HLS实现CNN
经过几天的研究,终于实现了CNN在FPGA上运行(无任何优化,后续会进行代码优化)
本次实现的网络为LeNet,具体结构为(28,28)的输入,经过32个5x5的卷积核后输出24x24x32的特征图,池化后输出12x12x32,第二次卷积运算为16个3x3x32的卷积核,输出10x10x16的特征图,池化后展开后成为400x1的向量,全连接到120个神经元,这120个神经元全连接到84个神经元,最后是10个输出神经元,代表10个类别(数字0-9).
由于绝大多数的计算量集中在两个卷积层,因此只将卷积层实现在FPGA上,全连接层有ARM CPU实现。
ZYNQ CPU代码如下:
#include HLS代码如下:
#include"cnn.h"
#include这是头文件:
#pragma once
#include运行结果:
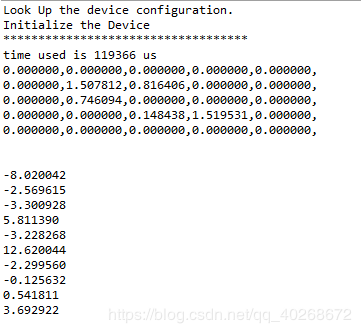
keras运行结果:

由于定点计算造成的误差尚可接受。
但是时间太慢,120ms一张图像,用c++实现用时75ms,而python keras(调用tensorflow)实现用时仅为650us左右,因此需要进一步对代码进行优化。