小呆学数据分析——使用pandas中的merge函数进行数据集合并
文章目录
- 数据集合并应用场景
- 例子
- 文章导引列表:
- 机器学习
- 数据分析
- 数据可视化
数据集合并应用场景
数据集合并在日常工作经常遇到,典型的如将两次具有不同调查项目的结果进行合并,或者将不同调查员的同样调查项目的内容进行合并。
例子
王小呆一天被交代一项任务,将公司从不同渠道拿到的两个资料本(一个电话本,一个是其他资料,其中姓名有重叠)整理成一个电话本交给营销部以便更好推销。
于是小呆打开资料本A.csv、B.csv看了内容:
资料本A:
| 姓名 | 手机号 | 固话 |
|---|---|---|
| 张晓散 | 18020112138 | 05746211 |
| 李孝思 | 18019005908 | 05746222 |
| 王笑武 | 18020111591 | 05746245 |
| 陈肖柳 | 18025812138 | 05746564 |
| 孙萧齐 | 18121312138 | 05743453 |
资料本B:
| 姓名 | 性别 | 身高 |
|---|---|---|
| 张晓散 | 男 | 177 |
| 王笑武 | 男 | 168 |
| 赵小七 | 女 | 158 |
王小呆麻利的将资料本A和资料本B另存为book1.csv和book2.csv。
book1.csv
姓名,手机号,固话
张晓散,18020112138,05746211
李孝思,18019455908,05746222
王笑武,18020111591,05746245
陈肖柳,18025812138,05746564
孙萧齐,18121312138,05743453
book2.csv
姓名,性别,身高
张晓散,男,177
王笑武,男,168
赵小七,女,158
王小呆准备好了数据,嚼了一块口香糖,内心暗暗想该怎么做呢?
还是先把数据导进去再说吧,就默默的打开了Python,写下了两行代码
import pandas as pd
book1 = pd.read_csv('book1.csv')
book2 = pd.read_csv('book2.csv')
运行报错:
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xd0 in position 0: invalid continuation byte
王小呆拍拍脑袋,哎呀怎么没想到数据里面是中文呀,于是把代码改成
import pandas as pd
book1 = pd.read_csv('book1.csv', encoding = 'GB2312')
book2 = pd.read_csv('book2.csv', encoding = 'GB2312')
print(book1)
print(book2)
结果如下:
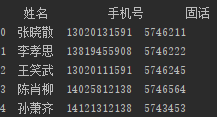
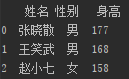
小呆想到小瓜给他讲过pandas里面有一个merge函数,于是小呆尝试的写下代码:
pd.merge(book1, book2)
运行结果如下:
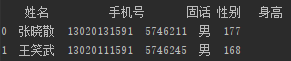
王小呆想了想这好像只是包含了姓名一样的行,他脑袋里面画了一张图
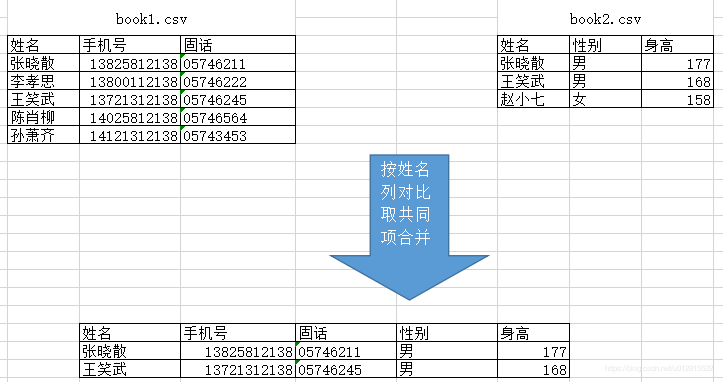
小呆心想这可不是我想要的结果,然后小呆看了帮助文档,明白了原来merge函数还有选择怎么进行合并的参数。
于是小呆写下代码:
pd.merge(book1,book2,how='right')
结果如下:

看到这里小呆脑袋冒出了两个问号,1. 这里面手机号和固话怎么都变成浮点数了,还有NaN是什么?2.这里面的项怎么变和book2里面的内容一样多的,我可是想要并集。
小呆问了小瓜,小瓜告诉小呆,首先merge函数里面的how指定合并方向,根据不同参数有四种合并方式:
- 内连接
合并结果是两者的交集。 - 全连接
合并结果是两者的并集,只要集合1或者集合2中出现一次就放到合并集中。 - 左连接
以集合1(book1.csv)为目标,依项对比集合2(book2.csv),发现相同项目,把该行添加到合并集里面。 - 右连接
以集合2(book2.csv)为目标,依项对比集合1(book1.csv),发现相同项目,把该行添加到合并集里面。
小瓜接着说道依项对比,我到底去哪一列的项对比也是可以设置的哦,上面的内容中其实做了省略,写全应该是这样的,小瓜写下代码:
pd.merge(book1, book2, on = '姓名',how = 'outer')
结果如下:
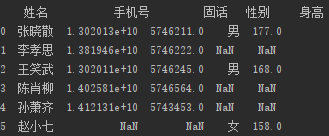
那第一个问题呢?小呆问道。
那是因为两者的项目数量不同,pd.merge在进行合并操作的时候会在未定义项(缺失项)中补NaN(Not a Number),只要有NaN的该列其他数字都会改变成浮点数。
小呆点点头,心里嘀咕,真的是这样吗?于是写下代码:
pd.merge(book1, book2, on = '姓名',how = 'left')
结果如下:

真的欸,左连接就是以book1为目标,依次对比book2中的姓名项,一样的话就把book2中后面的性别和身高项合并到合并集中,而且由于以book1为目标,所以手机号和固话号列中不会补NaN,所以手机号和固话号还是整型。
由于是要把资料A和资料B整理出来给推销团队用的,所以没有手机和固话的信息是没有用的,所以小呆就把上述的合并结果给领导了。
文章导引列表:
机器学习
- 小瓜讲机器学习——分类算法(一)logistic regression(逻辑回归)算法原理详解
- 小瓜讲机器学习——分类算法(二)支持向量机(SVM)算法原理详解
- 小瓜讲机器学习——分类算法(三)朴素贝叶斯法(naive Bayes)
- 小瓜讲机器学习——分类算法(四)K近邻法算法原理及Python代码实现
- 小瓜讲机器学习——分类算法(五)决策树算法原理及Python代码实现
- 小瓜讲机器学习——聚类算法(一)K-Means算法原理Python代码实现
- 小瓜讲机器学习——聚类算法(二)Mean Shift算法原理及Python代码实现
- 小瓜讲机器学习——聚类算法(三)DBSCAN算法原理及Python代码实现
数据分析
- 小呆学数据分析——使用pandas中的merge函数进行数据集合并
- 小呆学数据分析——使用pandas中的concat函数进行数据集堆叠
- 小呆学数据分析——pandas中的层次化索引
- 小呆学数据分析——使用pandas的pivot进行数据重塑
- 小呆学数据分析——用duplicated/drop_duplicates方法进行重复项处理
- 小呆学数据分析——缺失值处理(一)
- 小呆学数据分析——异常值判定与处理(一)
- 小瓜讲数据分析——数据清洗
数据可视化
- 小瓜讲数据分析——数据可视化工程(matplotlib库使用基础篇)
- 小瓜讲matplotlib高级篇——坐标轴设置(坐标轴居中、坐标轴箭头、刻度设置、标识设置)