = Flask(__name__,template_folder="../templates/",
static_folder='../static/') #应用
# flask的session需要用到的密钥字符串
app.config["SECRET_KEY"] = "akjsdhkjashdkjhaksk120191101asd"
@app.route("/")
def index():
try:
with open('word_length.txt', 'r') as file:
word_length = file.readline()
session['word_length'] = word_length
file.close()
except:
word_length = 5633
session['word_length'] = word_length
return render_template("template/home.html",word_length = word_length)
@app.route("/home")
def home():
word_length = session.get('word_length')
return render_template("template/home.html",word_length = word_length)
@app.route("/movie")
def movie():
movies = []
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select * from movie250"
data = cur.execute(sql)
for item in data:
movies.append(item)
cur.close()
con.close()
return render_template("template/movie.html",movies = movies)
@app.route("/score")
def score():
score = []
number = []
con = sqlite3.connect("movie.db")
cur = con.cursor()
sql = "select score,count(score) from movie250 group by score"
data = cur.execute(sql)
for item in data:
score.append(item[0])
number.append(item[1])
cur.close()
con.close()
return render_template("template/score.html", score = score, number = number)
# 生成词云图片
def makeWordCloud():
# 准备词云所需的词
con = sqlite3.connect('movie.db')
cur = con.cursor()
sql = 'select instroduction from movie250'
data = cur.execute(sql)
text = ""
for item in data:
text = text + item[0]
cur.close()
con.close()
cut = jieba.cut(text)
string = ' '.join(cut)
filename = 'word_length.txt'
with open(filename, 'w') as file:
file.write(str(len(string)))
file.close()
img = Image.open(r'../static/assets/img/tree.jpg')
img_arry = np.array(img) # 将图片转换成数组
wc = WordCloud(
background_color = 'white',
mask = img_arry,
font_path = 'STCAIYUN.TTF' # 字体锁在位置: C:\Windows\Fonts
)
wc.generate_from_text(string)
# 绘制图片
fig = plt.figure(1)
plt.imshow(wc)
plt.axis('off') # 是否显示坐标轴
# plt.show() # 显示生成的词云图片
# 输出词云图片到文件
plt.savefig(r'../static/assets/img/word.jpg', dpi=800)
plt.close()
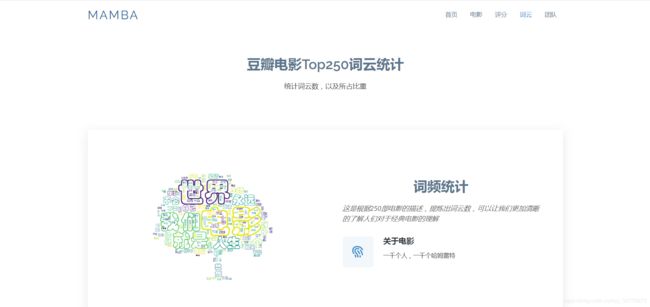
@app.route("/word")
def word():
return render_template("template/word.html")
@app.route("/team")
def team():
return render_template("template/team.html")
if __name__ == '__main__':
app.config.update(DEBUG=True)
if not os.path.exists('movie.db'):
get_douban_databses.main()
if not os.path.exists('../static/assets/img/word.jpg'):
makeWordCloud()
app.run()
五、使用教程
git clone https://gitee.com/jingluoonline/python_reptile.gitcd python_reptile/flsk/apps- 输入创建虚拟化境的命令
virtualenv FlaskPath - 进入虚拟环境
FlaskPath\Scripts\activate.bat - 安装相关依赖
- 其中
wordcloud下载有时候会有问题,可以选择使用whl文件下载,网址https://www.lfd.uci.edu/~gohlke/pythonlibs/#wordcloud找到相应的包下载到本地,进行本地安装
- 其中
python index.py,有点慢,因为爬取数据和生成图片都是在初始化时- 浏览器输入
http://127.0.0.1:5000/
六、效果图
- 主页

- 电影

- 评分

- 词云
- 团队