大数据几大主流技术----HDFS操作原理
大数据:短时间快速产生大量多种多样有价值的信息。
当前谷歌三大论文:
- GFS -------------------->HDDS分布式文件系统(分布式的存储)
- MapReduce------------>分布式的处理
- BigData------------------>HBase (一种数据库)
解决数据量过大的问题:
1.垂直扩展
2.横向扩展(简单廉价的服务器或者pc端就可以)
Hadoop
Hadoop是由Apache基金会所开发的分布式系统基础架构,是一个能够对大量数据进行分布式处理的软件框架,具有高可靠性,高扩展性,高效性,高容错性,低成本的特点。
Hadoop 由许多元素构成。其最底部是 Hadoop Distributed File System(HDFS),它存储 Hadoop 集群中所有存储节点上的文件。HDFS(对于本文)的上一层是MapReduce 引擎,该引擎由 JobTrackers 和 TaskTrackers 组成。通过对Hadoop分布式计算平台最核心的分布式文件系统HDFS、MapReduce处理过程,以及数据仓库工具Hive和分布式数据库Hbase的介绍,基本涵盖了Hadoop分布式平台的所有技术核心。
YARN
Aache Hadoop YARN是一种新的Hadoop资源管理器,它是一个通用资源管理系统,课为上层应用提供统一的资源管理和调度,它的引入为集群再利用率,资源统一管理和数据共享等方面带来了巨大好处
Hive
hive是基于Hahoop的一个数据仓库工具,可以将结构化的数据文件映射为一张数据库表,并提供简单的sql查询功能,可以将sql语句转换为Mapreduce任务进行运行
HDFS
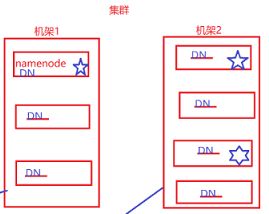
Hadoop分布式文件系统简称HDFS是运行在通用硬件上的分布式文件系统。是Apache Hadoop Core项目的一部门,它的主要目的是支持以流的形式访问写入的大型文件。它具有高容错性,可以部署在低廉的硬件上,并且提供高吞吐来访问应用程序的数据,适合超大数据集的应用程序。HDFS主从架构主要是有NameNode(主节点),DataNode(从节点),Client
NameNode(主节点)
NameNode是一个通常在HDFS实例中的单独机器上运行的软件,它负责管理文件系统名称空间和控制外部客户机的访问。
1.掌控并管理所有节点,管理元数据(描述数据)
2.接受client的请求
3.与DataNode进行通信
DataNode(从节点)
DataNode也是一个通常在HDF实例中的单独机器上运行的软件,通常以机架的形式组织,机架通过一个交换机将所有系统链接起来。
1.存储数据
2.想NameNode反应
3.响应client的操作
SPARK(计算引擎)
Apache Spark是专门大规模数据处理而设计的快熟通用的计算引擎,Spark是所开源的类Hadoop MapReduce的通用并行框架,是基于MapReduce算法实现的分布式计算。
Spark是一个通用引擎,可用它来完成各种各样的运算,包括SQL查询,文本处理,机器学习,而在Spark出现之前,需要借助各种引擎来分别处理这些需求。
Spark 提供了大量的库,包括Spark Core、Spark SQL(可以使用SQL处理)、Spark Streaming(流式处理)、MLlib(机器学习库)、GraphX。 开发者可以在同一个应用程序中无缝组合使用这些库。
文件的操作注意事项
以block块的形式将大文件进行相应的存储 (1.x 是64M 2.x/3.x 是128M 切割)
文件线性切割成快(block):偏移量offset (标记切割的位置 byte)
Block分散存储在集群节点中(存在DataNode中)
单一文件Block大小一致,文件与文件可以不一致
Block可以设置副本数,副本分散在不同节点中(副本数默认为三个)
副本数不要超过节点数量
文件上传可以设置Block大小和副本数(Block大小一经设置,不许改变)
只支持一次写入多次读取,同一时刻只有一个写入者(NameNode只许进行一个一个进行)
存储文件操作
1.client将文件进行切割 ,先将计算 文件大小/128M=block块数
2.向NameNode汇报
1)、块数
2)、文件大小
3)、文件权限
4)、文件的属主
5)、文件上传时间
3.client按照块的大小切割(默认128M)
4.client会向NameNode去申请资源
5.NameNode会返回一批负载不高的DataNode给client
6.client向DataNode里面发送block并且做好备份
7.DataNode存放block块之后会向NameNode汇报情况
读取文件的操作
1.NameNodei向client发送一个请求,client接受请求之后,向NameNode申请节点信息(blockid)
2.NameNode会向client发送一些节点信息
3.client获取节点信息之后DataNode拿取数据(就近原则)
备份机制
1. 集群内提交 在提交的节点上放置block(主节点所在服务器的从节点)
集群外提交 选择一个负载不高的节点进行存放
2.放置与第一个备份不同机架的任意节点上
3.放置在第二个机架不同的节点上
当存储文件的时候会用到----------pipeline管道
1.NameNode在返回给client一些DataNode的信息
2.client会和这些DataNode形成一个管道,并且将block切割成一个个ackpackage(64k)
3.DataNode会从管道中拿取相应的数据进行存储
4.当存储完成之后,DataNode会向NameNode经行汇报