文件描述符0/1/2的说明,标准输入文件,标准输出文件,标准出错输出文件,文件描述符1和2的区别,宏定义使用 (文件IO)【linux】(g)
标准输入文件,标准输出文件,标准出错输出文件,文件描述符1和2有什么区别,宏定义的使用
- 文件描述符0/1/2
- /dev/stdin:标准输入文件
- /dev/stdout:标准输出文件
- /dev/stderr:标准出错输出文件
- 文件描述符1和2有什么区别
- STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO
- 小结
文件描述符0/1/2
程序开始运行时,有三个文件被自动打开了,打开时分别使用了这三个文件描述符。依次打开的三个文件分别是/dev/stdin,/dev/stdout,/dev/stderr。
我们来在查看一下这三个文件:
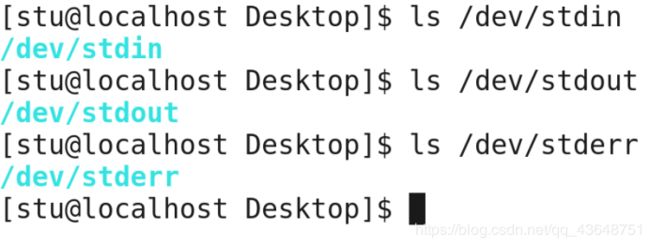
我们这里说明一下,凡是和驱动相关的文件都放在dev目录下面。
上面三个也只是链接文件:

链接文件的背后指向了

三个链接文件,背后又指向其他文件。
我们这里只看三个:
/dev/stdin:标准输入文件
程序开始运行时,默认会调用open("/dev/stdin", O_RDONLY)将其打开,返回的文件描述符是0
使用0这个文件描述符,可以从键盘输入的数据简单理解就是,/dev/stdin这个文件代表了键盘。
read(0, buf, sizeof(buf))实现的是什么功能
从键盘读取数据到到缓存buf中,数据中转的过程是:
read应用缓存buf <—————— open /dev/stdin时开辟的内核缓存 <——————键盘驱动程序的缓存 <——————键盘
我们使用代码进行说明:

执行结果为:
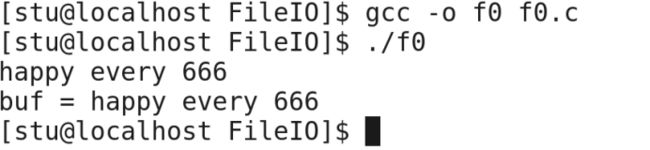
我们可以看到从键盘出入的过程已经打印结果。
**代码中return -1 并不是说main函数返回-1有什么具体的用处,而是要说明0表示正常返回,-1表示函数调用出错返回。**我们后面会具体说明main函数返回值。
能够像读普通文件一样读键盘在Linux下,应用程序通过OS API操作底层硬件时,都是以文件形式来操作的,不管是读键盘,还是向显示器输出文字显示,都是以文件形式来读写的,在Linux下有句很经典的话,叫做“在Linux下一切皆文件”。
为什么在我们的程序中,默认就能使用scanf函数从键盘输入数据?
我们在程序运行时默认就打开了代表了键盘/dev/stdin,打开后0指向这个打开的文件。scanf下层调用的就是read,read自动使用0来读数据,自然就可以从键盘读到数据。
scanf("%s", sbuf) C库函数
|
|
read(0, rbuf, ***)
我们从键盘读取数据时,可以直接调用read这个系统函数来实现,也可以调用scanf C库函数来实现,只不过在一般情况下,我们在实际编写应用程序时,调用的更多的还是scanf 这个c库函数,
原因如下:
调用库函数,可以让程序能够更好的兼容不同OS,能够在不同的OS运行
scanf在read基础上,加入更加人性化的、更加便捷的功能,比如格式化转换
直接使用read的缺点
首先我们必须清楚,所有从键盘输入的都是字符,从键盘输入100,其实输入的是三个字符’1’、‘0’、‘0’,因此使用read函数从键盘读数据时,读到的永远都是字符。
但是如果你实际想得到的是整形数的100,你就必须自己将’1’、‘0’、'0’转为整形的100。
我们通过代码说明:

执行结果为:
说明我们转化成功了。
Buf是字符串100 num是整形100
scanf的优点
scanf可以解决read的缺点,虽然scanf调用read时,从键盘读到的全部都是字符,但是你只要给scanf指定%d、%f等格式,scanf会自动的讲read读到的字符串形式的数据,转为整形或者浮点型数据。
scanf("%d", &a);
|
|
read(0, buf, …);
如果直接调用read读取,然后自己再来转换,相当于自己再实现scanf函数的基本功能。在有些时候,特别是我们说明到后面驱动时,有些情况还就只能使用read,不能使用scanf,我们在后面遇到的时候在博客中进行说明。
close(0)后,scanf还能工作吗?
我们通过代码测试:

执行结果为:

不等输入,直接出现错误。
我们只修改一部分来打印出来sacnf怎么出错的以及出错原因。
修改之后的部分为:

执行结果为:

我们可以看到,报错这是一个错误的描述符。
因为scanf底层调用要使用到0描述符,但是我们在代码中把描述符为0的文件关闭了。
scanf("%s", sbuf) C库函数
|
|
read(0, rbuf, ***)
/dev/stdout:标准输出文件
程序开始运行时,默认open("/dev/stdout", O_WRONLY)将其打开,返回的文件描述符是1为什么返回的是1,先打开的是/dev/stdin,把最小的0用了,剩下最小没用的是1,因此返回的肯定是1。
通过1这个文件描述符,可以将数据写(打印)到屏幕上显示简单理解是,
/dev/stdout这个文件代表了显示器。
write(1, buf, strlen(buf))实现的功能:
将buf中的数据写到屏幕上显示
数据中转的过程是:
write应用缓存buf ——————> open /dev/stdout时开辟的内核缓存 ——————> 显示器驱动程序的缓存 ——————>显示器显示
我们通过代码演示:

执行结果为:

在我们的程序中,默认就能使用printf打印数据到显示器。
因为程序开始运行时,就默认打开了代表了显示器/dev/stdout文件,然后1指向这个打开的文件。printf下层调用的是write函数,write会使用1来写数据,既然1所指文件代表的是显示器,自然就可以将数据写到显示器了。
printf("*****")
|
|
write(1, buf, count);
使用write函数,将整数65输出到屏幕显示,直接输出行不行
int a = 65;
write(1, &a, sizeof(a));
代码演示:

执行结果为:

我们可以看到打印结果为 A 而不是65
为什么输出结果是A?
人只看得懂字符,所以所有输出到屏幕显示的,都必须转成字符。所以我们输出时,输出的必须是文字编码,显示时会自动将文字编码翻译为字符图形。所以我们输出65时,65解读为A字符的ASCII编码,编码被翻译后的图形自然就是A。
怎么才能打印出65
如果要输出65,就必须将整形65转为’6’和’5’,输出这两个字符才行。输出’6’、‘5’时,其实输出的是’6’、‘5’这两个字符的ASCII编码,然后会被自动的翻译为6和5这两个图形。总之将整形65,转为字符’6’、'5’输出即可。
代码测试为:

执行结果为:

为什么printf会对wirte进行封装?
库函数可以很好的兼容不同的OS
封装时,叠加了很多的功能,比如格式化转换通过指定%d、%f等,自动将其换为对应的字符,然后write输出,完全不用自己来转换。printf使用%s、%c输出字符串和字符时,其实不用转,因为要输出的本来就是字符,printf直接把字符给write就行了,当然也不是一点事情也不做,还是会做点小处理的。
close(1),printf函数还能正常工作吗?
printf("*****")
|
|
write(1, buf, count);
和前面的0一样,读者可以参考描述符1的验证进行自行验证,我们这里直接说明,不能正常工作,printf函数和write 都不能正常进行,要使用问描述符为1 现在把1关闭了,当然不可以。Printf间接调用下层write(1) 1被关闭,write直接使用文件描述符1,1被关闭了。
/dev/stderr:标准出错输出文件
默认open("/dev/stderr", O_WRONLY)将其打开,返回的文件描述符是2
通过2这个文件描述符,可以将报错信息写(打印)到屏幕上显示。
代码演示:

执行结果为:

write(2, buf, sizeof(buf))实现的是什么功能将buf中的数据写道屏幕上,数据中转的过程是:
write应用缓存buf ——————> open /dev/stderr时开辟的内核缓存 ——————> 显示器驱动程序的缓存 ——————> 显示器
文件描述符1和2有什么区别
使用这两个文件描述符,都能够把文字信息打印到屏幕。如果仅仅是站在打印显示的角度,其实用哪一个文件描述符都能办到。
1,专用于打印普通信息
2,专门用于打印各种报错信息
使用write输出时:
+如果你输出的是普通信息,就使用1输出。
+如果你输出的是报错信息,就使用2输出。
printf和perror调用write时,使用的是什么描述符printf用于输出普通信息,向下调用write时,使用的是1。前面已经验证过,close(1)后,printf无法正常输出。
perror
perror专门用于输出报错信息的,因为输出的是报错信息,因此write使用的是2.验证:将2关闭,perror就会无法正常输出。
我们通过代码进行验证:

执行结果为:

我们先不说名success
现在perror输出成功了,我们现在关闭文件描述符2对应的文件。

执行结果为:
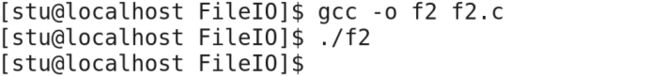
我们可以看到 perror没有输出,因为perror向下调用的是文件描述符2对应的文件,现在2关闭了,必然没有输出。
后面说到标准io时,还会讲到标准输入、标准输出、标准出错输出,到时候会介绍标准输出、标准出错输出的区别。
STDIN_FILENO、STDOUT_FILENO、STDERR_FILENO
系统为了方便使用0/1/2,系统分别对应的给了三个宏
0:STDIN_FILENO
1:STDOUT_FILENO
2:STDERR_FILENO
可以使用三个宏,来代替使用0/1/2。
这三个宏定义在了open或者read、write函数所需要的头文件中,只要你包含了open或者read、write的头文件,这三个宏就能被正常使用。
小结
小结的内容没有关于前面1/2/3文件描述符的总结,就是提醒一点,内容写的比较多,比较详细,但是都说的比较清楚,比较明白,建议读者找完整的时间看完并且如果没有理解的话多看几遍,如果哪里有什么问题或者有错误的地方,可以在评论区提出来,互相交流学习。