Mark : Hadoop Raid-实战经验总结
分布式文件系统用于解决海量数据存储的问题,腾讯大数据采用 HDFS ( hadoop分布式文件系统)作为数据存储的基础设施,并在其上构建如 Hive 、 HBase 、Spark 等计算服务。
HDFS 块存储采用三副本策略来保证数据可靠性,随着数据量的不断增长,三副本策略为可靠性牺牲的存储空间也越来越大。如何在不降低数据可靠性的基础上,进一步降低存储空间成本,成为腾讯大数据迫切需要解决的问题。
我们对 facebook 版本的 hadoop raid 分析发现,还有很多细节需要优化改进,本文就 hadoop raid 存在的问题进行探讨,并对一些可以改进的地方给出思路。
首先介绍一下 hadoop raid 的原理和架构:
原理分析
HDFS Raid 以文件为单位计算校验,并将计算出来的校验 block 存储为一个 HDFS文件。 HDFS Raid 支持 XOR 和 RS 两种编码方式,其中 XOR 以位异或生成校验信息;而 RS 又称里所码,即 Reed-solomon codes ,是一种纠错能力很强的信道编码,被广泛应用在 CD 、 DVD 和蓝光光盘的数据纠错当中。
HDFS 为每个 block 创建 3 个副本,可以容忍 2 个 block 丢失,因此存储空间为数据量的 3 倍。而采用 RS 编码,如按条带( Stripe length )和校验块( Parity block )个数比例为 10,4 计算,则只需要 1.4 倍的存储开销,就可以容忍同一条带内任意 4 个block 丢失,即存储量可以节省 16/30 。
Hadoop Raid 架构
DRFS
l DRFS :应用 Raid 方案后的 HDFS
l RaidNode :根据配置路径,对需要 Raid 的文件( source file ),从 HDFS DataNode 中读取对应的数据块,计算出校验块文件( parity file ,所有校验块组成一个 HDFS 文件),并将 parity file 存储在 HDFS 中; RaidNode 周期性的检查源文件及校验块文件对应的 block 数据是否丢失,如有丢失,则重新计算以恢复丢失的 block
l Raid File System :提供访问 DRFS 的 HDFS 客户端,其在 HDFS Client 接口上进行封装,当读取已丢失或损坏的 block 时,通过对应的校验块计算恢复的 block 数据返回给应用,恢复过程对应用是透明的
l RaidShell : DRFS 管理工具,可手工触发生成 parity file 、恢复丢失 block 等
问题与优化
l 问题 1 集群压力增加
集群压力增加表现为 NameNode 元数据增多、访问量增加、 Raid 和数据恢复时集群网络及 IO 负载增加几个方面,具体如下:
其一, raid 过程中会生成校验文件以及目录结构,导致元数据增加。如下图所示,对于每一个原始文件,都会在目标目录生成一个对应的检验文件,造成元数据量double 。由于校验文件读操作远大于删除等更新操作,解决方案为对校验文件做 har打包,将目录打包成一个 har 文件,以节省元数据量。
其二, RaidNode 周期性的访问 NameNode ,查询哪些文件需要做 raid 、是否存在废弃的 parity file (源文件被删除,则对应的 parity file 已经无效了,需要清理掉)、是否存在 Missing Block 等,这些操作都对 NameNode 产生一定压力。解决方案为调整RaidNode 访问 NameNode 的频率,控制在可接受的范围。
其三,做 Raid 生成校验文件及恢复丢失的 block 时,需要读取相同 stripe 的多个block 数据,导致集群内网络及 IO 负载增加。解决方案为选择空闲时段进行操作,减少对现网生产环境的影响。
其四, Raid 完成后,源文件 block 副本数减少, job 本地化概率减小,同时增加了网络流量和 job 的执行时间。为减少影响,只对访问频率较低的冷数据做 Raid ,而冷数据的判定,则需要从数据生成时间、访问时间、访问次数综合考虑。
l 问题 2 集群性能下降
性能下降则包括块删除速度变慢、读取频繁移动的块速度变慢,具体如下:
其一, NameNode 应用 Raid 块放置策略,删除 block 需要考虑相同 stripe 的其他block 的位置情况,以保证同一 DataNode 上不会存储该 stripe 的多个 block ,避免由于该 DataNode 故障缺失过多的块,造成数据无法恢复的风险。另外,在集群启动时, NameNode 要重建元数据信息,同时对比 block 的实际副本数和配置值,用以删除和增加 block ;由于 Raid 块放置策略的引入,每个 block 的增加和删除都需要考虑相同 stripe 的其他 block 位置信息,这一过程非常耗时,导致 NameNode 启动变慢很多。
解决方案是,在启动时使用默认的块放置策略,保持启动过程同原有流程相同,待启动完成,再修改为 Raid 块放置策略,动态刷新到 NameNode 生效。
其二, RaidNode 周期性的扫描原始文件和检验文件,如发现同一 DataNode 上存储该 stripe 内的过多 block ,则将超出来的 block 迁移到其他 DataNode 上。RaidNode 的检查周期默认值为 10 分钟,然而块移动过程 NameNode 并不会及时清掉 block 同移出 DataNode 的映射关系,而要等到下次 DataNode 块上报,块上报的周期比较长,一般 2 个小时。这样在下次块上报之前, NameNode 中 block 映射的DataNode 会不断累积,直至遍布整个集群。客户端读取这个 block 数据就会因很多DataNode 上并不存在块文件而重试,导致性能下降。解决方案为调整 RaidNode 扫描周期,要大于 DataNode 的块上报周期,期间 NameNode 来修正 block 和 DataNode的映射关系。
l 问题 3 数据安全性问题
表现在 rebalance 不理解 raid 概念:
Rebalance 不理解 raid 的条带的概念,将 block 在集群中重新移动后,可能会导致相同 stripe 的多个 block 保存在相同的 DataNode 上,存在丢块的风险。解决方案为NameNode 增加 RPC 接口,查询 block 所属文件,进而结合 raid 块放置策略,将stripe 的多个 block 分散得更散。
l 问题 4 Raid 过程 Job 数据倾斜
RaidNode 提交 job 对多个源文件做 raid ,理想效果如图 (a) ,多个文件平均分配到每个 map 中 raid 操作,但执行过程中发现大部分 map 迅速完成,统计读取记录为 0,而另外少部分 map 执行时间较长。
分析流程发现, RaidNode 采用同 distcp 相同的方式,先将需要 raid 的文件列表,以 SequenceFile 格式写入 HDFS ,且每 10 个文件写入一次 SYNC 标识,分片时再将每个文件构造成 FileSplit 作为分片单元; map 读取输入使用SequenceFileRecordReader ,以 SYNC 标识为起止位置。以 (b) 图为例, map1 的起止位置跨越了 SYNC1 ,因读取的数据为 SYNC1 和 SYNC2 之间的 10 个文件列表,而其它 map 的起止位置在同一 SYNC 区间内,则读取数据为 0 ,这就是 job 倾斜的原因。
解决方案为每个文件后面都写入一次 SYNC 标识,多个文件就会平均分配到 map 中执行。而 SYNC 标识占用 20 个字节,且只在 job 执行结束 SequenceFile 就会清理掉,存储代价微乎其微。
学习大数据-需要了解RAID
简介
RAID是一个我们经常能见到的名词。但却因为很少能在实际环境中体验,所以很难对其原理 能有很清楚的认识和掌握。本文将对RAID技术进行介绍和总结,以期能尽量阐明其概念,科多大数据带你来学习学习。
RAID全称为独立磁盘冗余阵列(Redundant Array of Independent Disks),基本思想就是把多个相对便宜的硬盘组合起来,成为一个硬盘阵列组,使性能达到甚至超过一个价格昂贵、 容量巨大的硬盘。RAID通常被用在服务器电脑上,使用完全相同的硬盘组成一个逻辑扇区,因此操作系统只会把它当做一个硬盘。 RAID分为不同的等级,各个不同的等级均在数据可靠性及读写性能上做了不同的权衡。 在实际应用中,可以依据自己的实际需求选择不同的RAID方案。
标准RAID
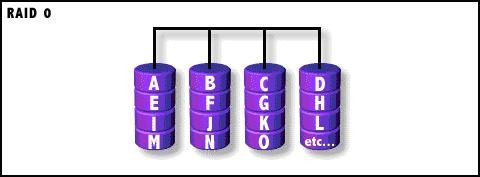
RAID 0
RAID0称为条带化(Striping)存储,将数据分段存储于 各个磁盘中,读写均可以并行处理。因此其读写速率为单个磁盘的N倍(N为组成RAID0的磁盘个数),但是却没有数 据冗余,单个磁盘的损坏会导致数据的不可修复。
大多数striping的实现允许管理者通过调节两个关键的参数来定义数据分段及写入磁盘的方式,这两个参数对RAID0的性能有很重要的影响。
STRIPE WIDTH
stripe width是指可被并行写入的 stripe 的个数,即等于磁盘阵列中磁盘的个数。
STRIPE SIZE
也可称为block size(chunk size,stripe length,granularity),指写入每个磁 盘的数据块大小。以块分段的RAID通常可允许选择的块大小从 2KB 到 512KB不等,也有更 高的,但一定要是2的指数倍。以字节分段的(比如RAID3)一般的stripe size为1字节或者 512字节,并且用户不能调整。 stripe size对性能的影响是很难简单估量的,最好在实际应用中依自己需求多多调整并观察其影响。通常来说,减少stripe size,文件会被分成更小的块,传输数据会更快,但是却需要更多的磁盘来保存,增加positioning performance,反之则相反。应该说,没有一个理论上的最优的值。很多时候,也要考虑磁盘控制器的策略,比如有的磁盘控制器会等等到一定数据量才开始往磁盘写入。
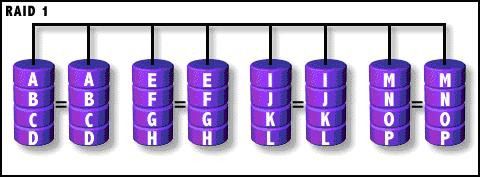
RAID 1
镜像存储(mirroring),没有数据校验。数据被同等地写入两个或多个磁盘中,可想而知,写入速度会比较 慢,但读取速度会比较快。读取速度可以接近所有磁盘吞吐量的总和,写入速度受限于最慢 的磁盘。 RAID1也是磁盘利用率最低的一个。如果用两个不同大小的磁盘建立RAID1,可以用空间较小 的那一个,较大的磁盘多出来的部分可以作他用,不会浪费。
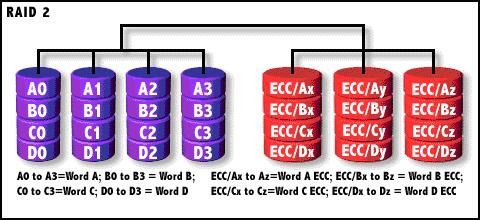
RAID 2
RAID0的改良版,加入了汉明码(Hanmming Code)错误校验。
汉明码能够检测最多两个同时发生的比特错误,并且能够更正单一比特的错误。汉明码的位数与数据的位数有一个不等式关系,即:
1
2^P ≥ P + D +1
P代表汉明码的个数,D代表数据位的个数,比如4位数据需要3位汉明码,7位数据需要4位汉 明码,64位数据时就需要7位汉明码。RAID2是按1bit来分割数据写入的,而P:D就代表了数据 盘与校验盘的个数。所以如果数据位宽越大,用于校验的盘的比例就越小。由于汉明码能够 纠正单一比特的错误,所以当单个磁盘损坏时,汉明码便能够纠正数据。
RAID 2 因为每次读写都需要全组磁盘联动,所以为了最大化其性能,最好保证每块磁盘主 轴同步,使同一时刻每块磁盘磁头所处的扇区逻辑编号都一致,并存并取,达到最佳性能。 如果不能同步,则会产生等待,影响速度。
与RAID0相比,RAID2的传输率更好。因为RAID0一般stripe size相对于RAID2的1bit来说 实在太大,并不能保证每次都是多磁盘并行。而RAID2每次IO都能保证是多磁盘并行,为了 发挥这个优势,磁盘的寻道时间一定要减少(寻道时间比数据传输时间要大几个数量级),所 以RAID2适合于连续IO,大块IO(比如视频流服务)的情况。
RAID 3
类似于RAID2,数据条带化(stripe)存储于不同的硬盘,数据以字节为单位,只是RAID3使用单块磁盘存储简单的 奇偶校验信息,所以最终磁盘数量为 N+1 。当这N+1个硬盘中的其中一个硬盘出现故障时, 从其它N个硬盘中的数据也可以恢复原始数据,当更换一个新硬盘后,系统可以重新恢复完整 的校验容错信息。
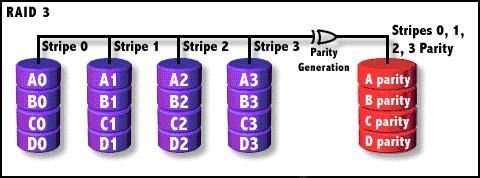
由于在一个硬盘阵列中,多于一个硬盘同时出现故障率的几率很小,所以一般情况下,使用 RAID3,安全性是可以得到保障的。RAID 3会把数据的写入操作分散到多个磁盘上进行,不管是向哪一个数据盘写入数据, 都需要同时重写校验盘中的相关信息。因此,对于那些经常需要执行大量写入操作的应用来 说,校验盘的负载将会很大,无法满足程序的运行速度,从而导致整个RAID系统性能的下降。 鉴于这种原因,RAID 3更加适合应用于那些写入操作较少,读取操作较多的应用环境,例如 数据库和WEB服务器等。
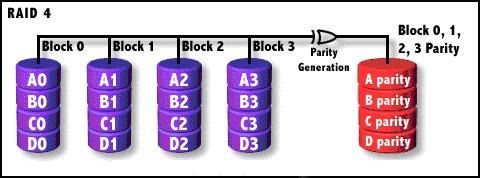
RAID 4
与RAID3类似,但RAID4是按块(扇区)存取。无须像RAID3那样,哪怕每一次小I/O操作也要涉 及全组,只需涉及组中两块硬盘(一块数据盘,一块校验盘)即可,从而提高了小量数据 I/O速度。
RAID 5
奇偶校验(XOR),数据以块分段条带化存储。校验信息交叉地存储在所有的数据盘上。
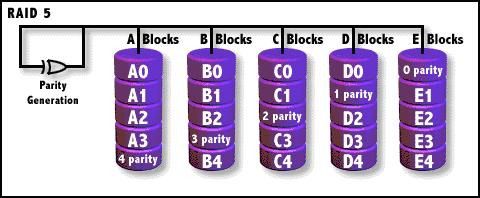
RAID5把数据和相对应的奇偶校验信息存储到组成RAID5的各个磁盘上,并且奇偶校验信息和 相对应的数据分别存储于不同的磁盘上,其中任意N-1块磁盘上都存储完整的数据,也就是 说有相当于一块磁盘容量的空间用于存储奇偶校验信息。因此当RAID5的一个磁盘发生损坏 后,不会影响数据的完整性,从而保证了数据安全。当损坏的磁盘被替换后,RAID还会自动 利用剩下奇偶校验信息去重建此磁盘上的数据,来保持RAID5的高可靠性。
RAID 5可以理解为是RAID 0和RAID 1的折衷方案。RAID 5可以为系统提供数据安全保障,但 保障程度要比镜像低而磁盘空间利用率要比镜像高。RAID 5具有和RAID 0相近似的数据读取 速度,只是因为多了一个奇偶校验信息,写入数据的速度相对单独写入一块硬盘的速度略慢。
RAID 6
类似RAID5,但是增加了第二个独立的奇偶校验信息块,两个独立的奇偶系统使用不同的算法, 数据的可靠性非常高,即使两块磁盘同时失效也不会影响数据的使用。但RAID 6需要分配给 奇偶校验信息更大的磁盘空间,相对于RAID 5有更大的“写损失”,因此“写性能”非常差。
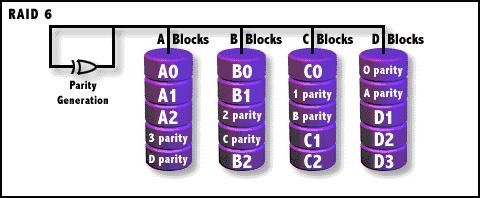
由图所知,每个硬盘上除了都有同级数据XOR校验区外,还有一个针对每个数据 块的XOR校验区。当然,当前盘数据块的校验数据不可能存在当前盘而是交错存储的。从数 学角度来说,RAID 5使用一个方程式解出一个未知变量,而RAID 6则能通过两个独立的线性 方程构成方程组,从而恢复两个未知数据。
伴随着硬盘容量的增长,RAID6已经变得越来越重要。TB级别的硬盘上更容易造成数据丢失, 数据重建过程(比如RAID5,只允许一块硬盘损坏)也越来越长,甚至到数周,这是完全不可接受的。而RAID6允许两 块硬盘同时发生故障,所以渐渐受到人们的青睐。
伴随CD,DVD和蓝光光盘的问世,存储介质出现了擦除码技术,即使媒介表面出现划痕,仍然可以播放,大多数常见的擦除码算法已经演变为上世纪60年代麻省理工学院林肯实验室开 发的Reed-Solomon码。实际情况中,多数RAID6实现都采用了标准的RAID5教校验比特和Reed-Solomon码。而纯擦除码算法的使用使得RAID 6阵列可以失效两块以上的硬盘,保护力度更强,有些实现方法提供了多种级别的保护,甚至允许用户(或存储管理员)指定保护级别。
混合RAID
RAID 01
顾名思义,是RAID0和RAID1的结合。先做条带(0),再做镜像(1)。
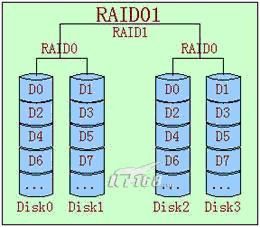
RAID 10
同上,但是先做镜像(1),再做条带(0)
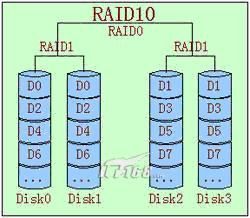
RAID01和RAID10非常相似,二者在读写性能上没有什么差别。但是在安全性上RAID10要好于 RAID01。如图中所示,假设DISK0损坏,在RAID10中,在剩下的3块盘中,只有当DISK1故障, 整个RAID才会失效。但在RAID01中,DISK0损坏后,左边的条带将无法读取,在剩下的3快盘 中,只要DISK2或DISK3两个盘中任何一个损坏,都会导致RAID失效。
RAID10和RAID5也是经常用来比较的两种方案,二者都在生产实践中得到了广泛的应用。 RAID10安全性更高,但是空间利用率低。至于读写性能,与cache有很大关联,最好根据实 际情况测试比较选择。
非标准RAID
DRFS
DRFS,即DistributedRaidFileSystem,是一种尝试将RAID与Hadoop的DFS结合起来的技术。 通常的HDFS在实践中需要将replication factor设为3以保证数据完整性,而如果利用 RAID的stripe和partity(奇偶校验)技术,将数据分为多个块,并且存储各个块的校验信 息(XOR或擦除码)。有了这些措施,块的副本数就可以降低并且保证同样的数据可靠性,就能节省相当一部 分的存储空间。
DRFS包含以下几个组件:
· DRFS client: 提供应用程序访问DRFS的接口,在发现读取到的文件有损坏时修复,整个操作对应用程序透明
· RaidNode: 创建,维护检验文件的daemon
· BlockFixer: 周期性地检查文件,重新计算校验和,修复文件.
· RaidShell: 类似于hadoop shell.
· ErasureCode: 即DRFS所使用的生成校验码的算法,可为XOR或者Reed-Solomon算法。 XOR仅能创建一个校验字节,而Reed-Solomon则可以创建无数位(位数越多,能恢复的数 据也越多),如果使用Reed-Solomon,replication甚至可以降为1,缺点是降低了数据读 写的并行程度(只能从单机读写)。
实现
软件实现
现在很都操作系统都提供了RAID的软件实现,主要由以下几个方面:
· 由软件在多个设备上创建RAID,比如linux上的mdadm工具.具体使用方法可查看参考链接中 的例子。
· LVM或者Veritas,虚拟卷管理工具.
· 文件系统实现 :btrfs,ZFS,GPFS.这些文件都可以直接管理多个设备上的数据,实 现了类似各级RAID的功能。
· 在已有文件系统之上提供数据校验功能的RAID系统(RAID-F)
固件/驱动实现
软件实现并总是与系统的启动进程兼容,硬件实现(RAID控制器)总是太贵并且都是厂商专有的技术,所以 有了一中混合的实现:系统启动时,由固件(firmware)来实现RAID,系统启动的差不多了,由驱动来管 理RAID。当然,这需要操作系统对这种驱动提供支持。