Hadoop与Spark的核心组件对比
一、Hadoop的核心组件
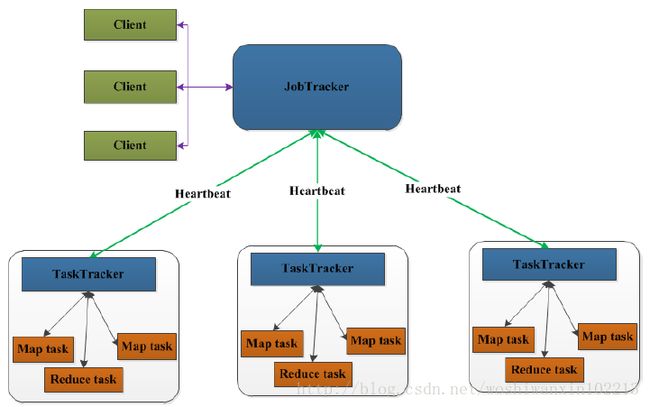
Hadoop的组件如图所示,但核心组件包括:MapReduce和HDFS。

1、HDFS的体系结构
我们首先介绍HDFS的体系结构,HDFS采用了主从(Master/Slave)结构模型,一个HDFS集群是由一个NameNode和若干个DataNode组成的。其中NameNode作为主服务器,管理文件系统的命名空间和客户端对文件的访问操作;集群中的DataNode管理存储的数据。HDFS允许用户以文件的形式存储数据。从内部来看,文件被分成若干个数据块,而且这若干个数据块存放在一组DataNode上。NameNode执行文件系统的命名空间操作,比如打开、关闭、重命名文件或目录等,它也负责数据块到具体DataNode的映射。DataNode负责处理文件系统客户端的文件读写请求,并在NameNode的统一调度下进行数据块的创建、删除和复制工作。
NameNode和DataNode都被设计成可以在普通商用计算机上运行。这些计算机通常运行的是GNU/Linux操作系统。HDFS采用Java语言开发,因此任何支持Java的机器都可以部署NameNode和DataNode。一个典型的部署场景是集群中的一台机器运行一个NameNode实例,其他机器分别运行一个DataNode实例。当然,并不排除一台机器运行多个DataNode实例的情况。集群中单一的NameNode的设计则大大简化了系统的架构。NameNode是所有HDFS元数据的管理者,用户数据永远不会经过NameNode。
2、MapReduce
接下来介绍MapReduce的体系结构,MapReduce是一种并行编程模式,这种模式使得软件开发者可以轻松地编写出分布式并行程序。在Hadoop的体系结构中,MapReduce是一个简单易用的软件框架,基于它可以将任务分发到由上千台商用机器组成的集群上,并以一种高容错的方式并行处理大量的数据集,实现Hadoop的并行任务处理功能。MapReduce框架是由一个单独运行在主节点上的JobTracker和运行在每个集群从节点上的TaskTracker共同组成的。主节点负责调度构成一个作业的所有任务,这些任务分布在不同的从节点上。主节点监控它们的执行情况,并且重新执行之前失败的任务;从节点仅负责由主节点指派的任务。当一个Job被提交时,JobTracker接收到提交作业和配置信息之后,就会将配置信息等分发给从节点,同时调度任务并监控TaskTracker的执行。
其它组件的介绍参见Hadoop、Hadoop核心组件
二、Spark的核心组件概述
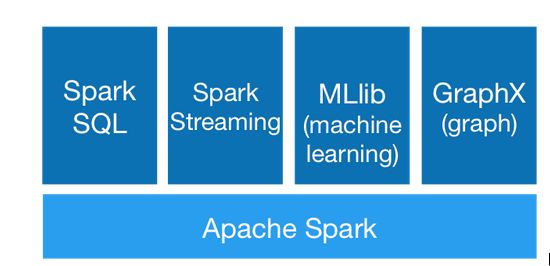
了解Spark先了解一下它的核心组件:Spark SQL、Spark Streaming、Spark MLlib和Spark Graphx。上图
1、Spark SQL
自Spark1.0版本以来,它就作为一个从Spark平台获取数据的渠道,早期用户比较喜爱Spark SQL提供的从现有Apache Hive表以及流行和Parquet列式存储格式中读取数据的支持。之后,随着Spark SQL对其他格式支持的增加(如比较流行的数据格式---JSON等),使得数据源更加方便的进行数据格式转换后融合到Spark平台中。并由API提供的密集优化器集合意味着过滤和列修剪在很多情况下都会被运用于数据源,极大的优化、减少了需要处理的数据量,显著提高了Spark的工作效率。更详细理解可以学习SparkSQL、借鉴整理对Spark SQL的理解
2、Spark Streaming
Spark Streaming基于Spark Core实现了可扩展、高吞吐和容错的实时流处理。支持非常多的数据源(包括Kafka、Flume、HDFS、S3等等),处理的结果可以存储到HDFS、Database等中。它的原理就是将流式计算分解成一系列短小的批处理作业---以Spark作为批处理的引擎,将Spark Streaming的输入数据按照批处理尺寸分成一段一段的数据,再将每一段数据转换成Spark中的RDD,然后将Spark Streaming中对DStream的转换操作变为针对Spark中对RDD的转换操作,将RDD经过操作变成中间结果保存在内存中。整个Spark Streaming提供了一套高效、可容错的、实时的、大规模的流式处理框架。更详细理解可以学习SparkStreaming、借鉴Spark Streaming实时计算框架介绍、Spark Streaming实例分析
3、Spark MLlib
MLlib是Spark对常用的机器学习算法的实现库,同时含有相关的测试和数据生成器,包括分类、回归、聚类、协同过滤、降维及底层基本的优化元素。其中分类和回归的相关算法包括SVM、逻辑回归、线性回归、朴素贝叶斯、决策树等;协同过滤包括交替最小二乘法(ALS);聚类有KMeans、Streaming版本的KMeans、高斯混合(Gaussian mixture)、PIC(Power Iteration Clustering)、LDA(Latent Dirichlet Allocation)等;降维实现了SVD(Singular Value Decomposition)和PCA(Principal Compaonet Analysis);频繁模式挖掘实现有FP-growth。相信随着时间的推移,机器学习库会越来越完备,Spark MLlib
4、Graphx
Spark对图计算的支持,随着人工智能、机器学习的研究,Graphx也逐渐蓬勃发展。
Spark整体架构如下图所示:
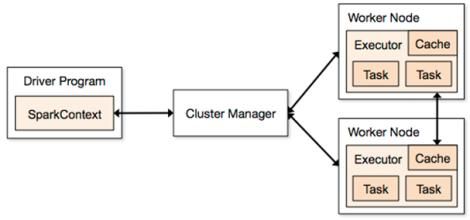
Driver是用户编写的数据处理逻辑,这个逻辑包含用户创建的SparkContext,SparkContext是用户逻辑与Spark集群主要的交互接口,它会和Cluster Manager交互申请计算资源等;Cluster Manager总体负责集群的资源管理和调度(支持Standalone、Apache Mesos和Hadoop的YARN);WorkNode则是集群中可以执行计算任务的节点;Excutor是一个WorkNode上为某应用程序启动的一个进程,负责运行任务并且将数据存在内存或者磁盘上;Task是被送到某个Executor上计算单元,每个应用都有独立的Executor计算最终在计算节点的Executor中执行:
用户程序从提交到计算执行需要经历以下几个阶段:
1)用户程序创建SparkContext时,新创建的SparkContext实例会连接到Cluster Manager,Cluster Manager会根据用户提交时设置的CPU和内存信息为本次提交分配计算资源,启动Executor;
2)Driver会将用户程序划分为不同的执行阶段,每个执行阶段由一组完全相同的Task组成,这些Task分别作用于待处理数据的不同分区;在阶段划分完成和Task创建后,Driver会向Executor发送Task;
3)Executor在接收到Task后,会下载Task运行时依赖,在准备好Task的执行环境后开始执行Task,并将Task的运行状态汇报给Driver;
4)Driver会根据收到的Task的运行状态来处理不同的状态更新,Task分为两种:一种是Shuffle Map Task,它实现数据的重新洗牌,洗牌的结果保存到Executor所在节点的文件系统中;另外一种是Result Task,它负责生成结果数据;
5)Driver会不断调用Task,将Task发送到Executor执行,在所有的Task都正确执行或超过执行次数的限制仍然没有执行成功时停止;