deeplabv3+ 代码解析 去除decoder 部分
只需要训练时不提供参数“
--decoder_output_stride=4 \
”
就可以直接去掉decode部分,那么取而代之的就是下面要讨论的。
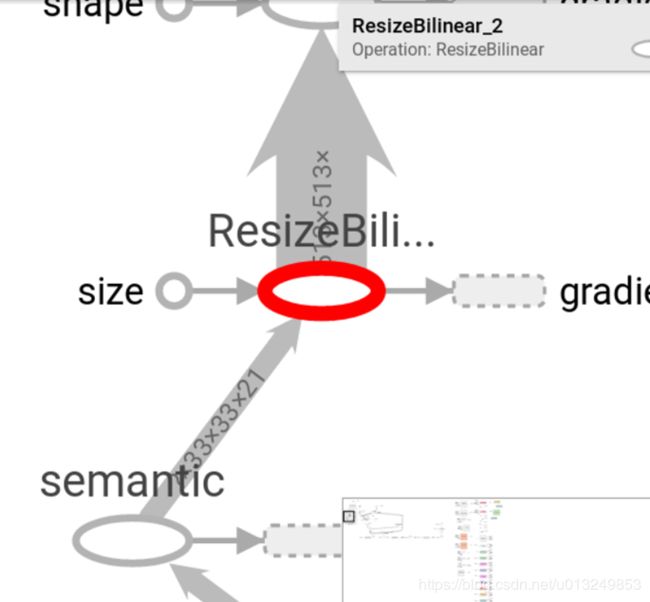
可以看出来,直接将16倍的特征图上采样到了原始图片大小。并且使用的是21通道的小特征图。
从代码来看:
def _get_logits(images,
model_options,
weight_decay=0.0001,
reuse=None,
is_training=False,
fine_tune_batch_norm=False,
nas_training_hyper_parameters=None):
"""Gets the logits by atrous/image spatial pyramid pooling.
Args:
images: A tensor of size [batch, height, width, channels].
model_options: A ModelOptions instance to configure models.
weight_decay: The weight decay for model variables.
reuse: Reuse the model variables or not.
is_training: Is training or not.
fine_tune_batch_norm: Fine-tune the batch norm parameters or not.
nas_training_hyper_parameters: A dictionary storing hyper-parameters for
training nas models. Its keys are:
- `drop_path_keep_prob`: Probability to keep each path in the cell when
training.
- `total_training_steps`: Total training steps to help drop path
probability calculation.
Returns:
outputs_to_logits: A map from output_type to logits.
"""
features, end_points = extract_features(
images,
model_options,
weight_decay=weight_decay,
reuse=reuse,
is_training=is_training,
fine_tune_batch_norm=fine_tune_batch_norm,
nas_training_hyper_parameters=nas_training_hyper_parameters)
if model_options.decoder_output_stride is not None:
features = refine_by_decoder(
features,
end_points,
crop_size=model_options.crop_size,
decoder_output_stride=model_options.decoder_output_stride,
decoder_use_separable_conv=model_options.decoder_use_separable_conv,
model_variant=model_options.model_variant,
weight_decay=weight_decay,
reuse=reuse,
is_training=is_training,
fine_tune_batch_norm=fine_tune_batch_norm,
use_bounded_activation=model_options.use_bounded_activation)
outputs_to_logits = {}
for output in sorted(model_options.outputs_to_num_classes):
outputs_to_logits[output] = get_branch_logits(
features,
model_options.outputs_to_num_classes[output],
model_options.atrous_rates,
aspp_with_batch_norm=model_options.aspp_with_batch_norm,
kernel_size=model_options.logits_kernel_size,
weight_decay=weight_decay,
reuse=reuse,
scope_suffix=output)
return outputs_to_logits直接跳过decoder,将(33,33,256)特征图传入get_branch_logits. 处理过后得到(33,33,21)特征图。
之后直接在train_utils.py还原到原图大小。
if upsample_logits:
# Label is not downsampled, and instead we upsample logits.
logits = tf.image.resize_bilinear(
logits,
preprocess_utils.resolve_shape(labels, 4)[1:3],
align_corners=True)
scaled_labels = labels