Spark:RDD编程总结(概述、算子、分区、共享变量)
目录
1、RDD概述
1.1、RDD是什么
1.2、RDD的弹性
1.3、RDD的特点
1.3.1、分区
1.3.2、只读
1.3.3、依赖
1.3.4、缓存
1.3.5、检查点
2、RDD编程
2.1、RDD创建
2.1.1、并行化集合
2.1.2、读取外部数据集
2.2、RDD的操作
2.2.1、转换
2.2.2、行动
2.2.3、控制
1)缓存
2)检查点
3、RDD算子练习案例
3.1、求百年来降水量TOP10
3.2、二次排序
3.3、祖父-孙子关系
3.4、PageRank
4、PairRDD数据分区
4.1、获取/设置分区方式
4.2、HashPartitioner
4.3、RangePartitioner
4.4、自定义分区器
5、共享变量
5.1、广播变量
5.2、累加器
1、RDD概述
1.1、RDD是什么
RDD(Resilient Distributed Dataset),弹性分布式数据集,实现了Spark数据处理的核心抽象。
MapReduce也是一种基于数据集的工作模式,MapReduce一般是从存储上加载数据集,然后操作数据集,中间计算过程也有可能会写入存储,最后写入物理存储设备。而数据更多面临的是一次性处理。MR在迭代式算法以及交互式数据挖掘上就很不擅长。
1)RDD代表一个不可变、可分区(分片)、只读的集合
2)在 Spark 中,对数据的所有操作不外乎创建 RDD、转化已有 RDD 以及调用 RDD 操作进行求值
3)每个 RDD 都被分为多个分区,这些分区运行在集群中的不同节点上
4)RDD 具有数据流模型的特点:自动容错、位置感知性调度和可伸缩性
5)RDD 允许执行多个查询时显式地将工作集缓存在内存中,后续的查询能够重用工作集,极大地提升了查询速度
6)RDD 支持两种操作:转化操作和行动操作。RDD 的转化操作是返回一个新的 RDD 的操作,比如 map() 和 filter(),而行动操作则是向驱动器程序返回结果或把结果写入外部系统的操作。比如 count() 和 first()
7)Spark 采用 惰性计算模式,RDD 只有第一次在一个行动操作中用到时,才会真正计算。Spark 可以优化整个计算过程。默认情况下,Spark 的 RDD 会在你每次对它们进行行动操作时重新计算。如果想在多个行动操作中重用同一个 RDD,可以使用 RDD.persist() 让 Spark 把这个 RDD 缓存下来。
1.2、RDD的弹性
1)内存与磁盘存储的弹性
Spark优先将数据放在内存中,若内存放不下才会被放到磁盘中,弹性切换存储模式
RDD可通过persist持久化将RDD缓存到内存或磁盘中,当再次使用到该RDD时直接从内存中读取即可;也可将RDD进行保存检查点,checkpoint会将RDD存储在hdfs上,该RDD的所有父RDD依赖都会被移出
2)基于血统的容错弹性
RDD在进行转换和行动时,会形成RDD的Lineage依赖链。当一个RDD失效时,可以通过重新计算上游的RDD来重新生成丢失的RDD数据
3)数据调度计算的弹性
Spark将任务执行模型抽象为通用的有向无环图DAG,可以将多stage的任务并行执行,调度引擎自动处理stage及task的失败。RDD的计算任务task,或者task中的某个stage计算失败时,会自动进行重新计算,默认的次数为4次
4)数据分区的高弹性
每个 RDD 的分区运行在集群中的不同节点上,RDD允许动态地调整数据分区的个数
1.3、RDD的特点
关于一个 RDD 至少可以知道以下几点信息:
1、分区数以及分区方式;
2、由父 RDDs 衍生而来的相关依赖信息;
3、计算每个分区的数据,计算步骤为:
1)如果被缓存,则从缓存中取的分区的数据;
2)如果被 checkpoint,则从 checkpoint 处恢复数据;
3)根据血缘关系计算分区的数据。
1.3.1、分区
RDD逻辑上是分区的,底层采用的是MapReduce V1中的文件逻辑分片,每个分区的数据位于集群中不同的节点中。计算的时候回通过compute函数来得到每个分区的数据。如果RDD通过已有的文件系统构建,则comput函数读取指定文件系统中的数据;若RDD是通过其他RDD转化而来的,则compute函数执行转罗逻辑将其他RDD的数据进行转换
1.3.2、只读
RDD是只读的,要想改变RDD中的数据,只能在现有的RDD基础上创建新的RDD。
spark中提供了80多种算子实现了RDD的转换。RDD的操作算子包括两类:一是转换算子,它将RDD进行转换,构建RDD的血缘关系;二是行动算子,它用来触发RDD的计算,可以得到RDD的计算结果或将RDD保存到文件系统中
1.3.3、依赖
RDD通过算子进行转换,得到的新RDD包含了从其他RDD衍生所必需的的信息,RDD之间维护着血缘关系,也称为依赖。由于算子操作对象为RDD中的每个分区,所以RDD之间的依赖也可理解为各个分区之间的依赖
依赖包括两种:窄依赖和宽依赖。窄依赖是一对一的关系,一个父分区对应一个子分区;宽依赖则为一对多,每个父分区对应多个子分区

1)窄依赖允许在一个集群节点上以流水线的方式(pipeline)计算所有父分区。例如,逐个元素地执行map、然后filter操作;窄依赖能够更有效地进行失效节点的恢复,即只需重新计算丢失RDD分区的父分区,而且不同节点之间可以并行计算
2)宽依赖则需要首先计算好所有父分区数据,然后在节点之间进行Shuffle,这与MapReduce类似。对于一个宽依赖关系的Lineage图,单个节点失效可能导致这个RDD的所有祖先丢失部分分区,因而需要整体重新计算。
通过RDD之间的依赖关系,一个任务可以描述为DAG。窄依赖的转换在一个stage中流式进行,宽依赖需要进行混洗

1.3.4、缓存
如果应用程序中多次使用同一个RDD,可以将该RDD缓存起来,则该RDD只有在第一次计算的时候回根据依赖得到分区的数据,在后续用到该RDD时,会直接从缓存中取得数据而不用重新按照血缘关系计算一遍
1.3.5、检查点
对于长时间迭代型的应用来说,随着多次迭代RDD之间的依赖关系会越来越长,那么在后续过程中出错,则需要通过非常长的血缘关系去重建,与hdfs的检查点机制一个道理(防止edit编辑日志文件过长)。RDD支持checkpoint将数据保存到持久化地存储中,这样会切断之前的血缘关系
2、RDD编程
2.1、RDD创建
RDD的创建大致可以分为2类:从集合中创建RDD、从外部存储创建RDD
2.1.1、并行化集合
可以通过SparkContext对象的parallelize或makeRDD方法并行化集合,并且可以传入分区数量参数
def parallelize[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
assertNotStopped()
new ParallelCollectionRDD[T](this, seq, numSlices, Map[Int, Seq[String]]())
}
//调用了parallelize
def makeRDD[T: ClassTag](
seq: Seq[T],
numSlices: Int = defaultParallelism): RDD[T] = withScope {
parallelize(seq, numSlices)
}
//接收的参数类型是Seq[(T, Seq[String])],也就是每个对象具有一个或多个位置首选项(Spark 节点的主机名)
//并且分区数为Seq[(T, Seq[String])]的size
def makeRDD[T: ClassTag](seq: Seq[(T, Seq[String])]): RDD[T] = withScope {
assertNotStopped()
val indexToPrefs = seq.zipWithIndex.map(t => (t._2, t._1._2)).toMap
new ParallelCollectionRDD[T](this, seq.map(_._1), math.max(seq.size, 1), indexToPrefs)
}关于分区数详情可见https://jodjod.blog.csdn.net/article/details/97494565
//standalone模式下,有3个Excutor,每个Excutor默认1核,所以默认分区数为3。实际调用的是parallelize
scala> val rdd = sc.makeRDD(List(1,2,3,4,5))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at makeRDD at :24
//获取RDD分区数
scala> rdd.partitions.size
res1: Int = 3
//指定为4个分区
scala> val rdd = sc.parallelize(List(1,2,3,4,5),4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[2] at parallelize at :24
scala> rdd.partitions.size
res2: Int = 3
//glom函数将同一个分区内的元素合并到一个数组中,collect函数将RDD类型的数据转化为数组,同时会从远程集群是拉取数据到driver端
scala> rdd.glom.collect
res4: Array[Array[Int]] = Array(Array(1), Array(2), Array(3), Array(4, 5))
//传入的是List[(Int,List[String])],此时列表中有几个元素就有几个分区
scala> val rdd = sc.makeRDD(List((1,List("master","slave1")),(2,List("slave2"))))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at makeRDD at :24
//preferredLocations函数查看"首选位置",其实就是访问字符串列表;partitions(N)中N指定了分区号
scala> rdd.preferredLocations(rdd.partitions(0))
res7: Seq[String] = List(master, slave1)
scala> rdd.preferredLocations(rdd.partitions(1))
res8: Seq[String] = List(slave2)
2.1.2、读取外部数据集
可以从本地文件系统或者HDFS上读取数据集
//默认为HDFS路径,若从本地文件系统读取,在standalone模式下确保每个Worker节点也存在相同文件,因为RDD不同分区的数据会存储在不同节点中
scala> val tf = sc.textFile("/f1.txt")
tf: org.apache.spark.rdd.RDD[String] = /f1.txt MapPartitionsRDD[9] at textFile at :24
RDD也支持从其他文件格式(sequencefile、objectfile等)中读取文件,在后面会讲到
2.2、RDD的操作
RDD 中的所有转换都是延迟加载的,也就是说它们并不会直接计算结果。它们只是记住这些应用到基础数据集(例如一个文件)上的转换动作。只有当发生一个要求返回结果给 Driver 的动作时,这些转换才会真正运行。这种设计让 Spark 更加有效率地运行。
操作类型大致可以分为:转换操作、控制操作、行动操作
2.2.1、转换
转换操作会返回一个新的RDD
1)map(func)
//返回一个新的 RDD,该 RDD 由每一个输入元素经过 func 函数转换后组成
def map[U: ClassTag](f: T => U): RDD[U]scala> val rdd = sc.parallelize(List(1,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[10] at parallelize at :24
//对rdd中每个元素+1
scala> rdd.map(_+1)
res9: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[11] at map at :27
scala> rdd.collect
res10: Array[Int] = Array(1, 2, 3)
2)filter(func)
//返回一个新的 RDD,该 RDD 由经过 func 函数计算后返回值为 true 的输入元素组成
def filter(f: T => Boolean): RDD[T] scala> val rdd = sc.parallelize(List(1,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[12] at parallelize at :24
//过滤出奇数,注意会过滤掉func返回false的
scala> rdd.filter(_%2 == 1).collect
res13: Array[Int] = Array(1, 3)
3)flatMap(func)
//类似于 map,但将map结果扁平化到一个序列中
def flatMap[U: ClassTag](f: T => TraversableOnce[U]): RDD[U]
scala> val rdd = sc.parallelize(List(List(1,2,3),List(4,5,6)))
rdd: org.apache.spark.rdd.RDD[List[Int]] = ParallelCollectionRDD[15] at parallelize at :24
scala> rdd.map(x=>x).collect
res16: Array[List[Int]] = Array(List(1, 2, 3), List(4, 5, 6))
scala> rdd.flatMap(x=>x).collect
res18: Array[Int] = Array(1, 2, 3, 4, 5, 6)
//注意:字符串也是序列!
scala> val rdd = sc.parallelize(List("abc","def"))
rdd: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[20] at parallelize at :24
scala> rdd.flatMap(x=>x).collect
res20: Array[Char] = Array(a, b, c, d, e, f)
4)mapPartitions(func)
//类似于 map,但独立地在 RDD 的每一个分片上运行,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是 Iterator[T] => Iterator[U]
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]假设有 N 个元素,有 M 个分区,那么 map 的函数的将被调用 N 次,而 mapPartitions 被调用 M 次,一个函数一次处理所有分区。mapPartitions 的执行效率要比 map 高。例如将RDD中的所有数据通过JDBC连接写入数据库中,如果使用map函数可能需要为每一个元素都创建一个连接,若使用mapPartition函数可以针对每一个分区创建一个连接
//相当于RDD中每个元素调用func
def map[U: ClassTag](f: T => U): RDD[U] = withScope {
val cleanF = sc.clean(f)
new MapPartitionsRDD[U, T](this, (context, pid, iter) => iter.map(cleanF))
}
def map[B](f: A => B): Iterator[B] = new AbstractIterator[B] {
def hasNext = self.hasNext
def next() = f(self.next())
}
//相当于将分区(迭代器)作为参数传递给func
def mapPartitions[U: ClassTag](
f: Iterator[T] => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U] = withScope {
val cleanedF = sc.clean(f)
new MapPartitionsRDD(
this,
(context: TaskContext, index: Int, iter: Iterator[T]) => cleanedF(iter),
preservesPartitioning)
}scala> val rdd = sc.parallelize(1 to 10, 5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[23] at parallelize at :24
//第一个_表示分区(迭代器),第二个_表示分区中的元素
scala> rdd.mapPartitions(_.map(_+"a")).collect
res21: Array[String] = Array(1a, 2a, 3a, 4a, 5a, 6a, 7a, 8a, 9a, 10a)
//Iterator调用mkString返回String,mapPartitions中func要求返回Iterator
scala> rdd.mapPartitions(x=>Iterator(x.mkString("|"))).collect
res24: Array[String] = Array(1|2, 3|4, 5|6, 7|8, 9|10) 5)mapPartitionsWithIndex(func)
//类似于 mapPartitions,但 func 带有一个整数参数表示分片的索引值,因此在类型为 T 的 RDD 上运行时,func 的函数类型必须是 (Int, Interator[T]) => Iterator[U]。
private[spark] def mapPartitionsWithIndexInternal[U: ClassTag](
f: (Int, Iterator[T]) => Iterator[U],
preservesPartitioning: Boolean = false): RDD[U]
scala> val rdd = sc.parallelize(1 to 10, 5)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[27] at parallelize at :24
scala> rdd.mapPartitionsWithIndex((index,x)=>Iterator(index + ":" + x.mkString("|"))).collect
res27: Array[String] = Array(0:1|2, 1:3|4, 2:5|6, 3:7|8, 4:9|10)
6)randomSplit(weights,seed)
//将RDD按照权重进行随机分配,返回指定个数的RDD集合
def randomSplit(weights: Array[Double], seed: Long = Utils.random.nextLong): Array[RDD[T]]scala> val rdd = sc.parallelize(List(1,2,3,4,5,6,7))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[46] at parallelize at :24
//权重数组中所有元素相加应该为1
scala> val rdd1 = rdd.randomSplit(Array(0.7,0.1,0.2))
rdd1: Array[org.apache.spark.rdd.RDD[Int]] = Array(MapPartitionsRDD[47] at randomSplit at :26, MapPartitionsRDD[48] at randomSplit at :26, MapPartitionsRDD[49] at randomSplit at :26)
//0.7
scala> rdd1(0).collect
res41: Array[Int] = Array(1, 3, 4, 5, 6, 7)
//0.1
scala> rdd1(1).collect
res42: Array[Int] = Array()
//0.2
scala> rdd1(2).collect
res43: Array[Int] = Array(2)
7)union(otherDataset)
//对源 RDD 和参数 RDD 求并集后返回一个新的 RDD
def union(other: RDD[T]): RDD[T]
scala> val rdd1 = sc.parallelize(1 to 5)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[60] at parallelize at :24
scala> val rdd2 = sc.parallelize(5 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[61] at parallelize at :24
//不去重
scala> val rdd3 = rdd1.union(rdd2).collect
rdd3: Array[Int] = Array(1, 2, 3, 4, 5, 5, 6, 7, 8, 9, 10)
8)intersection(otherDataset)
//对源 RDD 和参数 RDD 求交集后返回一个新的 RDD
def intersection(other: RDD[T]): RDD[T]
scala> val rdd1 = sc.parallelize(1 to 7)
rdd1: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[63] at parallelize at :24
scala> val rdd2 = sc.parallelize(5 to 10)
rdd2: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[64] at parallelize at :24
scala> val rdd3 = rdd1.intersection(rdd2).collect
rdd3: Array[Int] = Array(6, 7, 5)
9)subtrat(otherDataset)
//对源 RDD 和参数 RDD 求差集后返回一个新的 RDD
def subtract(other: RDD[T]): RDD[T]scala> val b = sc.parallelize(1 to 3, 3)
b: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[99] at parallelize at :24
scala> val c = a.subtract(b)
c: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[103] at subtract at :28
scala> c.collect
res65: Array[Int] = Array(6, 9, 4, 7, 5, 8)
10)distinct([numTasks]))
//对原 RDD 进行去重后返回一个新的 RDD。默认情况下,只有 8 个并行任务来操作,但是可以传入一个可选的 numTasks 参数改变它。
def distinct(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
def distinct(): RDD[T]
scala> val rdd = sc.parallelize(List(1, 2, 1, 5, 2, 9, 6, 1))
distinctRdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[71] at parallelize at :24
//由于distinct需要比较不同分区中中所有值,所以需要进行混洗,默认8个并行task
scala> rdd.distinct().collect
res45: Array[Int] = Array(6, 9, 1, 5, 2)
//指定两个并行任务
scala> rdd.distinct(2).collect
res46: Array[Int] = Array(6, 2, 1, 9, 5)
11)zip(otherRDD)
//与otherRDD组合新的RDD,要求每个RDD具有相同的分区数,需RDD的每个分区具有相同的数据个数
def zip[U: ClassTag](other: RDD[U]): RDD[(T, U)]scala> val rdd = sc.parallelize(1 to 10 ,3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[90] at parallelize at :24
scala> val rdd1 = sc.parallelize(List("a","b","c","d","e","f","g","h","i","j"),3)
rdd1: org.apache.spark.rdd.RDD[String] = ParallelCollectionRDD[91] at parallelize at :24
scala> val rdd2 =rdd.zip(rdd1)
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ZippedPartitionsRDD2[92] at zip at :28
scala> rdd2.collect
res61: Array[(Int, String)] = Array((1,a), (2,b), (3,c), (4,d), (5,e), (6,f), (7,g), (8,h), (9,i), (10,j))
12)zipWithIndex
//将现有的RDD的每个元素和相对应的Index组合,生成新的RDD[(T,Long)]
def zipWithIndex(): RDD[(T, Long)]scala> val rdd = sc.parallelize(1 to 10 ,3)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[93] at parallelize at :24
scala> rdd.zipWithIndex.collect
res62: Array[(Int, Long)] = Array((1,0), (2,1), (3,2), (4,3), (5,4), (6,5), (7,6), (8,7), (9,8), (10,9))
13)zipWithUniqueId
/*该函数将RDD中元素和一个唯一ID组合成键/值对,该唯一ID生成算法如下:
每个分区中第一个元素的唯一ID值为:该分区索引号,
每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对。
*/
def zipWithUniqueId(): RDD[(T, Long)]scala> val rdd = sc.parallelize(List(1,2,3,4,5),2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[95] at parallelize at :24
scala> rdd.glom.collect
res63: Array[Array[Int]] = Array(Array(1, 2), Array(3, 4, 5))
scala> val rdd2 = rdd.zipWithUniqueId()
rdd2: org.apache.spark.rdd.RDD[(Int, Long)] = MapPartitionsRDD[97] at zipWithUniqueId at :26
/*一个分区的第一个元素0,第二个分区的第一个元素1
第一个分区的第二个元素0+2
第二个分区的第二个元素1+2=3;第二个分区的第三个元素3+2=5;
*/
scala> rdd2.collect
res64: Array[(Int, Long)] = Array((1,0), (2,2), (3,1), (4,3), (5,5))
zipWithIndex需要启动一个额外的spark作业来计算每一个分区的开始索引号,以便能顺序索引,而zipWithUniqueId不需要这样一个额外的作业
接下来是针对pairRDD的转换,pariRDD是特指RDD中的元素为为两个元素的元组
14)keys/values
//分别返回pairRDD中所有的key和value
def keys: RDD[K]
def values: RDD[V]scala> val rdd = sc.parallelize(List((1,"a"),(2,"b"),(3,"c")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[118] at parallelize at :24
scala> rdd.keys.collect
res73: Array[Int] = Array(1, 2, 3)
scala> rdd.values.collect
res74: Array[String] = Array(a, b, c)
15)KeyBy
//将f函数的返回值作为Key,与RDD的每个元素构成piarRDD
def keyBy[K](f: T => K): RDD[(K, T)]scala> val rdd = sc.parallelize(List(1,2,3))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[121] at parallelize at :24
//快速构建pairRDD
scala> rdd.keyBy(x=>null).collect
res75: Array[(Null, Int)] = Array((null,1), (null,2), (null,3)) 16)partitionBy
//对 pairRDD 进行重新分区,如果原有的分区器和指定的是一致的话就不进行分区,否则会生成 shuffleRDD
def partitionBy(partitioner: Partitioner): RDD[(K, V)]
scala> val rdd = sc.parallelize(Array((1,"aaa"), (2,"bbb"), (3,"ccc"), (4,"ddd")), 2)
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[80] at parallelize at :24
scala> rdd.partitions.size
res53: Int = 2
//通过partitioner函数获取分区器
scala> rdd.partitioner
res54: Option[org.apache.spark.Partitioner] = None
scala> var rdd2 = rdd.partitionBy(new org.apache.spark.HashPartitioner(3))
rdd2: org.apache.spark.rdd.RDD[(Int, String)] = ShuffledRDD[81] at partitionBy at :26
scala> rdd2.partitions.size
res55: Int = 3
scala> rdd2.partitioner
res56: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@3)
17)reduceByKey(func, [numTasks])
//在一个 (K,V) 的 RDD 上调用,返回一个 (K,V) 的 RDD,使用指定的 reduce 函数,将相同 key 的值聚合到一起,reduce 任务的个数可以通过第二个可选的参数来设置。
def reduceByKey(partitioner: Partitioner, func: (V, V) => V): RDD[(K, V)]
def reduceByKey(func: (V, V) => V, numPartitions: Int): RDD[(K, V)]
def reduceByKey(func: (V, V) => V): RDD[(K, V)]
scala> val rdd = sc.parallelize(List(("b",1), ("a",5), ("a",5), ("b",2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[104] at parallelize at :24
scala> rdd.reduceByKey(_+_).collect
res66: Array[(String, Int)] = Array((a,10), (b,3))
18)groupByKey
//对每个 key 进行操作,但只生成一个序列
def groupByKey(partitioner: Partitioner): RDD[(K, Iterable[V])]
scala> val rdd = sc.parallelize(List(("b",1), ("a",5), ("a",5), ("b",2)))
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[106] at parallelize at :24
scala> rdd.groupByKey.collect
res67: Array[(String, Iterable[Int])] = Array((a,CompactBuffer(5, 5)), (b,CompactBuffer(1, 2)))
19)combineByKey(createCombiner,mergeValue,mergeCombiners)
def combineByKey[C](
createCombiner: V => C,
mergeValue: (C, V) => C,
mergeCombiners: (C, C) => C)- createCombiner
combineByKey 会遍历分区中的所有元素,因此每个元素的键要么还没有遇到过,要么就和之前的某个元素的键相同。如果这是一个新的元素,combineByKey() 会使用一个叫作 createCombiner() 的函数来创建那个键对应的累加器的初始值。
- mergeValue
如果这是一个在处理当前分区之前已经遇到的键,它会使用 mergeValue() 方法将该键的累加器对应的当前值与这个新的值进行合并。
- mergeCombiners
由于每个分区都是独立处理的,因此对于同一个键可以有多个累加器。如果有两个或者更多的分区都有对应同一个键的累加器,就需要使用用户提供的 mergeCombiners() 方法将各个分区的结果进行合并。
//元素为(科目,分数)
scala> val rdd = sc.makeRDD(Array(("a",50),("a",70),("b",60),("a",60),("b",80),("c",90),("b",90),("c",60),("c",80)),3)
rdd: org.apache.spark.rdd.RDD[(String, Int)] = ParallelCollectionRDD[108] at makeRDD at :24
//求不同科目的总分和人数
scala> rdd.combineByKey((_, 1), (c:(Int,Int), v) => (c._1 + v, c._2 + 1), (c1:(Int,Int), c2:(Int,Int)) => (c1._1 + c2._1, c1._2 + c2._2)).collect
res69: Array[(String, (Int, Int))] = Array((c,(230,3)), (a,(180,3)), (b,(230,3)))
20)aggregateByKey(zeroValue)(seqOp,comOp)
def aggregateByKey[U: ClassTag](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U): RDD[(K, U)]aggregateByKey是 combineBykey 的简化操作,zeroValue 类似于 createCombiner, seqOp 类似于 mergeValue, combOp 类似于 mergeCombiner。
在 kv 对的 RDD 中,按 key 将 value 进行分组合并,合并时,将初始值和每个 value 作为 seq 函数的参数,进行对应的计算,返回的结果作为一个新的 kv 对,然后再将结果按照 key 进行合并,最后将每个分组的 value 传递给 combine 函数进行计算(先将前两个 value 进行计算,将返回结果和下一个 value 传给 combine 函数,以此类推),将 key 与计算结果作为一个新的 kv 对输出。seqOp 函数用于在每一个分区中用初始值逐步迭代 value,combOp 函数用于合并每个分区中的结果
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[112] at parallelize at :24
scala> rdd.glom.collect
res70: Array[Array[(Int, Int)]] = Array(Array((1,3), (1,2)), Array((1,4), (2,3)), Array((3,6), (3,8)))
//(1,7)中的7是3+4
scala> rdd.aggregateByKey(0)(math.max(_,_),_+_).collect
res71: Array[(Int, Int)] = Array((3,8), (1,7), (2,3))
21)foldByKey
//是 aggregateByKey 的简化操作,seqop 和 combop 相同。注意:V 的类型不能改变。
def foldByKey(zeroValue: V)(func: (V, V) => V): RDD[(K, V)]
scala> val rdd = sc.parallelize(List((1,3),(1,2),(1,4),(2,3),(3,6),(3,8)),3)
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[115] at parallelize at :24
scala> val fold = rdd.foldByKey(0)(_+_)
fold: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[116] at foldByKey at :26
scala> fold.collect()
res72: Array[(Int, Int)] = Array((3,14), (1,9), (2,3))
22)sortByKey([ascending], [numTasks])
//在一个 (K,V) 的 RDD 上调用,K 必须实现 Ordered 接口,返回一个按照 key 进行排序的 (K,V) 的 RDD
def sortByKey(
ascending: Boolean = true,
numPartitions: Int = self.partitions.length): RDD[(K, V)]
scala> val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[123] at parallelize at :24
//升序
scala> rdd.sortByKey(true).collect()
res76: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
//降序
scala> rdd.sortByKey(false).collect()
res77: Array[(Int, String)] = Array((6,cc), (3,aa), (2,bb), (1,dd))
23)sortBy(func, [ascending], [numTasks])
//与 sortByKey 类似,但是更灵活,可以用 func 先对数据进行处理,按照处理后的数据比较结果排序
def sortBy[K](
f: (T) => K,
ascending: Boolean = true,
numPartitions: Int = this.partitions.length)
(implicit ord: Ordering[K], ctag: ClassTag[K]): RDD[T]
scala> val rdd = sc.parallelize(Array((3,"aa"),(6,"cc"),(2,"bb"),(1,"dd")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[130] at parallelize at :24
scala> rdd.sortBy(_._1).collect
res78: Array[(Int, String)] = Array((1,dd), (2,bb), (3,aa), (6,cc))
24)join/leftOuterJoin/rightOuterJoin/fullOuterJoin/cartesian
a.rightOuterJoin(b)则a中所有元素存在
a.leftOuterJoin(b)则b中所有元素存在
25)mapValues
//只对 KV 结构中 value 数据进行映射。value 可以改变类型。
def mapValues[U](f: V => U): RDD[(K, U)]
scala> val rdd = sc.parallelize(Array((1,"a"),(1,"d"),(2,"b"),(3,"c")))
rdd: org.apache.spark.rdd.RDD[(Int, String)] = ParallelCollectionRDD[136] at parallelize at :24
scala> rdd.mapValues(_+"X").collect()
res79: Array[(Int, String)] = Array((1,aX), (1,dX), (2,bX), (3,cX)) 26)repartition(numPartitions)
//根据分区数,重新通过网络随机洗牌所有数据。底层调用coalesce(numPartitions,true)
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T]
27)coalesce(numPartitions)
//缩减分区数,用于大数据集过滤后,提高小数据集的执行效率。默认shuffle为false,即不进行混洗
def coalesce(numPartitions: Int, shuffle: Boolean = false,partitionCoalescer: Option[PartitionCoalescer] = Option.empty)(implicit ord: Ordering[T] = null): RDD[T]
scala> val rdd = sc.parallelize(1 to 16,4)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[138] at parallelize at :24
scala> val coalesceRDD = rdd.coalesce(3)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[139] at coalesce at :26
scala> coalesceRDD.partitions.size
res80: Int = 3
scala> val coalesceRDD = rdd.coalesce(5)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = CoalescedRDD[140] at coalesce at :26
scala> coalesceRDD.partitions.size
res81: Int = 4
scala> val coalesceRDD = rdd.coalesce(5,true)
coalesceRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[144] at coalesce at :26
//等价于reparation(5)
scala> coalesceRDD.partitions.size
res82: Int = 5
2.2.2、行动
1)reduce(func)
//通过 func 函数聚集 RDD 中的所有元素,这个功能必须是可交换且可并联的。
def reduce(f: (T, T) => T): T
2)collect()
将数据返回到 Driver,是以数组的形式返回数据集的所有元素
3)count()
返回 RDD 的元素个数
4)first()
返回 RDD 的第一个元素
5)take(n)
返回一个由数据集的前 n 个元素组成的数组
6)takeSample(withReplacement, num, [seed])
返回一个数组,该数组由从数据集中随机采样的 num 个元素组成,可以选择是否用随机数替换不足的部分,seed 用于指定随机数生成器种子
7)takeOrdered(n)
从小到大返回前n个排序
8)top(n)
从大到小返回前n个排序
9)aggregate
/*
操作的是数值型数据,aggregate 函数将每个分区里面的元素通过 seqOp 和初始值进行聚合,
然后用 combine 函数将每个分区的结果和初始值 (zeroValue) 进行 combine 操作。
这个函数最终返回的类型不需要和 RDD 中元素类型一致。
*/
def aggregate(zeroValue: U)(seqOp: (U, T) ⇒ U, combOp: (U, U) ⇒ U)scala> var rdd = sc.makeRDD(1 to 4,2)
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[0] at makeRDD at :24
scala> rdd.glom.collect
res2: Array[Array[Int]] = Array(Array(1, 2), Array(3, 4))
/*
1*1=1 1*2=2
1*3=3 3*4=12
1+2+12=15
*/
scala> rdd.aggregate(1)((_*_),(_+_))
res1: Int = 15
注意:这是rdd的aggregate方法,与scala不同的是zeroValue还需要传递给combOP
10)fold(zeroValue)(func)
折叠操作,aggregate 的简化操作,相当于seqop 和 combop是一样的操作
11)saveAsTextFile(path)
将数据集的元素以 textfile 的形式保存到 HDFS 文件系统或者其他支持的文件系统,对于每个元素,Spark 将会调用 toString 方法,将它装换为文件中的文本
12)saveAsSequenceFile(path)
将数据集中的元素以 Hadoop sequencefile 的格式保存到指定的目录下
13)saveAsObjectFile(path)
用于将 RDD 中的元素序列化成对象,存储到文件中
14)countByKey()
针对 (K,V) 类型的 RDD,返回一个 (K,Int) 的 map,表示每一个 key 对应的元素个数。
scala> var rdd = sc.parallelize(List((1,5),(1,6),(1,7),(2,8),(2,9),(3,10)))
rdd: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[2] at parallelize at :24
scala> rdd.countByKey()
res3: scala.collection.Map[Int,Long] = Map(2 -> 2, 1 -> 3, 3 -> 1)
15)foreach(func)
在数据集上的每一个元素运行 func 函数
scala> val rdd = sc.parallelize(Seq(1,2,3,4))
rdd: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[1] at parallelize at :24
scala> rdd.collect.foreach(print)
1234
//collect会返回driver,而直接调用foreach会将结果返回给对应Executor,可在webUI查看
scala> rdd.foreach(print) 16)数值RDD的统计操作

2.2.3、控制
Spark 速度非常快的原因之一,就是在不同操作中可以在内存中持久化或缓存个数据集。当持久化某个 RDD 后,每一个节点都将把计算的分片结果保存在内存中,并在对此 RDD 或衍生出的 RDD 进行的其他动作中重用。这使得后续的动作变得更加迅速;缓存是 Spark 构建迭代式算法和快速交互式查询的关键。如果一个有持久化数据的节点发生故障,Spark 会在需要用到缓存的数据时重算丢失的数据分区。如果希望节点故障的情况不拖累执行速度,也可以把数据备份到多个节点上。
持久化和缓存是懒执行的
1)缓存
缓存有两个操作:
//默认只在内存中缓存
def persist(): this.type = persist(StorageLevel.MEMORY_ONLY)
//即只在内存中缓存
def cache(): this.type = persist()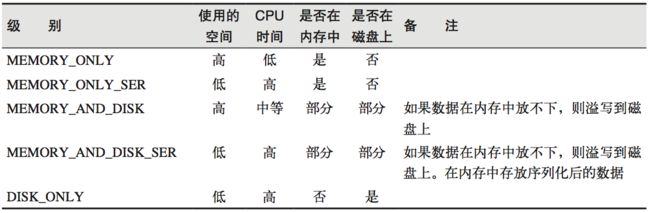
在存储级别的末尾加上“_2”来把持久化数据存为两份,默认副本数为1
scala> val cache = rdd.map(_.toString+"["+System.currentTimeMillis+"]")
cache: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[3] at map at :26
scala> cache.collect
res3: Array[String] = Array(1[1564891187941])
scala> cache.collect
res4: Array[String] = Array(1[1564891189866])
scala> cache.cache
res5: cache.type = MapPartitionsRDD[3] at map at :26
scala> cache.collect
res6: Array[String] = Array(1[1564891213286])
scala> cache.collect
res8: Array[String] = Array(1[1564891213286])
2)检查点
在hdfs中检查点机制是为了防止editlog文件过长导致恢复时间过长,类似的,rdd中的检查点机制是为了防止lineage 过长会造成容错成本过高,如果之后有节点出现问题而丢失分区,从做检查点的 RDD 开始重做 Lineage,就会减少开销。检查点会将数据写入到 HDFS
cache 和 checkpoint 区别:缓存把 RDD 计算出来然后放在内存中,但是 RDD 的依赖链不会丢掉,当某个 executor 宕机了, cache 中的 RDD 就会丢掉, 需要通过依赖链重放计算出来;而checkpoint 是把 RDD 保存在 HDFS 中,是多副本可靠存储,所以依赖链就可以丢掉了,就斩断了依赖链, 是通过复制实现的高容错。
适合使用检查点机制场景:
- DAG 中的 Lineage 过长,如果重算,则开销太大。检查见会切断之前的依赖关系
- 在宽依赖上做 checkpoint 获得的收益更大
scala> val data = sc.parallelize(1 to 100,5)
data: org.apache.spark.rdd.RDD[Int] = ParallelCollectionRDD[5] at parallelize at :24
scala> val faltMapRDD = rdd.flatMap(x=>Seq(x,x))
faltMapRDD: org.apache.spark.rdd.RDD[Int] = MapPartitionsRDD[6] at flatMap at :26
//设置检查点在hdfs上的存储位置
scala> sc.setCheckpointDir("hdfs://master1:9000/checkpoint/")
scala> faltMapRDD.checkpoint()
scala> faltMapRDD.dependencies.head.rdd
res13: org.apache.spark.rdd.RDD[_] = ParallelCollectionRDD[2] at parallelize at :24
//懒执行
scala> faltMapRDD.take(1)
res14: Array[Int] = Array(1)
scala> faltMapRDD.dependencies.head.rdd
res15: org.apache.spark.rdd.RDD[_] = ReliableCheckpointRDD[7] at take at :29
persist(DISK_ONLY)与checkpoint()区别:
前者虽然可以将RDD的partition持久化到磁盘,但该 partition由blockManager管理。一旦driverprogram执行结束,也就是executor所在进程 CoarseGrainedExecutorBackend stop,blockManager也会stop被cache到磁盘上的RDD也会被清空(整个 blockManager使用的local文件夹被删除);而 checkpoint将RDD持久化到HDFS或本地文件夹,如果不手动删除,hdfs文件不会消失
3、RDD算子练习案例
3.1、求百年来降水量TOP10
计算俄罗斯100多年的降水总量,并列出降水量最多的十年,显示排名
数据格式:

20674 1936 1 1 0 -28.0 0 -24.9 0 -20.4 0 0.0 2 0 OOOO
/*0.气象站编码
1.年
2.月
3.日
4.空气温度质量标记
5.每日最低温度
6.每日最低温度标记:0表示正常,1表示是存疑,9表示异常或无观测值
7.每日平均温度
8.每日平均温度标记:0表示正常,1表示是存疑,9表示异常或无观测值
9.每日最高温度
10.每日最高温度标记:0表示正常,1表示是存疑,9表示异常或无观测值
11.每日降水量
12.每日降水量标记:0表示降水量超过0.1mm,1表示数天的统计量,2表示无观察值,2表示降水小于0.1mm
13.每日降水量标记:0表示正常,1表示是存疑,9表示异常或无观测值
14.数据标记:4位,AAAA表示使用新版数据规范;oooo表示数据比较值不变;RRRR表示数据比较值可变
*/1、加载数据,进行数据清洗(过滤不符合条件的数据,包括:数据完整度、准确度);字段之间空白数量不确定 ,由于有些观察站数据缺失或异常需要过滤
2、获取年份和降水量,并将对年份归约计算总降水量;
3、按降水量进行排序(降序操作)
4、获取降水量最多的前十年
5、将最终结果输出到本地磁盘
val conf = new SparkConf().setMaster("local").setAppName("降雨量")
val sc = new SparkContext(conf)
val loadrdd = sc.textFile("hdfs://master1:9000/ussr/*")
val filrdd = loadrdd.map(x=>x.trim().replace("\\s+")
.filter(_.length==15)
.filter(_(13)!="9")
.filter(_(11)!="999.9")
val sumrdd= vilrdd.map(x=>(x(1),x(11).toDouble)).reduceByKey(_+_)))
val sortrdd = year_jyl.map(_.swap).sortByKey(false).map(_.swap)
val top10 = sortrdd.repartition(1).zipWithIndex()
.map(x=>(x._1,x._2.toInt+1)).filter(x=>x._2<11).map(_.swap)
top10.saveAsTextFile("hdfs://master1:9000/ussr/top10")3.2、二次排序
源文件
23 12
42 3
12 54
6 62
19 7
与MR中二次排序思路相同,自定义组合键,继承Ordered和Serializable或使用case class,然后重写compare方法
import org.apache.spark.{SparkConf, SparkContext}
//自定义比较类,继承Ordered和Serializable
class MySort (val first:Int,val second:Int) extends Ordered[MySort] with Serializable {
override def compare(that: MySort): Int = {
//第一个值不相等的时候,直接返回大小
if(this.first - that.first != 0){
this.first - that.first
}
else {
//第一个值相等的时候,比较第二个值
this.second - that.second
}
}
}
object Sort{
def main(args:Array[String]): Unit ={
val conf = new SparkConf().setAppName("Sort");
val sc = new SparkContext(conf);
val lines = sc.textFile("hdfs://master1:9000/sort.txt")
val pair = lines.map(line => (new MySort(line.split(" ")(0).toInt,line.split(" ")(1).toInt),line))
//对key进行排序,然后取value
val result = pair.sortByKey().map((_._2))
}
}也可以转化为pairRDD直接sortByKey即可
3.3、祖父-孙子关系
源文件:孩子-父母关系
Tom Lucy
Tom Jack
Jone Lucy
Jone Jack
Lucy Mary
Lucy Ben
Jack Alice
Jack Jesse
Terry Alice
Terry Jesse
Philip Terry
Philip Alma
Mark Terry
Mark Alma单"表"join即可,(某人,父母) join (某人,孩子) 得到(某人的父母,某人的孩子),即(祖父-孙子)。pairRDDjoin的条件为key值相同
//child-parent
val cp = sc.textFile("hdfs://master1:9000/child-parent.txt")
.map(_.split(" ")).map(x=>(x(0),x(1)))
//parent-child
val pc = cp.map(_.swap)
//parent-grandparent-child
val pgc = pc.join(cp);
//grandparent-child
val gc = pgc.values.repartition(1)3.4、PageRank
PageRank是一个依据网页之间互相的超链接进行计算排名值的算法。每个页面有两个指标:rank值和contribution值,rank值表示的是这个网页的重要程度,而contribution值由其他网页链接到该网页的rank值决定
举个例子,有A、B、C三个网页,箭头表示超链接指向

其中A指向了BC,相当于A的rank值平分贡献给了B和C。一个网页可以从地址栏输入网址进入,也可以通过其他网页通过连接进入,假设前者有0.15概率,后者有0.85概率。则第一轮C的rank值为=0.15+0.85*(1/2RankA+RankB),这样经过多轮迭代,rank值会越来越小,并逐渐收敛
其实也可以将PageRank理解为概率问题,比如当前在A页面,A页面有B和C两个页面的链接,那么分别有50%访问B和C,那么A对于C的贡献值为0.5*rankA,最终计算rankC时需要将直接通过地址栏访问的概率加上从其他页面链接过来的概率则为新的rank值
比如,源文件如下,表示 (PageID,(links))
//第一行即表示a有b、c、d的链接
a,b c d
b,c d e
c,a d
d,bimport org.apache.spark.{SparkConf, SparkContext}
object PageRank {
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("PageRank")
val sc = new SparkContext(conf)
sc.setLogLevel("ERROR")
//(pageID,(links))
val pl = sc.textFile("file:///D:/pagerank.txt").map(_.split(",")).map(x=>(x(0),x(1).split(" ")))
//假设初始rank值都为1,由于rank值每次迭代值都不同,设置为var类型
var ranks = pl.mapValues(x=>1.0)
for(i <- 1 to 1000){
//(pageID,单个网页->pageID的贡献值)
val r1 = pl.join(ranks).flatMap {
case (pageId, (links, rank)) => links.map(dest => (dest, rank/links.size))
}
//(pageID,所有网页->pageID的贡献值(概率)+地址栏访问贡献值(概率))
ranks = r1.reduceByKey(_+_).mapValues(v=>(v*0.85 + 0.15))
println(i+" "+ranks.collect().toList)
}
}
}//121次迭代达到最大精度
117 List((d,0.7008758710319657), (e,0.3901166560668069), (a,0.35903315451830553), (b,0.8474705508240242), (c,0.4918427165136602))
118 List((d,0.7008758710319657), (e,0.3901166560668069), (a,0.35903315451830553), (b,0.8474705508240241), (c,0.49184271651366007))
119 List((d,0.7008758710319656), (e,0.3901166560668068), (a,0.35903315451830553), (b,0.8474705508240241), (c,0.49184271651366007))
120 List((d,0.7008758710319656), (e,0.3901166560668068), (a,0.35903315451830553), (b,0.847470550824024), (c,0.49184271651366007))
121 List((d,0.7008758710319655), (e,0.3901166560668068), (a,0.35903315451830553), (b,0.847470550824024), (c,0.49184271651365996))
122 List((d,0.7008758710319655), (e,0.3901166560668068), (a,0.3590331545183055), (b,0.8474705508240239), (c,0.49184271651365996))
123 List((d,0.7008758710319655), (e,0.3901166560668068), (a,0.3590331545183055), (b,0.8474705508240239), (c,0.49184271651365996))4、PairRDD数据分区
注意:只有 Key-Value 类型的 RDD 才有分区的,非 Key-Value 类型的 RDD 分区的值是 None
每个 RDD 的分区 ID 范围:0~numPartitions-1,决定这个值是属于那个分区的
Spark 目前支持 Hash 分区和 Range 分区,用户也可以自定义分区,Hash 分区为当前的默认分区,Spark 中分区器直接决定了 RDD 中分区的个数、RDD 中每条数据经过 Shuffle 过程属于哪个分区和 Reduce 的个数。
4.1、获取/设置分区方式
可以通过使用 RDD 的 partitioner 属性来获取 RDD 的分区方式。它会返回一个 scala.Option 对象, 通过 get 方法获取其中的值。通过partitionBy函数可以设定分区器,同时可以设定分区数
scala> val pair = sc.parallelize(List((1,2),(3,4),(5,6)))
pair: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[8] at parallelize at :24
scala> pair.partitioner
res16: Option[org.apache.spark.Partitioner] = None
scala> val partitioned = pair.partition
partitionBy partitioner partitions
scala> val partitioned = pair.partitionBy(new org.apache.spark.HashPartitioner(3))
partitioned: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[9] at partitionBy at :26
scala> partitioned.partitioner
res18: Option[org.apache.spark.Partitioner] = Some(org.apache.spark.HashPartitioner@3)
4.2、HashPartitioner
class HashPartitioner(partitions: Int) extends Partitioner {
require(partitions >= 0, s"Number of partitions ($partitions) cannot be negative.")
def numPartitions: Int = partitions
//分区方式,返回分区号,0~numPartition-1之间
def getPartition(key: Any): Int = key match {
case null => 0
case _ => Utils.nonNegativeMod(key.hashCode, numPartitions)
}
//判断两个RDD之间的分区器是否相同,若相同判断分区数是否相同,只有这两者相同可视为equal
override def equals(other: Any): Boolean = other match {
case h: HashPartitioner =>
h.numPartitions == numPartitions
case _ =>
false
}
//对于给定的 key,计算其 hashCode,并除以分区的个数取余
//如果余数小于 0,则用 余数+分区的个数,最后返回的值就是这个 key 所属的分区 ID
override def hashCode: Int = numPartitions
}
def nonNegativeMod(x: Int, mod: Int): Int = {
val rawMod = x % mod
rawMod + (if (rawMod < 0) mod else 0)
}scala> val pair = sc.parallelize(List((1,2),(3,4),(5,6),(6,7)))
pair: org.apache.spark.rdd.RDD[(Int, Int)] = ParallelCollectionRDD[11] at parallelize at :24
scala> val partitioned = pair.partitionBy(new org.apache.spark.HashPartitioner(2))
partitioned: org.apache.spark.rdd.RDD[(Int, Int)] = ShuffledRDD[12] at partitionBy at :26
//分区0:6%2=0
//分区1:1%2=1,3%2=1,5%2=1
scala> partitioned.glom.collect
res20: Array[Array[(Int, Int)]] = Array(Array((6,7)), Array((1,2), (3,4), (5,6)))
4.3、RangePartitioner
HashPartitioner 分区弊端:可能导致每个分区中数据倾斜,极端情况下会导致某些分区拥有 RDD 的全部数据。
RangePartitioner 分区优势:尽量保证每个分区中数据量的均匀,而且分区与分区之间是有序的,一个分区中的元素肯定都是比另一个分区内的元素小或者大。但是分区内的元素是不能保证顺序的。简单的说就是将一定范围内的数映射到某一个分区内。
RangePartitioner 作用:将一定范围内的数映射到某一个分区内,在实现中,分界的算法尤为重要。用到了水塘抽样算法。
4.4、自定义分区器
要实现自定义的分区器,需要继承 org.apache.spark.Partitioner 类并实现下面3个方法
//返回创建出来的分区数
numPartitions: Int
//返回给定键的分区编号(0到numPartitions-1)
getPartition(key: Any): Int
//Spark 需要用这个方法来检查你的分区器对象是否和其他分区器实例相同,以判断两个RDD的分区方式是否相同
equals()
import org.apache.spark.Partitioner
class MyPartition(numPars:Int) extends Partitioner {
override def numPartitions: Int = numPars
//Key%分区数为分区号
override def getPartition(key: Any): Int = {
val code = key.toString.toInt%numPars
code
}
override def equals(other: scala.Any): Boolean = other match {
case mp: MyPartition => mp.numPars == numPars
case _ => false
}
}5、共享变量
5.1、广播变量
广播变量通常用来高效分发较大的对象,它可以让程序向所有工作节点发送一个较大的只读值,以供多个Executor使用。
传统方式下,Spark 会自动把闭包中所有引用到的变量发送到工作节点上。虽然这很方便,但也很低效。原因有二:首先,默认的任务发射机制是专门为小任务进行优化的;其次,事实上你可能会在多个并行操作中使用同一个变量,但是 Spark 会为每个任务分别发送。
//通过对一个类型 T 的对象调用SparkContext.broadcast创建出一个 Broadcast[T] 对象。任何可序列化的类型都可以这么实现。
scala> val broadcastVar = sc.broadcast(Array(1, 2, 3))
broadcastVar: org.apache.spark.broadcast.Broadcast[Array[Int]] = Broadcast(35)
//通过 value 属性访问该对象的值
scala> broadcastVar.value
res33: Array[Int] = Array(1, 2, 3)
//变量只会被发到各个节点一次,应作为只读值处理(修改这个值不会影响到别的节点)在SparkContext.hadoopFile()中广播了10kb左右的hadoop配置文件,这已经相当大了所以需要广播它
// A Hadoop configuration can be about 10 KB, which is pretty big, so broadcast it.
val confBroadcast = broadcast(new SerializableConfiguration(hadoopConfiguration))5.2、累加器
累加器用来对信息进行聚合。通常在向 Spark 传递函数时,比如使用 map() 函数或者用 filter() 传条件时,可以使用驱动器程序中定义的变量,但是集群中运行的每个任务都会得到这些变量的一份新的副本,更新这些副本的值也不会影响驱动器中的对应变量。 如果我们想实现所有分片处理时更新共享变量的功能,那么可以使用累加器
累加器有两种,longAccumulator和doubleAccumulator,分别用来处理long类型和double类型数据;通过add(n)能进行+n,通过value属性可获得累加器的值,并且只有driver可以访问值,工作节点上的任务不能访问累加器的值。从这些任务的角度来看,累加器是一个只写变量。初始值为0
scala> val la = sc.longAccumulator
la: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 1706, name: None, value: 0)
scala> val ld = sc.doubleAccumulator
ld: org.apache.spark.util.DoubleAccumulator = DoubleAccumulator(id: 1707, name: None, value: 0.0)
scala> la.add(2)
scala> la.value
res28: Long = 2
例如统计文件中的空行数
scala> val notice = sc.textFile("./NOTICE")
notice: org.apache.spark.rdd.RDD[String] = ./NOTICE MapPartitionsRDD[40] at textFile at :32
scala> val blanklines = sc.longAccumulator(0)
blanklines: org.apache.spark.util.LongAccumulator = LongAccumulator(id: 1708, name: None, value: 0)
scala> val tmp = notice.flatMap(line => {
| if (line == "") {
| blanklines += 1
| }
| line.split(" ")
| })
tmp: org.apache.spark.rdd.RDD[String] = MapPartitionsRDD[41] at flatMap at :36
scala> tmp.count()
res31: Long = 3213
scala> blanklines.value
res32: Int = 171
参考资料
https://blog.csdn.net/u012990179/article/details/89578181
https://blog.csdn.net/houmou/article/details/52531205