python实现CSDN下载资源自动评分(selenium+requests)
1. background:
CSDN下载资源需要下载积分,评论已经下载过的资源,可以获得1分返现. 自己之前下载过50多个资源, 但是不想手动一个个去评分+评论。所以想写个小程序,自动完成50多个资源的评论.
2. assessment
有了需求,接下来开始分析。我这里直接描述分析结果哈. 可以把这个项目分解为以下几个步骤:
1. 登录CSDN
2. 获取所有未评论资源的url页面
3. 实现评论功能
a)登录CSND方式有两种, a.后台模拟提交 b.利用selenium webdriver实现浏览器登录, 方法最简单就是b.
iedriver = os.getcwd() + "\\IEDriverServer.exe"
os.environ["webdriver.ie.driver"] = iedriver
dr = webdriver.Ie(iedriver) dr.get("https://passport.csdn.net/account/login")
dr.find_element_by_id("username").send_keys("your username")
dr.find_element_by_id("password").send_keys("your password")
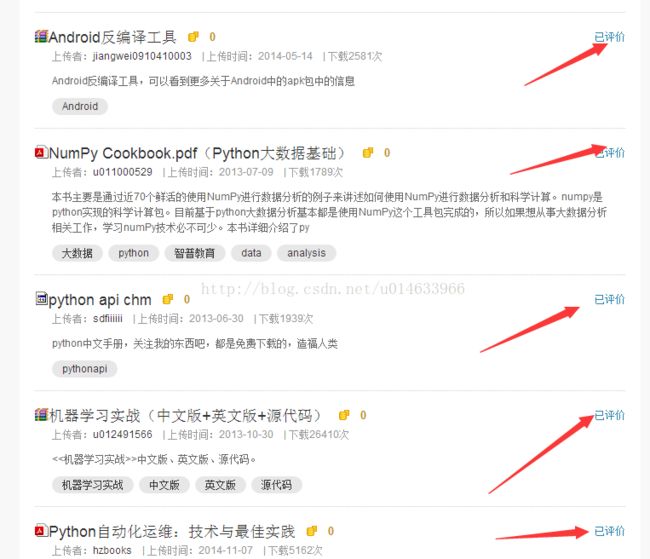
dr.find_element_by_class_name("logging").click()b)获取所有资源的url页面, 比如我自己的:
一共58个资源,分为10页. 所有我需要遍历10个download page,分别把each page的评论url抓取出来. 惊奇的发现:
比如第二页, page的url其实是:http://download.csdn.net/my/downloads/2
懂了吧! 遍历所有页面:
page_urls=[] baseurl="http://download.csdn.net/my/downloads"
page_urls.append(baseurl)
for i in range(2,11):
self.page_urls.append(baseurl+"/"+str(i))抓取page中6个资源的url页面:
通过查看元素,可以看到网页中的元素html属性:
所以接下来就是用正则表达式,抓吧!
comments_urls=[]
stra='立即评价'
regl=r'立即评价'
matchs=re.findall(regl, ret.content)
for m in matchs:
comments_urls.append("http://download.csdn.net"+m)c)实现评分.
我采用的方式是,先找一个资源,去评分一下,然后抓取网络http包。抓包工具很多,可以用firefox的httpfox,我用的360浏览器的自带功能。
其实调用的是comment.js代码:
ok,原来点了提交评论后,后台执行的是ajax请求,请求内容是data后面的值.
分析这个data不难发现,这个sourceid其实就是我们comment url中的7个数字,比如:http://download.csdn.net/detail/lee118007/8637891#comment
content呢就是我们的评论汉字,只是采用了unicode编码.
请求地址是:
http://download.csdn.net/index.php/comment/post_comment
只是这里有个特别重要的point: 那就是cookie和headers
如果cookie和headers不对,是会被服务器拒绝的! 所有我们需要将webderivr中的cookies提取出来,然后用到我们的requests请求中. headers呢就简单了,看看抓包中的headers信息就知道。
到此,3个环节,都可以实现,话不多说,直接上code:
#!/usr/bin/python
#coding=utf-8
import socket
import time
import binascii
import re
import urllib
import requests
import urllib2
from selenium import webdriver
from selenium.webdriver.common.proxy import Proxy
import os
# proxy_host="135.251.33.16"
# proxy_port="8080"
# firefox_profile = webdriver.FirefoxProfile()
#
# firefox_profile.set_preference('network.proxy.type', 1)
# firefox_profile.set_preference('network.proxy.http', proxy_host)
# firefox_profile.set_preference('network.proxy.http_port', int(proxy_port))
# firefox_profile.set_preference('network.proxy.ssl', proxy_host)
# firefox_profile.set_preference('network.proxy.ssl_port', int(proxy_port))
# firefox_profile.set_preference('network.proxy.no_proxies_on', '127.0.0.1, localhost, .local')
# firefox_profile.update_preferences()
#
# dr=webdriver.Firefox(firefox_profile=firefox_profile)
class CSDN():
def __init__(self):
iedriver = os.getcwd() + "\\IEDriverServer.exe"
os.environ["webdriver.ie.driver"] = iedriver
self.dr = webdriver.Ie(iedriver)
self.comments_urls=[]
self.page_urls=[]
def login(self):
self.dr.get("https://passport.csdn.net/account/login")
self.dr.find_element_by_id("username").send_keys("XXXXXX")
self.dr.find_element_by_id("password").send_keys("XXXXXXX")
self.dr.find_element_by_class_name("logging").click()
time.sleep(2)
def logtext(self,msg): #打印log顺便写入到D:/log.txt文件
print msg
f=open("D:/log.txt","a+")
f.write("".join(msg)+"\n")
f.close()
def get_all_links(self):
baseurl="http://download.csdn.net/my/downloads"
self.page_urls.append(baseurl)
for i in range(2,11):
self.page_urls.append(baseurl+"/"+str(i))
def grep_comments_link(self,page):
new_ck={}
for ck in self.dr.get_cookies():
new_ck[ck['name']]=ck['value']
zyh_header={
"Host": "download.csdn.net",
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Accept":'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
"Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding":"gzip, deflate",
"Upgrade-Insecure-Requests":"1",
"Connection": "Keep-Alive",
}
s=requests.session()
ret = s.request("GET", page, headers=zyh_header, cookies=new_ck)
#stra='立即评价'
regl=r'立即评价'
matchs=re.findall(regl, ret.content)
for m in matchs:
self.comments_urls.append("http://download.csdn.net"+m)
def rate(self,comment_url):
# self.dr.get(comment_url)
self.logtext( "start rating:"+comment_url)
# print self.dr.get_cookies()
new_ck={}
for ck in self.dr.get_cookies():
new_ck[ck['name']]=ck['value'] ##这里最关键!将webdriver中的cookie提取出来然后赋给requests.session()
zyh_header={
"Host": "download.csdn.net",
'User-Agent':"Mozilla/5.0 (Windows NT 6.1; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Accept":'text/javascript, application/javascript, application/ecmascript, application/x-ecmascript, */*; q=0.01',
"Accept-Language":"zh-CN,zh;q=0.8,en-US;q=0.5,en;q=0.3",
"Accept-Encoding":"gzip, deflate",
"X-Requested-With":"XMLHttpRequest",
"Referer":comment_url[:-8],
"Connection": "Keep-Alive",
}
s=requests.session()
url="http://download.csdn.net/index.php/comment/post_comment"
datas='sourceid='+comment_url[-15:-8]+'&content=%E6%84%9F%E8%B0%A2%E5%88%86%E4%BA%AB%E6%84%9F%E8%B0%A2%E5%88%86%E4%BA%AB&txt_validcode=undefined&rating=5&t='+str(int(time.time()*1000))
ret=s.request("GET", url,datas, headers=zyh_header, cookies=new_ck)
self.logtext("reply:"+ret.content)
if __name__ == '__main__':
csdn=CSDN()
csdn.login()
csdn.get_all_links()
csdn.logtext(csdn.page_urls)
for page in csdn.page_urls:
csdn.grep_comments_link(page)
csdn.logtext("sum of comments_urls:"+str(len(csdn.comments_urls)))
csdn.logtext(csdn.comments_urls)
for cl in csdn.comments_urls:
csdn.rate(cl)
time.sleep(360) #由于csdn设置了评论间隔,所以我也设置了每个6分钟去提交打印结果如下:
['http://download.csdn.net/my/downloads', 'http://download.csdn.net/my/downloads/2', 'http://download.csdn.net/my/downloads/3', 'http://download.csdn.net/my/downloads/4', 'http://download.csdn.net/my/downloads/5', 'http://download.csdn.net/my/downloads/6', 'http://download.csdn.net/my/downloads/7', 'http://download.csdn.net/my/downloads/8', 'http://download.csdn.net/my/downloads/9', 'http://download.csdn.net/my/downloads/10']
sum of comments_urls:40
['http://download.csdn.net/detail/st091zsc/9499197#comment', 'http://download.csdn.net/detail/mourendeyouxihao/5029371#comment', 'http://download.csdn.net/detail/lee118007/8637891#comment', 'http://download.csdn.net/detail/zhoujianghai/8160211#comment'#此处就省略了]
start rating:http://download.csdn.net/detail/st091zsc/9499197#comment
reply:({"succ":1})
start rating:http://download.csdn.net/detail/mourendeyouxihao/5029371#comment
reply:({"succ":1})
start rating:http://download.csdn.net/detail/lee118007/8637891#comment
reply:({"succ":1})
start rating:http://download.csdn.net/detail/zhoujianghai/8160211#comment
reply:({"succ":1})
start rating:http://download.csdn.net/detail/kayvid/8882275#comment
reply:({"succ":-4,"msg":"\u9a8c\u8bc1\u7801\u9519\u8bef"}) #貌似多次提交后,就开始需要验证码,这个后续再解决吧。
start rating:http://download.csdn.net/detail/ramissue/8451823#comment
reply:({"succ":-4,"msg":"\u9a8c\u8bc1\u7801\u9519\u8bef"})效果图: