【scrapy】scrapy按分类爬取豆瓣电影基础信息
Scrapy简介
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
Scrapy入门请看官方文档:scrapy官方文档
本爬虫简介
本爬虫实现按分类爬取豆瓣电影信息,一次爬取一个分类,且自动切换代理池,防止ip在访问过多过频繁后无效。
分类如图所示:
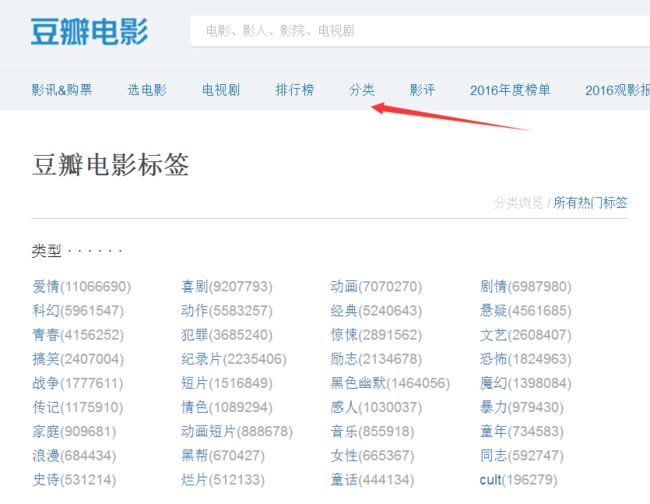
实现-scrapy中间件
scrapy基础框架参考上面的官方教程,搭建好基础框架后,本爬虫特殊之处在于为了防止爬虫被封,采用了轮换代理和agent的中间件。
agent轮换池:
简单的写一个user_agent_list来使得每次的agent不同,原理简单,代码如下:
class RotateUserAgentMiddleware(UserAgentMiddleware): #轮换代理agent
def __init__(self, user_agent=''):
self.user_agent = user_agent
def process_request(self, request, spider):
ua = random.choice(self.user_agent_list)
if ua:
#print '-----------------------Using user-agent:', ua, '------------------------'
request.headers.setdefault('User-Agent', ua)
# the default user_agent_list composes chrome,IE,firefox,Mozilla,opera,netscape
# for more user agent strings,you can find it in http://www.useragentstring.com/pages/useragentstring.php
user_agent_list = [ \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1" \
"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/19.77.34.5 Safari/537.1", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.9 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.0) AppleWebKit/536.5 (KHTML, like Gecko) Chrome/19.0.1084.36 Safari/536.5", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 5.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Macintosh; Intel Mac OS X 10_8_0) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1063.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1062.0 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.1) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.1 Safari/536.3", \
"Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.3 (KHTML, like Gecko) Chrome/19.0.1061.0 Safari/536.3", \
"Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24", \
"Mozilla/5.0 (Windows NT 6.2; WOW64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24"
]ip轮换池:
采用了一位大神cocoakekeyu写的中间件 Github地址,并不认识他,但是为他点赞。代码在这里不贴了,可以去Github看。
“一个用于scrapy爬虫的自动代理中间件。可自动抓取和切换代理,自定义抓取和切换规则。”
实现-爬虫实现
item.py
class DoubanItem(scrapy.Item):
movie_name = scrapy.Field()
movie_director = scrapy.Field()
movie_writer = scrapy.Field()
movie_starring = scrapy.Field()
movie_category = scrapy.Field()
movie_country = scrapy.Field()
#movie_language = scrapy.Field()
movie_date = scrapy.Field()
movie_time = scrapy.Field()
movie_star = scrapy.Field()
movie_5score = scrapy.Field()
movie_4score = scrapy.Field()
movie_3score = scrapy.Field()
movie_2score = scrapy.Field()
movie_1score = scrapy.Field()
movie_describe = scrapy.Field()
pass看这item名都不用我解释...
doubanlist_spider.py
先贴上代码:
class doubanlistSpider(scrapy.Spider):
name = "doubanlist"
allowed_domains = ["movie.douban.com"]
start_urls = [
"https://movie.douban.com/tag/%E5%8A%A8%E7%94%BB"
]
def parse(self, response):
for href in response.xpath('//a[@class="nbg"]/@href'):
url = href.extract()
yield scrapy.Request(url, callback=self.parse_each_movie)
next_page = response.xpath('//span[@class="next"]/a/@href').extract()
if next_page:
print '--------------Finding next page: [%s] --------------------------', next_page
yield scrapy.Request(next_page[0], callback=self.parse)
else:
print '--------------There is no more page!--------------------------'
def parse_each_movie(self, response):
item = DoubanItem()
item['movie_name'] = response.xpath('//span[@property="v:itemreviewed"]/text()').extract()
item['movie_director'] = response.xpath('//a[@rel="v:directedBy"]/text()').extract()
item['movie_writer'] = response.xpath('//span[@class="attrs"][2]/a/text()').extract()
item['movie_starring'] = response.xpath('//a[@rel="v:starring"]/text()').extract()
item['movie_category'] = response.xpath('//span[@property="v:genre"]/text()').extract()
#item['movie_language'] = response.xpath('//*[@id="info"]').re(r' (.*)
\n')[2]
item['movie_date'] = response.xpath('//span[@property="v:initialReleaseDate"]/text()').extract()
item['movie_time'] = response.xpath('//span[@property="v:runtime"]/text()').extract()
item['movie_star'] = response.xpath('//strong[@property="v:average"]/text()').extract()
item['movie_5score'] = response.xpath('//span[@class="rating_per"][1]/text()').extract()
item['movie_4score'] = response.xpath('//span[@class="rating_per"][2]/text()').extract()
item['movie_3score'] = response.xpath('//span[@class="rating_per"][3]/text()').extract()
item['movie_2score'] = response.xpath('//span[@class="rating_per"][4]/text()').extract()
item['movie_1score'] = response.xpath('//span[@class="rating_per"][5]/text()').extract()
item['movie_describe'] = response.xpath('//*[@id="link-report"]/span/text()').re(r'\S+')
check_item = response.xpath('//*[@id="info"]').re(r' (.*)
\n')[1]
result = self.check_contain_chinese(check_item)
if result:
item['movie_country'] = response.xpath('//*[@id="info"]').re(r' (.*)
\n')[1]
else:
item['movie_country'] = response.xpath('//*[@id="info"]').re(r' (.*)
\n')[2]
yield item
def check_contain_chinese(self, check_str):
for ch in check_str.decode('utf-8'):
if u'\u4e00' <= ch <= u'\u9fff':
return True
return False
def parse(self, response):从https://movie.douban.com/tag/%E5%8A%A8%E7%94%BB(某一特定分类)开始,爬取20条本页的电影,之后判定“下一页”按钮是否存在,如果存在则继续爬取下一页。
def parse_each_movie(self, response):对于每个电影详细页,爬取所需要的信息,全部使用xpath
中间一段是在爬取电影国家信息时,由于有不同情况的网页(可能是新老页面交替),需要不同处理,不然会爬到不正确的信息,xpath定位不准。
def check_contain_chinese:为了确定爬取的中文内容为中文字符串,需要进行判断。
总结
具体项目请查看:https://github.com/qqxx6661/scrapy_yzd
我爱周雨楠