
使用Pytorch进行深度学习,60分钟闪电战
本次课程的目标:
- 从更高水平理解Pytorch的Tensor(张量)和神经网络
- 训练一个小的图像分类神经网络
注意确定已经安装了torch和torchvision
构建神经网络
可以使用torch.nn包来做神经网络。
之前对autograd有了一点点认识,而nn是基于autograd来定义模型并进行区分。一个nn.Module包括了层和一个forward(input)这样可以返回output。
教程以数字图片分类网络为例。
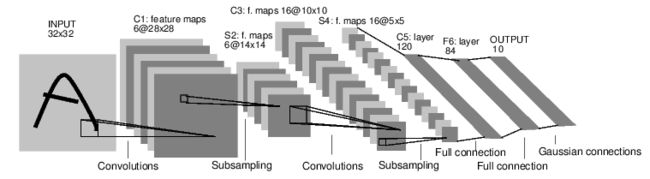
这是一个简单的feed-forward前馈网络,它接受输入,一个接一个地通过几个层输入,然后最终给出输出。
神经网络的典型训练程序如下:
- 定义神经网络,该网络包括了一些学习参数(或是权重)
- 迭代输入数据集
- 通过网络处理输入数据集
- 计算损失函数
- 反馈
- 更新神经网络权重,使用一个简单的更新规则
定义神经网络
先来试试定义一个神经网络
from __future__ import print_function
import torch
import torch.nn as nn
import torch.nn.functional as F
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5)
self.conv2 = nn.Conv2d(6, 16, 5)
self.fc1 = nn.Linear(16 * 5 * 5, 120)
self.fc2 = nn.Linear(120, 84)
self.fc3 = nn.Linear(84, 10)
def forward(self,x):
x=F.max_pool2d(F.relu(self.conv1(x)),(2,2))
x=F.max_pool2d(F.relu(self.conv2(x)),2)
x=x.view(-1,self.num_flat_features(x))
x=F.relu(self.fc1(x))
x=F.relu(self.fc2(x))
x=self.fc3(x)
return x
def num_flat_features(self,x):
size=x.size()[1:]
num_feature=1
for s in size:
num_feature*=s
return num_feature
if __name__ == '__main__':
net = Net()
print(net)
用户只需定义forward函数,并使用自动编程自动为用户定义backward函数(计算梯度的位置)。您可以在转发功能中使用任何Tensor操作。
模型中的参数可以通过net.parameters()
if __name__ == '__main__':
params=list(net.parameters())
print(len(params))
print(params[0].size())
input=torch.randn(1,1,32,32)
out=net(input)
print(out)
10
torch.Size([6, 1, 5, 5])
tensor([[-0.0054, -0.0305, 0.0345, 0.0430, 0.0299, -0.0436, 0.0299,
-0.1239, -0.0808, 0.0694]])
注意: torch.nn 只接受小批量的数据
整个torch.nn包只接受那种小批量样本的数据,而非单个样本。 例如,nn.Conv2d能够结构一个四维的TensornSamples x nChannels x Height x Width。
如果你拿的是单个样本,使用input.unsqueeze(0)来加一个假维度就可以了。
扼要重述
- torch.Tensor是一个多维度排列,它支持autograd操作(backward()),同时包含着和张量相关的梯度。
- nn.Module是一个神经网络模块,封装了多个参数,同时能够移植GPU,导出,重载。
- nn.Parameter是一种Tensor,当给Module赋值时能够自动注册为一个参数。
- autograd.Function能够使用自动求导实现forward和backward。每个Variable的操作都会生成至少一个独立的Function节点,与生成了Variable的函数相连之后记录下操作历史。
OK,到这里掌握的有
- 如何定义神经网络
- 处理输入和调用backward
还剩下
- 计算损失函数
- 更新网络中的权重
计算损失函数
一个损失函数将(output, target)作为输入,计算数值并评估之前的输出output距离target目标值有多少距离。
有多种损失函数公式,在这里使用nn.MSELoss来计算输入和目标之间的均方误差。
举个栗子
if __name__ == '__main__':
net = Net()
input=torch.randn(1,1,32,32)
output=net(input)
print(output)
target=torch.randn(10)
target=target.view(1,-1)
criterion=nn.MSELoss()
loss=criterion(output,target)
print(loss)
tensor([[ 0.0923, 0.0274, 0.1043, -0.0715, -0.0499, 0.0079, 0.0866,
-0.0800, -0.0133, -0.1014]])
tensor(0.9399)
此时,如果用户想查看整个计算流程,可以使用.grad_fn查看。
print(loss.grad_fn)
print(loss.grad_fn.next_functions[0][0]) # Linear
print(loss.grad_fn.next_functions[0][0].next_functions[0][0]) # ReLU
Backprop反向传递
要完成反向传播,我们所要做的就是loss.backward()。用户要清空现有的梯度值,否则梯度将被计算为已有梯度。
现在我们将调用loss.backward(),并查看conv1在backward之前和之后的偏置梯度。
net.zero_grad() #归零操作
print('conv1.bias.grad before backward',net.conv1.bias.grad)
loss.backward()
print('conv1.bias.grad after backward')
print(net.conv1.bias.grad)
conv1.bias.grad before backward
None
conv1.bias.grad after backward
tensor(1.00000e-02 *
[-0.2610, -0.2729, 1.6355, 0.9463, -0.0689, -1.1425])
更新权重
最简单的更新的规则是随机梯度下降法(SGD):
learning_rate = 0.01
for f in net.parameters():
f.data.sub_(f.grad.data * learning_rate)
然而在你使用神经网络的时候你想要使用不同种类的方法诸如:SGD, Nesterov-SGD, Adam, RMSProp, etc.
我们构建了一个小的包torch.optim来实现这个功能,其中包含着所有的这些方法。 用起来也非常简单:
import torch.optim as optim
# 创建自己的优化
optimizer = optim.SGD(net.parameters(), lr=0.01)
# 在训练循环中
optimizer.zero_grad() # zero the gradient buffers
output = net(input)
loss = criterion(output, target)
loss.backward()
optimizer.step() # Does the update