Python标准库中的GUI界面
turtle(海龟绘图)的简单使用
导入turtle的语句
import turtlet( as 是给turtle起一个别名,起了别名之后,后续的代码都不能再使用turtle调用函数)
下面是turtle的具体使用方法
1.设置画笔的大小为10px
t.pensize(10)
2.设置画笔的颜色为绿色
t.color('green')
3.笔触移动、抬笔和落笔
#抬笔
t.penup()
#水平及垂直方向移动,x为负数,表示向x轴负方向移动,y同理。
t.goto(x, y)
t.goto(-260, 0)
#落笔
t.pendown()
4.让GUI界面一直显示, 所有执行的代码要写在此函数之前
比如:绘制 NEUSOFT
t.penup()
t.goto(-260, 0)
t.pd()
# 绘制 N
t.left(90)
t.forward(80)
t.right(145)
# 简写
t.fd(100)
t.lt(145)
t.fd(80)
t.right(90)
t.penup()
t.goto(-110, 80)
t.pd()
# 绘制 E
t.lt(180)
# 简写
t.fd(50)
t.lt(90)
t.fd(80)
t.lt(90)
t.fd(50)
t.penup()
t.goto(-120, 40)
t.pd()
t.lt(180)
t.fd(35)
#绘制U
t.penup()
t.goto(-80, 80)
t.pd()
t.lt(90)
t.fd(50)
t.circle(27, 180)
t.penup()
t.goto(-26, 80)
t.pd()
t.lt(180)
t.fd(50)
# 绘制 S
t.penup()
t.goto(15, 20)
t.pd()
t.circle(20, 270)
t.circle(-20, 270)
# 绘制 O
t.penup()
t.goto(90, 55)
t.pd()
t.fd(30)
t.circle(25, 180)
t.fd(30)
t.circle(25, 180)
# 绘制 F
t.penup()
t.goto(230, 80)
t.pd()
t.rt(90)
t.fd(50)
t.lt(90)
t.fd(80)
t.penup()
t.goto(180, 46)
t.pd()
t.lt(90)
t.fd(40)
# 绘制 T
t.penup()
t.goto(260, 80)
t.pd()
t.fd(50)
t.penup()
t.goto(285, 80)
t.pd()
t.rt(90)
t.fd(80)
# 让gui界面一直显示, 所有执行的代码要写在此函数之前
t.done()
代码执行结果如下:

掌握Python常用数据类型和语法
列表
列表与c语言中的数组很相似, 只不过可以存储不同类型的数据。列表的优点是灵活,缺点是效率太低,
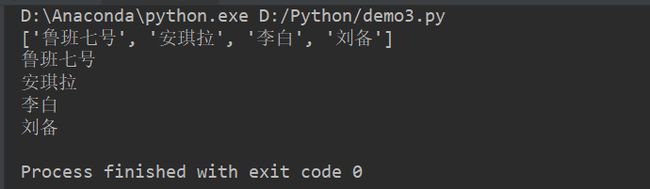
hero_name = ['鲁班七号', '安琪拉', '李白', '刘备']
# 输出
print(hero_name)
# 遍历
for hero in hero_name:
print(hero)
列表的常见操作有四种:
1.访问
# 列表名[索引]
print(hero_name[2])
2.添加
hero_name.append('后羿')
print('添加后的列表', hero_name)
3.修改
hero_name[1] = 1000
print('修改后的列表',hero_name)
4.删除
del hero_name[1]
print('删除后的列表',hero_name)
接下来是小练习
创建 [1, 2, 3......10] 这样的一个数字列表,步骤有两步
1.创建空列表
2.使用for 循环, 在循环中添加元素值
li = []
for i in range(1, 11):
li.append(i)
print(li)
字符串
字符串是 Python 中最常用的数据类型。我们可以使用单引号(')或双引号(")来创建字符串.
创建字符串很简单,只要为变量分配一个值即可。例如:
var1 = 'Hello'
var2 = "你好呀!"
字符串切片:切片是指对操作的对象截取其中一部分的操作,适用于列表。
切片的语法:[起始位置:终止位置:步长] 左闭右开
name = 'abcdefg'
print(name[1:4])
执行程序,会输出abc三个字符,如果想要输出a c e g,则可以用下面的语句
print(name[0:7:2]) #这是完整的写法,# 全切片的时候可以省略初始和终止位置,简单来写就是:
print(name[::2])
切片的常用方法有三种,去两端空格和替换和让列表变成字符串的方法
#去两端空格
name = ' abcdefg '
# 查看序列内元素的个数 len()
print(len(name))
name = name.strip()
print('去空格之后', len(name))
price = '$999'
price = price.replace('$', '')
print(price)
# 列表变成字符串的方法 join
li = ['a', 'b', 'c', 'd']
a = '*'.join(li)
print(a)
print(type(a))
代码执行结果如下

元组
Python 的元组与列表类似,不同之处在于元组的元素不能修改。
元组使用小括号,列表使用方括号。
元组创建很简单,只需要在括号中添加元素,并使用逗号隔开即可。
a = ('zhangsan', 'lisi', 'wangwu',1000)
print(a)
print(type(a))

访问元组
print(a[1])
修改元组
a[3] = 'zhaoliu'
元组中只包含一个元素时,需要在元素后面添加逗号,否则括号会被当作运算符使用:
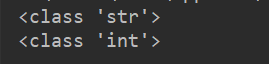
b = ('lisi') #是不是元组
c = (1000) #是不是元组
print(type(b))
print(type(c))
执行程序,此时b和c都不是元组类型
正确的语句应该像下面这样
b = ('lisi',) #是不是元组
c = (1000,) #是不是元组
print(type(b))
print(type(c))
执行程序,此时b和c的类型都为元组

字典
字典是另一种可变容器模型,且可存储任意类型对象。
字典的每个键值(key=>value)对用冒号(:)分割,每个对之间用逗号(,)分割,整个字典包括在花括号({})中 ,格式如下所示:
info = {'name':'李四', 'age':34, 'addr':'重庆市渝北区'}
print(len(info))
print(info)

1.字典的访问
print(info['name'])
2.修改
info['addr'] = '北京市朝阳区'
print('修改后字典', info)
3.增加
info['sex'] = 'female'
print('增加后字典', info
4.获取字典中所有的键
print(info.keys())
5.获取字典中所有的值
print(info.values())
6.获取字典中所有的key-value
print(info.items())
如果列表中装的是元组,可以把存放元组的列表转化为字典
d = [('name', '李四'), ('age', 34), ('addr', '北京市朝阳区'), ('sex', 'female')]
d1 = dict(d)
print(d1)
7.遍历字典
for k, v in info.items():
print(k, v)

集合
集合(set)是一个无序的不重复元素序列。
可以使用大括号 { } 或者 set() 函数创建集合,注意:创建一个空集合必须用 set() 而不是 { },因为 { } 是用来创建一个空字典。
创建格式:
parame = {value01,value02,...}
或者
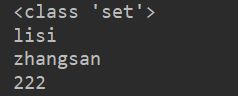
set = {'zhangsan', 'lisi', 222}
print(type(set1))
遍历集合
for x in set:
print(x)
列表的排序
li = []
for i in range(10):
li.append(i)
print(li)
from random import shuffle
shuffle(li)
print('随机打乱的列表', li)
li.sort(reverse=True)
print('排序后的列表', li)
执行程序,运行结果如下:

Python 函数
你可以定义一个由自己想要功能的函数,以下是简单的规则:
1.函数代码块以 def 关键词开头,后接函数标识符名称和圆括号 ()。
2.任何传入参数和自变量必须放在圆括号中间,圆括号之间可以用于定义参数。
3.函数的第一行语句可以选择性地使用文档字符串—用于存放函数说明。
4.函数内容以冒号起始,并且缩进。
5.return [表达式] 结束函数,选择性地返回一个值给调用方。不带表达式的return相当于返回 None。
Python 定义函数使用 def 关键字,一般格式如下:
# def 函数名(参数):
# 函数体
def sort_by_age(x):
return x['age']
练习1
stu_info = [
{"name": 'zhangsan', "age": 18},
{"name": 'lisi', "age": 30},
{"name": 'wangwu', "age": 99},
{"name": 'tiaqi', "age": 3},
]
print('排序前', stu_info)
# def 函数名(参数):
# 函数体
def sort_by_age(x):
return x['age']
# key= 函数名 --- 按照什么进行排序
# 根据年龄大小进行正序排序
stu_info.sort(key=sort_by_age, reverse=True)
print('排序后', stu_info)
练习2
name_info_list = [
('张三', 4500),
('李四', 9900),
('王五', 2000),
('赵六', 5500),
]
# 根据元组第二个元素进行正序排序
print('排序前', name_info_list)
# def 函数名(参数):
# 函数体
def sort_by_grade(x):
return x[1]
# key= 函数名 --- 按照什么进行排序
name_info_list.sort(key=sort_by_grade, reverse=True)
print('排序后', name_info_list)
本地文件读取
Python open() 方法用于打开一个文件,并返回文件对象,在对文件进行处理过程都需要使用到这个函数,如果该文件无法被打开,会抛出 OSError。
注意:使用 open() 方法一定要保证关闭文件对象,即调用 close() 方法。
open() 函数常用形式是接收两个参数:文件名(file)和模式(mode)。
具体代码如下:
f = open(file='./novel/threekingdom.txt', mode='r', encoding='utf-8')
data = f.read()
f.close
data = open(file='./novel/threekingdom.txt', mode='r', encoding='utf-8').read()
print(data)
with as 上下文管理器 不用手动关闭流
with open('./novel/threekingdom.txt', 'r', encoding='utf-8') as f:
data = f.read()
print(data)
文本的写入
文本写入既可以是字符串,也可以是txt文档,还可以是html文档等
txt = 'I like python'
with open('python.txt', 'w', encoding='utf-8') as f:
f.write(txt)
text1 = '''
请输入你的留言
全部留言
'''
with open('liuyan.html', 'w', encoding='utf-8') as f:
f.write(text1)
中文分词 jieba
安装jieba分词库
指定国内镜像安装
1.在用户目录下新建pip文件夹
2.新建pip.ini文件
添加:
[global]
index-url = http://mirrors.aliyun.com/pypi/simple/
[install]
trusted-host=mirrors.aliyun.com
在命令行输入pip install jieba
导入jieba分词
import jieba
三种分词模式
seg = '我来到重庆,这里的夏天很热,我们都要准备好防晒伞'
#1.精确模式 精确分词
seg_list = jieba.lcut(seg)
print(seg_list)
#2.全模式
seg_list = jieba.lcut(seg, cut_all=True)
print(seg_list)
#全模式是找出所有可能分词的结果
#缺点:冗余性大
#3.搜索引擎模式
seg_list = jieba.lcut_for_search(seg)
print(seg_list)
#先执行精确模式,再对其中的长词进行处理
三国演义小说分词
1.读取三国演义小说
2.分词
import jieba
with open('./novel/threekingdom.txt', 'r', encoding='utf-8') as f:
words = f.read()
print(len(words)) #字数
words_list = jieba.lcut(words)
print(len(words_list)) #分词后的词语数
词云的展示
词云的安装,步骤大致如下:
pip install wordcloud
本地安装Python库
whl文件 下载网址:https://www.lfd.uci.edu/~gohlke/pythonlibs/
导入词云wordcloud类
绘制词云
from wordcloud import WordCloud
text = 'He was an old man who fished alone in a skiff in the Gulf Stream and he had gone eighty-four days now without taking a fish. In the first forty days a boy had been with him. But after forty days without a fish the boy’s parents had told him that the old man was now definitely and finally salao, which is the worst form of unlucky, and the boy had gone at their orders in another boat which caught three good fish the first week. It made the boy sad to see the old man come in each day with his skiff empty and he always went down to help him carry either the coiled lines or the gaff and harpoon and the sail that was furled around the mast. The sail was patched with flour sacks and, furled, it looked like the flag of permanent defeat.'
wc = WordCloud.generate(text)
wc.to_file('老人与海。png')
今天出了很多问题,pip不能导入,解决方法是重新安装python版本,在安装页面勾选添加到path,但问题还没有彻底解决,绘制词云也失败了,明天也要继续努力!!!