双注意力机制网络,attention在图像分割领域的进一步优化?
前言
在之前的博客中我们复现了self-attention,其在图像领域中应用大多数基于[H,W]这个维度,也就是图像的空间维度,本篇Dual Attention Network for Scene Segmentation,不仅在空间维度上的attention,也在channel的维度上进行attention。
目前的主流attention机制:
基于空间域的:self-attention,soft/hard attention
基于channel域的:SEnet SKnet 以及ResNest
本篇paper把self-attention在空间和channel域有效的结合起来。
算法框架
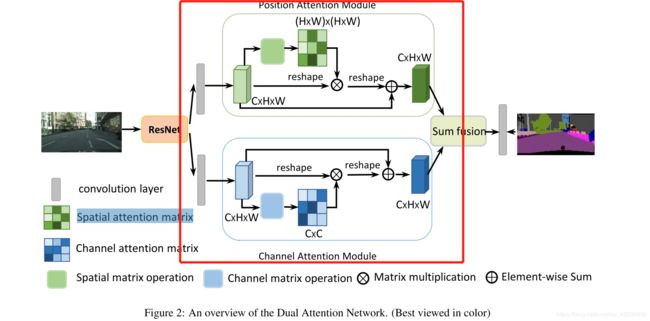
如图所示,此网络的大致结构如图,ResNet输出后的特征,经过我们的Dual Attention 模块,这里面为我们主要来实现红框里的算法框架
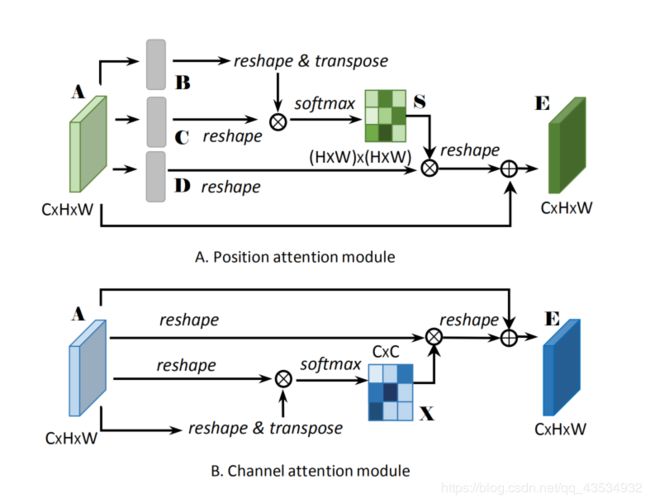
如上图所示self-attention分别在两个域当中的使用,其实最主要的区别是reshape&transpose之间的区别
代码实现
ResNet简单实现
def ResNet(x,kernel_size,channel):
layer1=tf.layers.conv2d(x,channel,kernel_size,strides=1, padding='same')
layer1=tf.contrib.layers.batch_norm(layer1)
layer1=tf.nn.relu(layer1)
layer1=tf.layers.conv2d(layer1,channel,kernel_size,strides=1, padding='same')
layer1=tf.contrib.layers.batch_norm(layer1)
layer1=tf.nn.relu(layer1)
result=tf.nn.relu(tf.layers.batch_normalization(layer1+x))
return result
position_attention实现
def position_attention(x,H,W,C):
x=tf.layers.conv2d(x,C*3,1,strides=1, padding='same')
Q,K,V=tf.split(x, 3, axis=3)
Q=tf.reshape(Q,[-1,H*W,C])
K=tf.reshape(K,[-1,H*W,C])
V=tf.reshape(V,[-1,H*W,C])
K=tf.transpose(K,[0,2,1])
result=tf.matmul(Q,K)
result=tf.nn.softmax(result)
V=tf.matmul(result,V)
V=tf.reshape(V,[-1,H,W,C])
return V
其中输入的HWC是x的后三个维度
channel_attention实现
def channel_attention(x,H,W,C):
x=tf.layers.conv2d(x,C*3,1,strides=1, padding='same')
Q,K,V=tf.split(x, 3, axis=3)
Q=tf.reshape(Q,[-1,H*W,C])
K=tf.reshape(K,[-1,H*W,C])
V=tf.reshape(V,[-1,H*W,C])
K=tf.transpose(K,[0,2,1])
result=tf.matmul(K,Q)
result=tf.nn.softmax(result)
V=tf.matmul(V,result)
V=tf.reshape(V,[-1,H,W,C])
return V
完整代码
# -*- coding: utf-8 -*-
"""
Created on Fri Jun 26 13:52:43 2020
@author: surface
"""
import tensorflow as tf
import math
def ResNet(x,kernel_size,channel):
layer1=tf.layers.conv2d(x,channel,kernel_size,strides=1, padding='same')
layer1=tf.contrib.layers.batch_norm(layer1)
layer1=tf.nn.relu(layer1)
layer1=tf.layers.conv2d(layer1,channel,kernel_size,strides=1, padding='same')
layer1=tf.contrib.layers.batch_norm(layer1)
layer1=tf.nn.relu(layer1)
result=tf.nn.relu(tf.layers.batch_normalization(layer1+x))
return result
def position_attention(x,H,W,C):
x=tf.layers.conv2d(x,C*3,1,strides=1, padding='same')
Q,K,V=tf.split(x, 3, axis=3)
Q=tf.reshape(Q,[-1,H*W,C])
K=tf.reshape(K,[-1,H*W,C])
V=tf.reshape(V,[-1,H*W,C])
K=tf.transpose(K,[0,2,1])
result=tf.matmul(Q,K)
result=tf.nn.softmax(result)
V=tf.matmul(result,V)
V=tf.reshape(V,[-1,H,W,C])
return V
def channel_attention(x,H,W,C):
x=tf.layers.conv2d(x,C*3,1,strides=1, padding='same')
Q,K,V=tf.split(x, 3, axis=3)
Q=tf.reshape(Q,[-1,H*W,C])
K=tf.reshape(K,[-1,H*W,C])
V=tf.reshape(V,[-1,H*W,C])
K=tf.transpose(K,[0,2,1])
result=tf.matmul(K,Q)
result=tf.nn.softmax(result)
V=tf.matmul(V,result)
V=tf.reshape(V,[-1,H,W,C])
return V
x = tf.placeholder(tf.float32,[None, 224, 224, 3])#输入图片大小
x1=tf.layers.conv2d(x,40,3,strides=1, padding='same')
Res1=ResNet(x1,3,40)
pos=position_attention(x1,224,224,40)
cha=channel_attention(x1,224,224,40)
dual=pos+cha```