Retinanet原理介绍和基于pytorch的实现
Retinanet原理介绍和基于pytorch的实现
- 前言
- Retinanet介绍
- ResNet
- FPN
- SubNet
- anchor
- IoU
- Regression
- Focal Loss
- one-stage 和 two stage
- focal loss
- NMS
- Retinanet基于pytorch的实现
前言
最近两天在学Retinanet,发现网上对于retinanet方面的介绍比较笼统,而且很多都是在重复。于是打算基于自己的理解写一写retinanet的介绍,力求简单易懂,让很多像我一样的初学者能够一看就能理解
Retinanet介绍

如上图所示,Retinanet实际上就是ResNet + FPN + SubNet的网络组合。但是,单单这样的网络并不能够使它拥有出色的性能,它另外的‘法宝’就是focal loss公式。在这里,文章将会对ResNet、FPN、SubNet和focal loss做简单的介绍。当然,这篇文章的主题还是在介绍Retinanet上,所以这里的介绍仅仅是对各网络的功能和原理的一个大概讲解,想要学习得更详细的朋友可以在网上寻找针对相关知识的介绍。
ResNet
ResNet是一个解决了深度网络难以训练问题的网络模型。什么叫深度网络难以训练呢?下面一张图或许可以直观地说明这个问题:
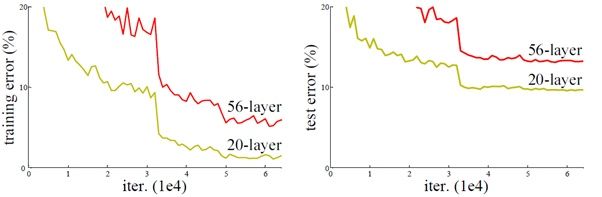
上图是,20层网络和56层网络在CIFAR10上的表现,我们可以很清楚地看到,56层的网络效果反而比20层的网络要差。显然,这个事实告诉我们,如果只是单纯地叠加网络,网络的性能并不会一直增加。至于原因,即使是像我们这样的新手也能猜到,应该是深度变大导致的梯度消失问题。
我想可能也正是基于这样的猜测,何恺明大神才设计出了ResNet这个网络架构
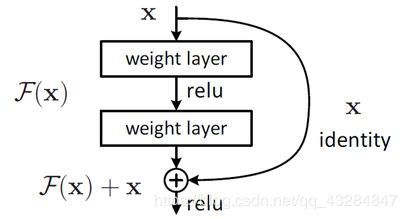
上图是ResNet的一个单元的概念图。简单来说,ResNet就是把每层的映射关系由output = f(input)改成了out = f(input) + input 仅从公式来看,我们也能够感性地认识到修改后的映射关系能够弱化梯度消失带来的负面效应。当然,由于这篇文章主旨并不是对ResNet的介绍,这里就不再对其原理进行详细说明。总之,我们应该知道,采用了ResNet,就可以使梯度消失的负影响大大减小。
FPN
有了ResNet,我们就可以放心地加深网络,从而获取更高维度的特征表达。那么,FPN是用来干什么的呢?

上图是网上很常见的FPN的模型图。我们可以看到,FPN的左半部分就是一个深度网络。那么根据图片我们也能猜到,所谓的FPN,其实是对深度网络输出的一系列特征图的“再加工”。
这里举一个简单的例子:
如果有一张图片,图片上是一个汉字“啸”,我们该怎么让计算机知道它是个“啸”呢?
当这张图片通过网络的第一层,计算机会得到一系列关于这个汉字的小特征,比如横竖撇捺。显然,仅凭这些特征,计算机也不能确定这个字到底是哪个字
当这张图片通过网络的第二层,计算机会得到关于这个汉字的更高程度的特征,比如说有横折,有长的一竖,也有短的一竖,当然,仅凭这样的信息,计算机还是没有办法下定论
当这张图片通过网络的第三层,像“口”这样的简单的局部结构已经能够被计算机识别了,但是更加复杂的“肃”还是没有办法识别出来
当这张图片通过网络的第四层,计算机终于也可以认识“肃”这部分了。到此,特征提取阶段结束,到了计算机下定论的阶段了。
如果我们只将最后一层输出的图片给计算机,计算机当然会很大概率上得出这个汉字是“肃”的结论,这是因为我们没有将低维度的特征图给计算机造成的
如果我们将第三层输出的图片一并给计算机,计算机也许会得出这个汉字是“啸”,但是计算机也有概率突然“失明”,只考虑了影响更大的“肃”的部分,继续得出这个汉字是“肃”的结论
那么如果我们把这两张图片结合在一起再给计算机呢?因为不同维度的特征结合到了一起,新产生的特征图信息更加丰富,计算机单独考虑某一维度的特征的概率也会更小,计算机得出正确结论的可能性也就增加了
也许这个例子举得并不是很恰当,不过我们也应该理解到FPN的作用:将不同维度的特征整合在一起,提高信息的丰富度
SubNet
Retinanet中的SubNet部分其实是分类和回归两个功能的整合。我们都知道,目标检测的任务实际上就是确定目标位置然后对目标进行分类。分类部分我们都很好理解,这里就不再着墨。下面文章将对回归部分做一个简单的介绍
anchor
什么是anchor?我们或许可以这样理解:
我们都有过剪切图片的经历。无论你是在电脑上还是在手机上,步骤都是一样的:你框选图片的一个区域,点击剪辑,框选的那个区域就成为了新的图片。在这里,anchor就是你用来框选区域的框。这个框框住了一个区域,我们就可以去计算这个区域的图像是背景还是我们要识别的物体,如果是物体,它到底是什么物体。
当然,计算机并不是我们,它不能够想框什么地方就框什么地方。那么怎么能保证我们能够框到我们想要的东西呢?很简单:在整个图片上拉满不同尺寸的框,总有框能够框到。只要框到了,我们就能够通过分类来识别物体到底是什么了。
问题是,计算机怎么知道我们框到了呢?
IoU
IoU是指anchor与正确的框住要识别的物体的方框的面积交并比。我们把这个比值作为anchor框住与否的标准。在Retinanet的论文中,IoU小于0.4的anchor被视为框住了背景,IoU大于0.5的anchor被视为框住了物体,而在0.4和0.5之间的anchor则因为难以下定论而直接被视为无效anchor。
这样一来,我们就能筛选出框住物体的anchor了。
理想条件下,我们希望anchor和正确的框重合。显然,这是很难做到的。不过anchor和正确的框尽可能地重合肯定是我们希望的。那么有没有办法能够调整anchor呢?
Regression
Regression,也就是回归,就是解决我们刚才提到的这个问题的方法。SubNet中的回归网络就是用来实现这个思想的
我们怎么用一个矩形去覆盖另外一个矩形呢?首先,我们要把这个矩形移动到另外一个矩形那里。其次,如果这个矩形的尺寸不足以覆盖,我们还要把这个矩形拉长拉宽,让它足以覆盖要覆盖的矩形
这就是我们调整Regression的思想:对anchor做平移和伸缩变换
首先我们应该知道的是,如何描述一个矩形。我们需要知道矩形的位置,这个位置可以用矩形的中心点坐标ctr_x,ctr_y来描述。我们还需要知道矩形的长(或者高)和宽,也就是height,width
因此,每一个anchor都可以用(ctr_x,ctr_y,height,width)这样一个向量来表示。那么对anchor的一系列变换就转换成了对这个向量中四个元素的变换。
在这里,我把四个公式给出来:
ctr_x’ = ctr_x + Δx
ctr_y’ = ctr_y + Δy
height’ = height * exp(Δheight)
width’ = width * exp(Δwidth)
这里说明一下,exp()保证了height和width的变化不会变成负数。如果你愿意,你也可以换成别的函数,只要你保证这个函数的值域在(0,+∞)就可以
所以,我们只需要知道四个Δ就好了,而这就是回归子网的工作。
Focal Loss
在经过了前面的ResNet特征提取,FPN特征整合,SubNet分类和回归后,我们终于得到了一系列的anchor。接下来就是分析误差了,这部分也是论文的主题:focal loss
one-stage 和 two stage
在介绍focal loss之前,我们先简单地介绍一下目标识别网络的两大派系:one-stage和two-stage。
前面提到过,目标检测的任务就是确定目标位置然后进行分类。这实际上包括了两次分类。第一次是背景和物体的粗分类,第二次是物体的细分类。
two-stage派严格按照流程走,在第一个stage中对所有的anchor进行粗分类,然后在第二个stage中进行细分类。大部分的背景anchor在第一个stage中就已经被筛选掉,这就大大降低了第二个stage的工作难度,所以two-stage派网络的精度比较高,但是因为过程复杂,所以速度也就慢了下来
one-stage派直接跳过了粗分类流程,直接对所有anchor进行细分类,显然,这大大增加了分类的难度。但是同时,因为流程的简化,one-stage派的网络在速度较有优势
focal loss
仔细观察Retinanet,我们不难发现,Retinanet是一个one-stage的网络,那么为什么它的精度竟然超过了two-stage呢?这就是focal loss的效果。
one-stage分类效果差是因为传统的交叉熵函数不能很好的处理数量庞大的背景anchor和数量稀少的目标anchor构成的“类别极不平衡”的情形。而focal loss函数就是根据这一点,对交叉熵函数进行了改良:
FL(pt)=−αt(1−pt)γlog(pt)
简单来说,就是在原来的交叉熵函数前加上了权重系数,使得数量少的数据拥有了更大的影响力,而数量大的数据的影响力则被削弱。这样一来,“类别极为不平衡”的情形所产生的负面影响就得到了减弱。这使得身为one-stage的Retinanet在精度上有了大步的提升
NMS
在测试网络的时候,我们会发现,网络最终给出的一系列anchor里,有很多anchor其实框住的是同一个物体,就像下图一样:

但实际上,我们想要的是下图的效果:

这就用到了非极大值抑制(NMS)
其实思想很简单。网络给出的一系列anchor的描述是(ctr_x,ctr_y,height,width,class,score)
我们要做的就是找到当前没有被处理过的score最高的anchor,然后剩下的所有anchor和这个anchor比较,当IoU大于一定值的时候,我们就认为这两个anchor重复了,自然,我们只需要保留score最高的anchor。
当所有的anchor都被操作一遍后,我们就得到了针对每一个目标的score最高的anchor,也就是第二张图的效果了
Retinanet基于pytorch的实现
github上给予pytorch实现的Retinanet的代码有很多,学长推荐我学习的是yhenon大佬的代码,因为他的代码是复现的最好的。但是yhenon的代码使用的pytorch版本还是0.4.1,不能够直接在最新版本的pytorch上运行,再加上代码的注释不是很多,作为初学者来说可能很难看懂。为了不让以后想学习Retinanet的朋友们再像我一样头疼三天,同时也为了检验自己的学习效果。我复写了一个基于pytorch 1.1.0的Retinanet代码。代码的思路基本上同yhenon的代码一样。不同之处在于:
1.我用新版本的函数替换了老版本的函数
2.自己手写实现了nms
3.添加了更多的注释,变量命名更容易让人看懂
4.调整了函数的架构,使其更加符合本文中第一张图片中展现的Retinanet结构
附网址:https://github.com/jkouubb/retinanet-based-on-pytorch-1.1.0
以上,祝大家学习顺利
最后的最后再推销一下自己的博客:jkouu.cn
主要写自己学习Java和安卓开发的学习笔记,不定期更新机器学习和算法相关,偶尔更新U3D开发