python爬取京东畅销榜(计算机类)图书信息(书名,作者,价格),并保存到excel表格
爬虫新手小白的第一次“半独立”爬虫,为什么是“半独立”呢?因为基本的代码块是从其他博客借鉴过来的,在此基础上加入了自己的思考和实现。
(后面的价格获取感觉自己走了很多弯路,想到一步写一步,肯定有其他更直接的方法)
首先是导入需要的库(numpy和matplotlib是打算后续可视化用的)
#-*- coding:utf-8 -*-
import requests
from bs4 import BeautifulSoup as BS
#import numpy as np
#import matplotlib.pyplot as plt
import pandas as pd
import re![]()
![]()
畅销榜书籍一共有5页,每一页链接的不同在于最后的编号,可以用format函数
#初始索引页面链接
index = r"https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-{0}#comfort"#获取页面内容
def readWebs(index):
try:
r = requests.get(index)
r.raise_for_status()
r.encoding = r.apparent_encoding
return r.text
except:
print('请求失败')#解析网页
def makeSoup(response):
soup = BS(response,'html.parser')
return soup#获取每一页的网页链接
def createPagesList(soup):
urlList = []
baseUrl = r"https://book.jd.com/booktop/0-0-0.html?category=3287-0-0-0-10001-{0}#comfort"
pageindex = soup.select('.p-wrap .p-num a')
#获取分页中最后一页的页码
num = int(pageindex[-2].text)
for i in range(1,num+1,1):
#生成网页链接
url = baseUrl.format(str(i))
urlList.append(url)
return urlList#还是获取每一页的网页链接,参数为初始索引链接,避免运行顺序出错
def getUrls(index):
res = readWebs(index)
soup = makeSoup(res)
urllist = createPagesList(soup)
return urllist查看页面源代码知书籍信息所在类和标签


#获取相关的书籍信息
def parseBooks(soup):
books = []
bookInfo = soup.select('.mc .clearfix li')
for book in bookInfo:
bookName = book.select('.p-detail a')[0]['title']
bookAuthor = book.select('.p-detail dl dd a')[0]['title']
#有些书名后面带有(与书名无关的内容)
bookName = bookName.split('(')[0]
bookName = bookName.split('(')[0]
bookName = bookName.split('【')[0]
#将书名和出版社保存到列表中
books.append(bookName)
books.append(bookAuthor)
return books#在循环中分别获取每个页面的书本信息,合并到一个列表中
pagelist = getUrls(index)
booklist = []
for url in pagelist:
res = readWebs(url)
soup = makeSoup(res)
books = parseBooks(soup)
booklist.extend(books)bookname= []
bookauthor = []
for i in range(0,len(booklist),2):
name = booklist[i]
author = booklist[i+1]
#price = booklist[i+2]
bookname.append(name)
bookauthor.append(author)查看价格信息时发现价格为空
![]()
查了很久资料,原来价格动态加载,要想服务器请求
我用的是火狐浏览器,右键点击查看元素,点击网络然后刷新页面
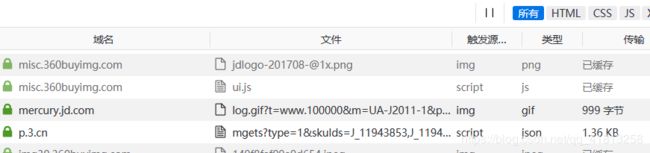
在上面的文件中找到
![]()
点击消息头可以看到请求网址

点击响应可以看到书籍的信息,id是每本书的id号,p是价格

观察发现,每本书的价格请求链接只有后面的‘skuIds’不同,而且就是书籍的id号,我的想法是先获得每一本书的id号,然后获得每一本书的价格请求链接,接着获取每一本书的价格。
想要获取每本书的id号,看看能不能从源代码中发现什么,果然在a标签的href属性中有一个链接,里面就包含了id号,把它提取出来,再利用正则表达式提取id就行啦!!!(说起来简单,可是花费我老多时间了.....哇)

下面来看获取id的代码
#获取每本一书的id号,存入一个列表
def get_bookid(soup):
idlists = []
bookids = soup.select('.mc .clearfix li')
for bookid in bookids:
bklist = bookid.select('.p-detail a')[0]['href']
idlists.append(bklist)
lists = []
for idlist in idlists:
idl= re.findall(r"\d{8}",idlist) #正则表达式匹配id
lists.append(idl)
return lists得到的id是列表形式的,需要转化为字符串
BookId = []
pagelist = getUrls(index)
res = readWebs(index)
for url in pagelist:
soup = makeSoup(res)
lists0 = get_bookid(soup)
lists = sum(lists0,[]) #将列表里嵌套的列表元素转化为字符串形式
for i in range(0,20):
BookId.append(lists[i])获得id之后,放入请求链接的尾部,还是用format()
price_reqs = []
price_urlList = []
base_priceUrl = 'https://p.3.cn/prices/mgets?&skuIds=J_{0}' #请求价格链接,动态链接
for i in range(0,len(BookId),1):
price_url = base_priceUrl.format(BookId[i])
url_session = requests.Session()
price_req = url_session.get(price_url).text
price_reqs.append(price_req)获得价格
bookPrice = []
for price_req in price_reqs:
bookPrice.append(re.findall(r'"p":"(.*?)"', price_req))然后将书名作者价格读入pandas中,方便后续处理
#将数据读入pandas中
df_name = pd.DataFrame(bookname, columns=['书名'])
df_author = pd.DataFrame(bookauthor, columns=['作者'])
df_price = pd.DataFrame(bookPrice, columns=['京东价'])
df_book = df_name.join(df_author)
df_book = df_book.join(df_price)到这里就差不多就完成啦,输出结果
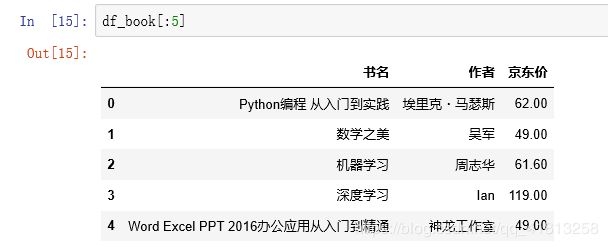
最后还可以将数据保存到excel表格中
import xlrd
import xlwt
myxls=xlwt.Workbook(encoding='utf-8')
sheet1=myxls.add_sheet('books',cell_overwrite_ok=True)
#sheet1.write(0,0,'书名')
#sheet1.write(0,1,'作者')
#sheet1.write(0,2,'京东价')
for i in range(0,len(bookname)):
sheet1.write(i,0,bookname[i])
sheet1.write(i,1,bookauthor[i])
sheet1.write(i,2,bookPrice[i])
myxls.save('books22.xlsx')
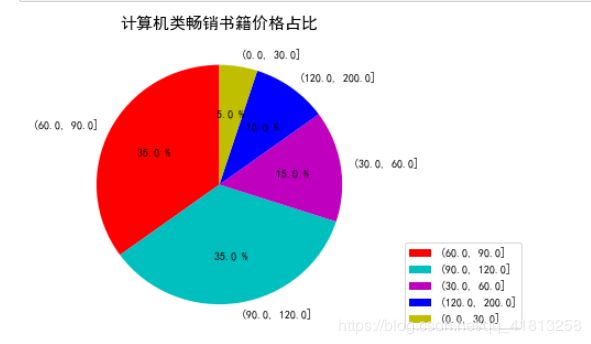
由于爬取的书籍的数量和信息都很少,不好做可视化,简单地画一个饼图,意思一下
import numpy as np
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']='SimHei' #设置中文字体为黑体,防止中文乱码
plt.rcParams['axes.unicode_minus']=False #解决负号'-'显示为方块的问题由于只有价格是数值型的,所以只对价格进行可视化。初始的价格类型为object类,直接画图会报错
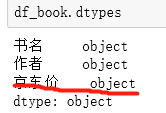
修改价格的类型为浮点型:
df_book['京东价'] = df_book['京东价'].astype('float')
首先用离散化函数cut()把价格分为几个区间:
price=pd.cut(df_book.京东价,[0.0,50.0,80.0,100.0,120.0,200.0]).value_counts()
price然后画饼图:
y=price.values
plt.figure(figsize=(5,5))
plt.title('计算机类畅销书籍价格占比',fontsize=15)
patches,l_text,p_text=plt.pie(y,labels=data.index,autopct='%.1f %%',startangle=90,colors='rcmby')
for i in p_text:
i.set_size(10)
i.set_color('k')
for i in l_text:
i.set_size(10)
i.set_color('k')
plt.legend(loc='lower right', bbox_to_anchor=(1.5,0))
plt.show()结果:
待解决的问题:
每本书内容简介的爬取以及出版社的爬取,出版社的爬取与书名和作者类似,都是静态的,而内容简介与价格类似,都是动态。
1、爬取出版社遇到的问题:

作者和出版社的标签是相同的,用select方法提取,存储到一个列表中,
bookAuthor = book.select('.p-detail dl dd a')[0]['title']
bookPress = book.select('.p-detail dl dd a')[1]['title']问题是有的书籍中,作者有两个,一个著一个译,所以列表中索引[1]就是第二个作者,那么出版社就是索引[2],可是有些书又只有一个作者,循环就用不了了,那应该怎么准确的写信息所在的标签呢?暂时没有找到解决的办法。只能得到如下结果:
出版社不能准确提取
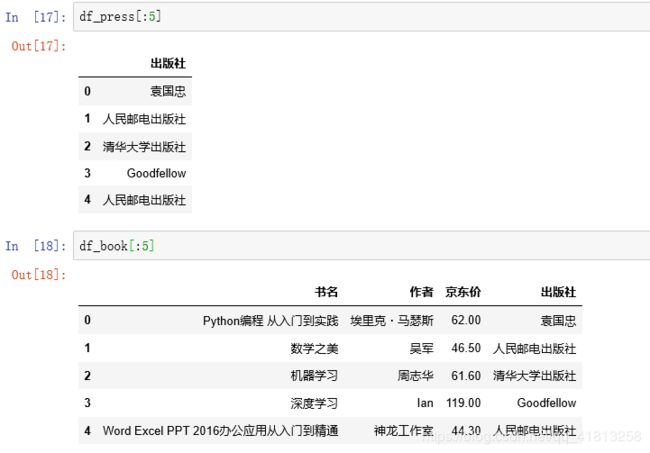
2、爬取内容简介遇到的问题:
要获取内容简介部分的源代码,也是有一个动态的请求链接,方法与价格一样,

select = etree.HTML(text)
#定位提取内容简介
content = select.xpath("//div[3]/div[2]/div//text()")不会从以下源代码中提取内容简介(只能用xpath),用xpath能提取出来,又有个问题是不同书所在的xpath路径又不一样,不能所有书的内容简介一起提取,不知道该怎么办了。等再学习了网页的知识再看能不能解决。

这是爬一本书的结果。。。。
