【每日学习】深度学习相关知识
1、【2019年11月8日】过拟合与欠拟合
过拟合和欠拟合是常见的机器学习概念,这里写一下,为后面的BN层学习奠定基础。我们可以用下面的图来表示:

最左边为欠拟合,可以看出拟合程度不是很好,经常会造成训练中精度不高。最右边为过拟合,曲线很好拟合了样本,以至于噪声数据也被拟合,经常会造成实际测试精度不高。中间的就拟合的非常好,即保证了正常样本的拟合,又确保了噪声数据不会被拟合。
(1)欠拟合:欠拟合比较好理解就是模型简单或者说语料集偏少、特征太多,在训练集上的准确率不高,同时在测试集上的准确率也不高,这样如何训练都无法训练出有意义的参数,模型也得不到较好的效果。【解决方法】选取好的模型、特征以及训练集。
(2)过拟合:过拟合主要是因为模型尽力去拟合所有的训练数据,导致某一些噪声数据也拟合。模型在训练的时候并不清楚哪些是脏数据,它只会不停的去拟合这些数据。导致公共特征学习较少,从而在测试过程准确率低。【解决方法】①提前结束训练;②扩充数据集;③正则化或批归一化;④Dropout;⑤挑选合适的模型。
【参考资料】
https://blog.csdn.net/randompeople/article/details/82107740
2、【2019年11月12日】批归一化(Batch Normalization)
为啥需要归一化?神经网络学习过程本质就是为了学习数据分布,一旦训练数据与测试数据的分布不同,那么网络的泛化能力也大大降低。
批归一化算法原理如下图所示。

首先求每一个小批量训练数据的均值,然后求每一个小批量训练数据的方差。接着使用求得的均值和方差对该批次的训练数据做归一化,获得0-1分布。其中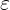 是为了避免除数为0时所使用的微小正数。最后尺度变换和偏移:将
是为了避免除数为0时所使用的微小正数。最后尺度变换和偏移:将 乘以
乘以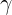 调整数值大小,再加上
调整数值大小,再加上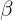 增加偏移后得到
增加偏移后得到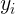 ,这里的是尺度因子,是平移因子。这一步是BN的精髓,由于归一化后的基本会被限制在正态分布下,使得网络的表达能力下降。为解决该问题,我们引入两个新的参数:和。和是在训练时网络自己学习得到的。
,这里的是尺度因子,是平移因子。这一步是BN的精髓,由于归一化后的基本会被限制在正态分布下,使得网络的表达能力下降。为解决该问题,我们引入两个新的参数:和。和是在训练时网络自己学习得到的。
BN在神经网络训练中会有下面的作用:第一是可以加快训练速度。第二是可以省去Dropout、L1、L2等正则化处理方法。第三是可以提高模型训练精度,在一定程度缓解了深层网络中梯度弥散(特征分布较散)的问题,从而使得训练深层网络模型更加容易和稳定。
【参考资料】
https://blog.csdn.net/bingo_csdn_/article/details/79393354
https://blog.csdn.net/vict_wang/article/details/88075861
3、【2019年11月26日】L1正则化
正则化的目的就是防止模型的过拟合,我们当然希望模型训练的过程中损失逐渐降低,也同时希望测试的时候也能有很好的泛化能力。

例如房价预测,使用多项式回归拟合数据。正常为二次项(如上方左图所示),我们当然不希望过拟合导致的曲线变为高次函数(如上方右图所示)。所以在这里会加入一个惩罚项,从而使得高次幂近似为0。
一般来说,监督学习可以看做最小化下面的目标函数:

上式中第一项为模型f(x)关于训练数据集的平均损失;第二项为正则化项,来约数模型更加简单。
L1正则化和L2正则化可以看做是损失函数的惩罚项。所谓『惩罚』是指对损失函数中的某些参数做一些限制。对于线性回归模型,使用L1正则化的模型建叫做Lasso回归,使用L2正则化的模型叫做Ridge回归(岭回归)。
L1范数是指向量中各个元素绝对值之和。

以二维样本为例,下图为原始目标函数的曲线等高线,对于线性回归这种目标函数凸函数的话,我们最终的结果就是最里边的紫色的小圈圈等高线上的点。

加入L1正则化以后的图像为:

根据上图可知,当这个菱形与某条等高线相切(仅有一个交点)的时候,这个菱形最小。
几乎对于很多原函数等高曲线,和某个菱形相交的时候及其容易相交在坐标轴(比如上图),也就是说最终的结果,解的某些维度及其容易是0,比如上图最终解是![]() ,这也就是我们所说的L1更容易得到稀疏解(解向量中0比较多)的原因。
,这也就是我们所说的L1更容易得到稀疏解(解向量中0比较多)的原因。
L1范数会使权值稀疏,参数稀疏规则化能够实现特征的自动选择,在特征工程的过程中,一般来说,![]() 的大部分元素(特征)都和其标签
的大部分元素(特征)都和其标签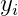 没有关系的。我们在最小化目标函数的时候,考虑了这些无关特征,虽然可以获得最小的训练误差,但是对于新的样本时,这些没用的信息反而被考虑,干扰了对样本的预测。稀疏规则化将这些没用的特征的权重置为0,去掉这些没用的特征。
没有关系的。我们在最小化目标函数的时候,考虑了这些无关特征,虽然可以获得最小的训练误差,但是对于新的样本时,这些没用的信息反而被考虑,干扰了对样本的预测。稀疏规则化将这些没用的特征的权重置为0,去掉这些没用的特征。
【参考资料】
https://zhuanlan.zhihu.com/p/35356992
https://blog.csdn.net/fisherming/article/details/79492602
https://www.cnblogs.com/lliuye/p/9354972.html