【AI视野·今日CV 计算机视觉论文速览 第153期】Fri, 16 Aug 2019
AI视野·今日CS.CV 计算机视觉论文速览
Fri, 16 Aug 2019
Totally 29 papers
?上期速览✈更多精彩请移步主页

Interesting:
?***StructureFlow基于结构感知的外表流模型实现图像修复,研究人员提出了一种分层级的图像修复方法,首先利用保边了解构重建器来重建图像中缺失的结构,而后利用纹理生成器来补全细节的问题。在细节补全中还使用了appearance flow来充分使用原图中未被损坏的部分纹理采样,来通过结构相似性补全图中的纹理。(from 北大)

得到的结果如下图所示,同时这种方法还可以用于异常去除和图像编辑等任务:

code:https://github.com/RenYurui/StructureFlow
View Synthesis by Appearance Flow :https://people.eecs.berkeley.edu/~tinghuiz/
Appearance Flow for Human Pose Transfer:https://blog.csdn.net/mrqueens/article/details/89315607
?**Matrix Nets 将类似尺寸和比例的物体归一化到对应层实现高效目标检测,这篇文章提出了一种将尺寸和比例相同的物体放到对应的层进行检测的思想,使得每一层内处理的目标都有着较为统一的尺寸,实现了较好的检测效果。(from Vector Institute )
图中可以看到,新提出的方法在不同层次上处理不同尺寸和比例的目标,检测效果更好。

利用网络层矩阵来为不同尺寸比例的目标建模:

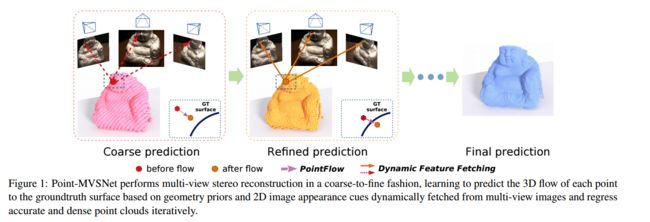
?Point-MVSNet 基于点云的多视角立体生成网络,这一模型针对多视角立体视觉问题直觉对点云进行处理,通过由粗到精的过程来得到精细的三维形貌。首先生成粗糙的深度图,并将深度图转化为点云,随后利用基准与目前估计深度图间的残差来进行迭代优化,将三维几何先验和二维纹理新型联合起来得到特征增强的点云,并利用点云为每个点估计对应的三维流。这一基于点云的架构不仅得到更高的精度更提高了效率和灵活性。(from 清华大学 Train starstress 任xinger)
模型的流程图,首先估计出粗糙的深度图,而后进行迭代优化:
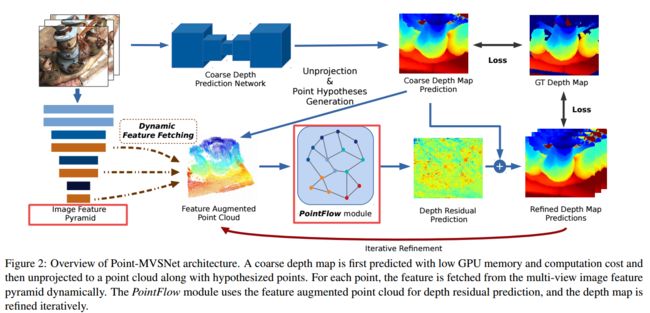
基于点流模块的点云优化过程:

点云优化的迭代过程:
code:https://github.com/callmeray/PointMVSNet.
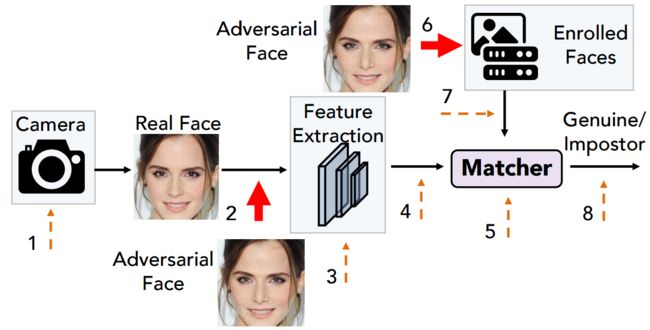
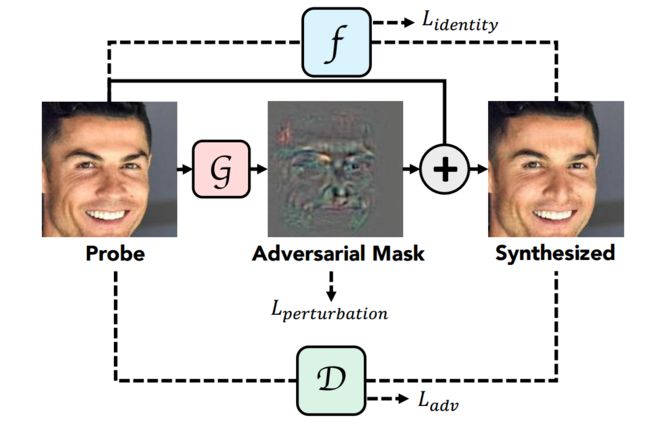
?AdvFaces合成高质量对抗样本的新方法,这篇文章提出了一种高质量的对抗人脸生成法(误匹配、误拒绝),通过GAN来改变人脸的潜在区域使得对原图的扰动最小,在不改变视觉质量的情况下,可以大幅度降低人脸的识别率实现对抗攻击(from 密歇根大学)
下图中可以看到,第一列为数据库中人脸,第二列为输入系统的人脸,可以看到与数据库中人脸相似度很高,而后面三列为对抗数据,其中第三列为本文方法,在不改变视觉效果的情况下大幅度降低了人脸相似性得分实现了对抗攻击。
一些常见的人脸对抗方法和本文提出方法在人脸系统中的对抗注入点:

本文提出的方法,模型可以针对输入图像生成加性mask来实现较好的对抗效果:
Daily Computer Vision Papers
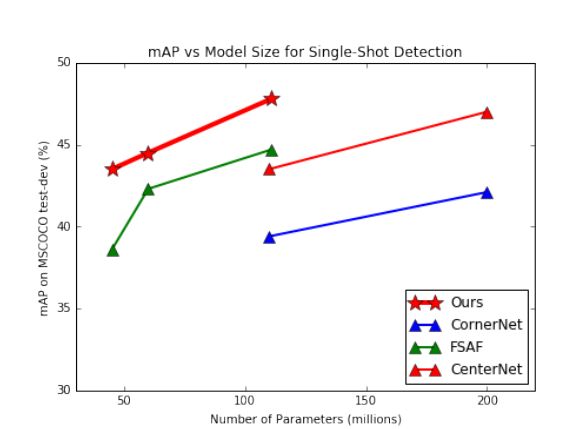
| IoU-balanced Loss Functions for Single-stage Object Detection Authors Shengkai Wu, Xiaoping Li 单级探测器是有效的。然而,我们发现单级探测器采用的损耗函数对于精确定位是次优的。用于分类的标准交叉熵损失独立于定位任务,并且驱动所有正例以尽可能高地学习分类得分,而不管训练期间的定位准确性。因此,将会有检测分类得分高但IoU低或分类得分低但IoU高。并且具有低分类得分但高IOU的检测将被具有高分类得分但在NMS期间低IOU的那些抑制,从而损害定位准确性。对于标准平滑L1损耗,梯度由具有较差定位精度的异常值控制,这对于精确定位是有害的。在这项工作中,我们提出IoU平衡损失函数,包括IoU平衡分类损失和IoU平衡定位损失,以解决上述问题。 IoU平衡分类丢失更多地关注具有高IOU的正例,并且可以增强分类和本地化任务之间的相关性。 IoU平衡定位损失降低了具有低IoU的示例的梯度,并且增加了具有高IoU的示例的梯度,这可以提高模型的定位精度。对MS COCO的充分研究表明,IoU平衡分类损失和IoU平衡定位损失都可以为单级探测器带来实质性改进。没有哨声和钟声,所提出的方法可以将单级探测器的AP提高1.1,并且在更高的IoU阈值下对AP的改善特别大,例如对于AP90为2.3。源代码将可用。 |
| R3Det: Refined Single-Stage Detector with Feature Refinement for Rotating Object Authors Xue Yang, Qingqing Liu, Junchi Yan, Ang Li 旋转检测是一项具有挑战性的任务,因为难以定位多角度物体并且准确且快速地将它们与背景分离。虽然已经取得了相当大的进步,但是对于具有大纵横比,密集分布和类别极不平衡的旋转物体仍然存在挑战。在本文中,我们提出了一种端到端精制单级旋转探测器,用于快速准确的定位物体。考虑到当前精细单级检测器中特征未对准的缺点,我们设计了一种特征细化模块来提高检测性能,这在长尾数据集中尤其有效。特征细化模块的关键思想是通过特征插值将当前细化边界框的位置信息重新编码到相应的特征点,实现特征重构和对齐。在两个遥感公共数据集DOTA,HRSC2016以及场景文本数据ICDAR2015上进行了大量实验,展示了我们探测器的最新精度和速度。源代码和模型将在论文发表后公布。 |
| FastPose: Towards Real-time Pose Estimation and Tracking via Scale-normalized Multi-task Networks Authors Jiabin Zhang, Zheng Zhu, Wei Zou, Peng Li, Yanwei Li, Hu Su, Guan Huang 精度和效率对于视频中的姿势估计和跟踪都很重要。最先进的性能由两个自上而下的方法主导。尽管取得了领先的成果,但由于它们分离的架构和复杂的计算,这些方法对于现实世界的应用是不切实际的。本文讨论了关节多人姿态估计和跟踪实时速度的任务。端到端多任务网络MTN被设计为同时执行人体检测,姿势估计和人员识别Re ID任务。为了缓解由尺度变化问题引起的性能瓶颈,提出了利用尺度归一化图像和特征金字塔SIFP的范例来提高性能和速度。给定MTN的结果,我们在姿势跟踪模块中采用遮挡感知Re ID特征策略,其中姿势信息用于推断遮挡状态以更好地利用Re ID特征。在实验中,我们证明姿势估计和跟踪性能通过不同的主干利用SIFP稳步提高。使用ResNet 18和ResNet 50作为主干,整体姿态跟踪框架分别以29.4 FPS和12.2 FPS实现了竞争性能。另外,遮挡感知Re ID特征在姿势跟踪过程中将识别开关减少37。 |
| Beyond Cartesian Representations for Local Descriptors Authors Patrick Ebel, Anastasiia Mishchuk, Kwang Moo Yi, Pascal Fua, Eduard Trulls 用于学习局部斑块描述符的主要方法依赖于小图像区域,其尺度必须由关键点检测器先验地适当地估计。换句话说,如果两个补丁不对应,则它们的描述符将不匹配。通常用于缓解此问题的策略是将像素明智的特征汇集在对数极性区域上,而不是规则间隔的区域。相比之下,我们建议使用对数极坐标采样方案直接提取支持区域。我们表明,这为我们提供了更好的表示,同时对点的直接邻域和远离它的欠采样区域进行过采样。我们证明这种表示特别适合于学习具有深度网络的描述符。我们的模型可以在比以前更广泛的范围内匹配描述符,并且还可以利用更大的支持区域而不会受到遮挡。我们在三个不同的数据集上报告最先进的结果。 |
| To complete or to estimate, that is the question: A Multi-Task Approach to Depth Completion and Monocular Depth Estimation Authors Amir Atapour Abarghouei, Toby P. Breckon 强大的三维场景理解现在是一个不断增长的研究领域,在许多现实世界的应用中具有高度相关性,例如自动驾驶和机器人导航。在本文中,我们提出了一种基于多任务学习的模型,能够执行两个任务稀疏深度完成,即在给定稀疏深度图像作为输入和单眼深度估计的情况下生成完整的密集场景深度,即通过两个子单元从单个RGB图像预测场景深度网络使用从公共可用的合成和真实世界图像语料库中随机抽样的数据进行端到端的联合训练。第一个子网络通过从场景中学习较低级别的特征来生成稀疏深度图像,第二个子网络预测整个场景的完整密集深度图像,从而对场景产生更好的几何和上下文理解,从而实现卓越的性能方法。整个模型可以用于从单个RGB图像推断完整的场景深度,或者可以单独使用第二网络在给定稀疏深度输入的情况下执行深度完成。使用对抗性训练,强大的目标函数,依赖跳过连接的深层架构以及综合和现实世界训练数据的混合,我们的方法能够产生出色的高质量场景深度。广泛的实验评估证明了我们的方法与两个问题领域的当代最先进技术相比的功效。 |
| A Single-Shot Arbitrarily-Shaped Text Detector based on Context Attended Multi-Task Learning Authors Pengfei Wang, Chengquan Zhang, Fei Qi, Zuming Huang, Mengyi En, Junyu Han, Jingtuo Liu, Errui Ding, Guangming Shi 在过去几年中,检测任意形状的场景文本一直是一项具有挑战性的任务。在本文中,我们提出了一种新的基于分割的文本检测器,即SAST,它采用基于完全卷积网络FCN的上下文参与多任务学习框架来学习文本区域的多边形表示的重建的各种几何属性。考虑到文本的顺序特征,引入了上下文注意块以捕获像素信息的长程依赖性以获得更可靠的分割。在后处理中,提出了点到四分配方法,通过在单个镜头中集成高级对象知识和低级像素信息,将像素聚类成文本实例。此外,可以更有效地利用所提出的几何特性来提取任意形状文本的多边形表示。几个基准测试的实验,包括ICDAR2015,ICDAR2017 MLT,SCUT CTW1500和Total Text,证明了SAST在精度方面实现了更好或相当的性能。此外,该算法在SCUT CTW1500上以27.63 FPS运行,单个NVIDIA Titan Xp显卡的Hmean为81.0,超过了大多数现有的基于分段的方法。 |
| Deep learning for Plankton and Coral Classification Authors Alessandra Lumini, Loris Nanni, Gianluca Maguolo 海洋是地球的重要生命线,它们提供70多种氧气和97种以上的水。浮游生物和珊瑚是海洋生态系统最基本的两个组成部分,前者是由于它们在海洋食物链的多个层面发挥作用,后者是因为它们为许多鱼类种群提供了产卵和育苗场所。研究和监测浮游生物分布和珊瑚礁对环境保护至关重要。在过去几年中,用于监测水下生态系统的数字图像大量增加,许多研究集中在浮游生物和珊瑚的自动识别上。在本文中,我们提出了一个关于水下生态系统监测自动化系统的研究。这里提出的系统是基于不同深度学习方法的融合。我们研究如何创建一个基于不同CNN模型的集合,对几个数据集进行微调,以利用它们的多样性。我们的研究目的是试验微调预训练CNN用于水下图像分析的可能性,使用不同数据集进行预训练模型的机会,使用相同的体系结构设计集合的可能性以及训练过程中的小变化。实验结果非常令人鼓舞,我们在5个知识数据集3个浮游生物和2个珊瑚数据集上进行的实验表明,这种不同的CNN模型在异构集合中的融合相对于其他所有现有技术方法都提供了显着的性能改进。经过测试的问题。这项工作的主要贡献之一是对着名的CNN架构进行广泛的实验评估,以报告单个CNN和CNN集合在不同问题中的性能。此外,我们展示了如何创建一个改善最佳单一模型性能的集合。 |
| Improved Mix-up with KL-Entropy for Learning From Noisy Labels Authors Qian Zhang, Feifei Lee, Ya Gang Wang, Qiu Chen 尽管深度神经网络DNN在图像分类研究中取得了优异的性能,但DNN的训练需要大量清晰的数据和准确的注释。收集数据集很简单,但很难对收集数据进行注释。在网站上,存在许多包含不准确注释的图像数据,但是对这些数据集的训练可能使网络更容易过度拟合噪声标签并导致性能下降。在这项工作中,我们提出了一种改进的联合优化框架,它将混合熵和Kullback Leibler KL熵混合作为损失函数。在框架更新标签注释后,新的损失函数可以提供更好的微调。我们对CIFAR 10数据集和Clothing1M数据集进行了实验。结果表明,与其他现有技术方法相比,我们的方法具有有利的性能。 |
| Accelerated CNN Training Through Gradient Approximation Authors Ziheng Wang, Sree Harsha Nelaturu 通过梯度下降训练诸如VGG和ResNet的深度卷积神经网络是昂贵的练习,需要诸如GPU之类的专用硬件。最近的工作已经研究了在保持相同的收敛特性的同时近似梯度计算的可能性。虽然很有希望,但近似值仅适用于相对较小的数据集,如MNIST。由于缺乏所提出的近似方法的有效GPU实现,它们也未能实现真正的挂钟加速。在这项工作中,我们探索了三种替代梯度的替代方法,其中一种方法是高效的GPU内核实现。我们使用ResNet 20和VGG 19在CIFAR 10数据集上实现了超过7的挂钟加速,验证精度损失最小。 |
| Learning Trajectory Dependencies for Human Motion Prediction Authors Wei Mao, Miaomiao Liu, Mathieu Salzmann, Hongdong Li 人体运动预测,即预测给定观察到的姿势序列的未来身体姿势,通常已经用递归神经网络RNN来解决。然而,如先前的工作所证明的,所得到的RNN模型遭受预测误差累积,导致运动预测中的不期望的不连续性。在本文中,我们提出了一个简单的前馈深度网络用于运动预测,它考虑了人体关节之间的时间平滑性和空间依赖性。在这种情况下,我们建议通过在轨迹空间中工作而不是传统使用的姿势空间来编码时间信息。这减轻了我们手动定义时间依赖性或时间卷积滤波器大小的范围,如在先前的工作中所做的那样。此外,通过将人体姿势视为通用图而不是由每对身体关节之间的链接形成的人体骨骼运动树来编码人体姿势的空间依赖性。我们设计了一个新的图形卷积网络来自动学习图形连接,而不是使用预定义的图形结构。这允许网络捕获超出人类运动树的远程依赖性。我们在几个用于运动预测的标准基准数据集上评估我们的方法,包括Human3.6M,CMU运动捕捉数据集和3DPW。我们的实验清楚地表明所提出的方法实现了现有技术的性能,并且适用于基于角度和基于位置的姿势表示。代码可在 |
| PS^2-Net: A Locally and Globally Aware Network for Point-Based Semantic Segmentation Authors Na Zhao, Tat Seng Chua, Gim Hee Lee 在本文中,我们为PS 2 Net提供了一个局部和全局意识的深度学习框架,用于3D场景级点云的语义分割。为了深入融入局部结构和全局背景以支持3D场景分割,我们的网络基于四个重复堆叠的编码器,其中每个编码器具有捕获局部结构的两个基本组件EdgeConv和用于模拟全局上下文的NetVLAD。与基于点的场景语义分割的现有技术方法不同,其违反或不实现置换不变性,我们的PS 2 Net被设计为置换不变量,这是用于处理无序点云的任何深度网络的基本属性。我们进一步提供了理论证明,以保证我们网络的置换不变性。我们对两个大型3D室内场景数据集进行了大量实验,并证明我们的PS2 Net与现有方法相比能够实现最先进的性能。 |
| Unpaired Cross-lingual Image Caption Generation with Self-Supervised Rewards Authors Yuqing Song, Shizhe Chen, Yida Zhao, Qin Jin 生成不同语言的图像描述对于满足全球用户至关重要。然而,收集针对每种目标语言的大规模配对图像字幕数据集是非常昂贵的,这对于训练下降图像字幕模型是至关重要的。之前的工作通过枢轴语言解决了不成对的跨语言图像字幕问题,该角色语言借助于枢轴语言中的成对图像标题数据并转向目标机器翻译模型。然而,这种语言转向方法受到枢轴转向目标翻译的不准确性,包括不流畅和视觉不相关错误。在本文中,我们建议在强化学习框架中生成具有自我监督奖励的交叉语言图像标题,以减轻这两类错误。我们采用目标语言中单语语料库的自我监督来提供流畅性奖励,并提出一种多层次的视觉语义匹配模型,以提供句子级别和概念级别的视觉相关性奖励。我们分别在两个广泛使用的图像标题语料库中对中英文不成对的交叉语言图像字幕进行了大量的实验。所提出的方法相对于现有技术方法实现了显着的性能改进。 |
| SFSegNet: Parse Freehand Sketches using Deep Fully Convolutional Networks Authors Junkun Jiang, Ruomei Wang, Shujin Lin, Fei Wang 通过语义分割来解析草图是有吸引力但具有挑战性的,因为我的自由手绘图是抽象的,由于不同的绘图风格和技能而在描绘对象方面存在大的差异.2在触摸板上绘制的扭曲线使得草图更难以被识别iii高性能图像分割通过深度学习技术,在训练阶段需要大量带注释的草图数据集。在本文中,我们提出了一个Sketch目标深度FCN分割网络SFSegNet,用于自动手绘草图分割,在一个具有多个部分的对象中标记每个草图。 SFSegNet在输入草图和分割结果之间有一个端到端的网络过程,由两部分ia修改深度全卷积网络FCN,使用重新加权策略忽略背景像素并分类每个像素属于哪个部分ii仿射变换编码器尝试将摇动的笔画规范化。我们使用由10,000个带注释的草图组成的数据集来训练我们的网络,以找到一个广泛适用的模型,在一个基本事实中语义上划分斯托克斯。进行了广泛的实验,分割结果表明我们的方法优于其他现有技术网络。 |
| Dual Adversarial Inference for Text-to-Image Synthesis Authors Qicheng Lao, Mohammad Havaei, Ahmad Pesaranghader, Francis Dutil, Lisa Di Jorio, Thomas Fevens 从给定文本描述合成图像涉及将两种类型的信息与内容相关联,其包括在文本中明确描述的信息,例如颜色,构图等,以及样式,其通常在文本中没有很好地描述,例如位置,数量,大小等。然而,在先前的工作中,通常将其视为仅从内容生成图像的过程,即,不考虑学习有意义的样式表示。在本文中,我们的目的是学习两个在潜在空间中解开的变量,分别代表内容和风格。我们通过使用双重对抗推理机制将当前文本扩展到图像合成框架来实现这一目标。通过大量实验,我们证明了我们的模型以无监督的方式学习了与图像中存在的某些有意义的信息相对应的风格表示,这些信息在文本中没有很好地描述。在Oxford 102,CUB和COCO数据集上进行评估时,新框架还可提高合成图像的质量。 |
| Conv-MCD: A Plug-and-Play Multi-task Module for Medical Image Segmentation Authors Balamurali Murugesan, Kaushik Sarveswaran, Sharath M Shankaranarayana, Keerthi Ram, Jayaraj Joseph, Mohanasankar Sivaprakasam 对于医学图像分割的任务,基于完全卷积网络FCN的体系结构已被广泛地用于各种修改。这些架构的上升趋势是利用辅助任务来采用目标区域的联合学习,这种方法通常称为多任务学习。这些方法有助于实现平滑度和形状先验,而香草FCN方法并不一定包含在内。在本文中,我们提出了一种新颖的即插即用模块,我们称之为Conv MCD,它使用等高线图和ii使用距离图两种方式利用结构信息,这两种方式都可以从地面实况分割图中获得没有额外的注释成本。我们模块的主要优点是易于添加到任何最先进的架构中,从而在最小的参数增加的情况下显着提高了性能。为了证实上述声明,我们在各种评估指标上使用4种最先进的架构进行了大量实验,并报告了与基础网络相关的性能的显着提高。除了上述实验,我们还进行烧蚀研究和特征图的可视化,以进一步阐明我们的方法。 |
| 3D Human Pose Estimation under limited supervision using Metric Learning Authors Rahul Mitra, Nitesh B. Gundavarapu, Sudharshan Chandra Babu, Prashasht Bindal, Abhishek Sharma, Arjun Jain 从单眼图像估计3D人体姿势需要大量3D姿势,并且在野外2D姿势中需要注释数据集,这些数据集成本高且需要复杂的系统来获取。在这方面,我们提出了一种基于度量学习的方法,使用人类运动的多视图同步视频和非常有限的3D姿势注释,从嵌入中联合学习丰富的嵌入和3D姿势回归。当3D监督有限时,将度量学习包含在基线姿态估计框架中可以将性能提高21。此外,我们利用基于人身份的对抗性损失作为额外的弱监督,在使用更小的网络时表现优于现有技术水平。最后,但重要的是,我们展示了学习嵌入的优势,并在两个流行的,公开可用的多视图人体姿势数据集Human 3.6M和MPI INF 3DHP上建立了视图不变姿势检索基准,以便于未来的研究。 |
| A Multimodal Vision Sensor for Autonomous Driving Authors Dongming Sun, Xiao Huang, Kailun Yang 本文描述了一种多模式视觉传感器,它集成了三种类型的摄像机,包括立体摄像机,偏振摄像机和全景摄像机。每个传感器提供特定尺寸的信息,立体相机测量每个像素的深度,偏振获得偏振度,全景相机捕获360度景观。数据融合和先进的环境感知可以建立在传感器的组合之上。该视觉传感器专为自动驾驶而设计,配有强大的语义分段网络。此外,我们演示了如何通过记录彩色图像和偏振图像来实现交叉模态增强。给出了水危害检测的一个例子。为了证明多模态视觉传感器与不同设备的兼容性,进行了简短的运行时性能分析。 |
| A deep learning model for segmentation of geographic atrophy to study its long-term natural history Authors Bart Liefers, Johanna M. Colijn, Cristina Gonz lez Gonzalo, Timo Verzijden, Paul Mitchell, Carel B. Hoyng, Bram van Ginneken, Caroline C.W. Klaver, Clara I. S nchez 目的开发和验证颜色眼底图像CFI中地理萎缩GA自动分割的深度学习模型及其在研究GA生长速度中的应用。参与者使用来自鹿特丹研究RS和蓝山眼科研究BMES的238只GA的238只CFI用于模型开发,以及来自年龄相关眼病研究AREDS的625只眼的5,379 CFI用于分析GA生长率。方法实现了一种基于编码器解码器架构集成的深度学习模型,并对CFI中GA的分段进行了优化。四位经验丰富的评分员在RS和BMES中描述了CFI中的GA。这些手动描绘用于使用5倍交叉验证来评估分割模型。该模型进一步应用于AREDS的CFI,以研究GA的生长速率。线性回归分析用于研究基线时结构生物标志物与GA生长率之间的关联。 GA区域随时间推移的进展的一般估计是通过将所有眼睛的生长速率与来自AREDS集合的GA组合来进行的。结果该模型在BMES和RS上获得的平均Dice系数为0.72 pm 0.26。在自动估计的GA区域和评分者共识测量之间达到0.83的组内相关系数。八个自动计算的结构生物标志物面积,填充面积,凸面积,凸面坚固度,偏心率,圆度,黄斑中心凹和周长与生长速率显着相关。结合所有生长速率表明GA面积平方地增长至约12mm 2的面积,之后生长速率稳定或降低。结论所提出的深度学习模型允许在CFI中对GA进行全自动和稳健的分割。这些分割可用于提取预测其增长率的GA的结构特征。 |
| Towards multi-sequence MR image recovery from undersampled k-space data Authors Cheng Peng, Wei An Lin, Rama Chellappa, S. Kevin Zhou 已经广泛研究了欠采样MR图像恢复以用于加速MR采集。然而,尽管多序列MR扫描在实践中很常见,但它主要在单一序列情况下进行研究。在本文中,我们的目标是在整体时间约束下优化来自欠采样k空间数据的多序列MR图像恢复,同时考虑各种序列的采集时间的差异。我们首先将其表示为约束优化问题,然后表明找到所有序列的最优采样策略和同时最佳恢复模型是组合的,因此计算上是禁止的。为了解决这个问题,我们提出了一种同时恢复多个序列的盲恢复模型,以及一种找到采样策略和恢复模型的正确组合的有效方法。我们的实验表明,所提出的方法优于顺序恢复,并阐明了如何在整个时间预算内决定序列的欠采样策略。 |
| SHREWD: Semantic Hierarchy-based Relational Embeddings for Weakly-supervised Deep Hashing Authors Heikki Arponen, Tom E Bishop 使用类标签来表示类相似性是训练深度哈希系统的典型方法,用于从相同或不同类中检索采样二进制1或0相似值。这种相似性并不模拟数据点之间可能存在的语义关系的全部丰富知识。在这项工作中,我们建立了使用语义层次结构在所有可用样本标签之间形成距离度量的想法,例如,cat to dog的距离小于cat到guitar。我们将这种类型的语义距离组合成一个损失函数,以促进深度神经网络嵌入之间的相似距离。我们还介绍了一个经验性的Kullback Leibler散度损失项,以促进嵌入的二值化和均匀性。我们测试得到的SHREWD方法,并使用紧凑的二进制哈希码而不是实值哈希代码来证明分层检索分数的改进,并表明在弱监督哈希设置中,我们能够在没有明确依赖类标签的情况下进行竞争性学习,而是在标签之间的相似之处。 |
| Deep Slice Interpolation via Marginal Super-Resolution, Fusion and Refinement Authors Cheng Peng, Wei An Lin, Haofu Liao, Rama Chellappa, S. Kevin Zhou 我们提出了一种基于二维卷积神经网络CNN的边缘超分辨率MSR方法,用于沿高度欠采样方向内插各向异性脑磁共振扫描,假设轴向不失一般性。用于切片插值的先前方法仅考虑来自相邻2D切片对的数据。从正交于2D切片的方向融合信息的可能性仍未得到探索。我们的方法在矢状和冠状方向上执行MSR,这提供了切片插值的初始估计。然后将内插切片在轴向上熔合和细化以提高一致性。由于MSR仅包含2D操作,因此在GPU内存消耗方面更可行,并且与3D CNN相比需要更少的训练样本。我们的实验表明,所提出的方法优于传统的线性插值和基于2D 3D CNN的基线方法。我们通过展示该方法在通过语义分割来估计来自欠采样脑MR扫描的脑容量的实际效用得出结论。 |
| Distinction Maximization Loss: Fast, Scalable, Turnkey, and Native Neural Networks Out-of-Distribution Detection simply by Replacing the SoftMax Loss Authors David Mac do 最近,已经提出了许多减少神经网络不确定性的方法。然而,这些解决方案中使用的大多数技术通常存在严重的缺点。在本文中,我们认为神经网络低于分布检测性能主要是由于SoftMax损失各向异性。因此,我们建立了一个各向同性的损失,以减少快速,可扩展,交钥匙和原生方法中的神经网络不确定性。我们的实验表明,我们的建议通常大幅度地克服ODIN,同时通过最先进的Mahalanobis方法产生通常具有竞争力的结果,同时避免其局限性。 |
| Bayesian Generative Models for Knowledge Transfer in MRI Semantic Segmentation Problems Authors Anna Kuzina, Evgenii Egorov, Evgeny Burnaev 基于深度学习的自动分割方法最近证明了最先进的性能,优于普通方法。然而,这些方法不适用于小型数据集,这些数据集在医学问题中非常常见。为此,我们通过Generative Bayesian Prior网络提出了一种疾病之间的知识转移方法。我们的方法与预训练方法和随机初始化相比较,并且就脑肿瘤分割2018数据库BRATS2018的小子集的骰子相似系数度量获得最佳结果。 |
| Automated Rib Fracture Detection of Postmortem Computed Tomography Images Using Machine Learning Techniques Authors Samuel Gunz, Svenja Erne, Eric J. Rawdon, Garyfalia Ampanozi, Till Sieberth, Raffael Affolter, Lars C. Ebert, Akos Dobay 成像技术广泛用于医学诊断。在某些情况下,当缺乏医疗从业者并且必须手动处理图像时,这会导致真正的瓶颈。在这种情况下,需要通过自动化部分分析来减少手动工作量。在本文中,我们通过计算拓扑不变分类器来研究机器学习算法在医学图像处理中的潜力。首先,我们从我们的肋骨骨折死后计算机断层扫描图像数据库中回顾性地选择。通过应用肋展开工具来制备图像,所述肋展开工具使肋骨架变平以形成二维投影。我们将分析结果与两个独立的卷积神经网络模型进行比较。在神经网络模型的情况下,我们获得0.73的F 1分数。为了访问分类器的性能,我们计算了两个类之间未共享的图像的相对比例。我们获得了肋骨骨折图像的精度为0.60。 |
| Multimodal Volume-Aware Detection and Segmentation for Brain Metastases Radiosurgery Authors Szu Yeu Hu, Wei Hung Weng, Shao Lun Lu, Yueh Hung Cheng, Furen Xiao, Feng Ming Hsu, Jen Tang Lu 立体定向放射外科手术SRS可以在一次或几次射击中向小目标提供高剂量的辐射,已成为脑转移的标准治疗方法。虽然非常有效,但SRS目前需要手动密集描绘肿瘤。在这项工作中,我们提出了一种深度学习方法,使用多模态成像和集合神经网络自动检测和分割脑转移。为了解决小的和多个脑转移,我们进一步提出了体积感知骰子损失,其使用病变大小的信息来优化模型性能。这项工作超过了目前的基准水平,并展示了一个可靠的AI辅助系统,用于多发脑转移的SRS治疗计划。 |
| Multimodal Emotion Recognition Using Deep Canonical Correlation Analysis Authors Wei Liu, Jie Lin Qiu, Wei Long Zheng, Bao Liang Lu 多模态信号比情感识别的单峰数据更强大,因为它们可以更全面地表示情绪。在本文中,我们引入深度典型相关分析DCCA到多模态情感识别。 DCCA背后的基本思想是分别转换每个模态,并通过使用指定的规范相关分析约束将不同的模态协调到超空间中。我们在SEED,SEED IV,SEED V,DEAP和DREAMER数据集的五个多模态数据集上评估DCCA的性能。我们的实验结果表明,DCCA在SEED数据集上的所有五个数据集94.58上实现了最先进的识别准确率,在SEED IV数据集上为87.45,在两个二进制分类任务中为84.33和85.62,对于DEAP的四类分类任务为88.51数据集,SEED V数据集上的83.08,以及DREAMER数据集上三个二进制分类任务的88.99,90.57和90.67。我们还将DCCA的噪声鲁棒性与现有方法的噪声鲁棒性进行比较,将各种噪声量添加到SEED V数据集中。实验结果表明DCCA具有更强的鲁棒性。通过使用t SNE可视化特征分布并计算使用DCCA之前和之后不同模态之间的互信息,我们发现DCCA从不同模态转换的特征在情绪上更均匀和有区别。 |
| Graph Convolutional Networks for Coronary Artery Segmentation in Cardiac CT Angiography Authors Jelmer M. Wolterink, Tim Leiner, Ivana I gum 冠状动脉CT血管造影中冠状动脉狭窄的检测CCTA需要高度个性化的表面网状物包围冠状动脉腔。在这项工作中,我们建议使用图形卷积网络GCN来预测管状表面网格中顶点的空间位置,该网格划分冠状动脉管腔。各个顶点位置的预测基于局部图像特征以及网格图中相邻顶点的特征。使用公众可获得的冠状动脉狭窄检测和量化评估框架训练和评估该方法。自动提取包围完整冠状动脉树的表面网格。 78个冠状动脉节段的定量评估显示,这些网格与参考注释密切相关,健康病变血管段的Dice相似系数为0.75 0.73,平均表面距离为0.25±0.28 mm,Hausdorff距离为1.53 1.86 mm。结果表明,在GCN中包含网格信息可改善基线模型上的分割重叠和准确性,而无需在网格上进行交互。结果表明,GCN可以有效提取冠状动脉表面网格,并且使用GCN可以产生规则和更准确的网格。 |
| Robust parametric modeling of Alzheimer's disease progression Authors Mostafa Mehdipour Ghazi, Mads Nielsen, Akshay Pai, Marc Modat, M. Jorge Cardoso, S bastien Ourselin, Lauge S rensen 使用纵向数据对疾病进展的定量表征可以为个体的病理阶段提供长期预测。这项工作使用参数方法研究阿尔茨海默病进展的稳健建模。所提出的方法将个体的实际年龄线性地映射到疾病进展得分DPS,并且使用M估计将约束的广义逻辑函数稳健地拟合到生物标记的纵向动态作为DPS的函数。通过蒙特卡罗重采样使用自举来量化估计的稳健性,并且拐点用于在疾病过程中对模型化生物标记物进行时间排序。此外,使用贝叶斯分类器将核密度估计应用于所获得的用于临床状态预测的DPS。在ADNI数据库中评估了不同的M估计和逻辑函数,包括本研究中提出的一种新的广义类型,称为修正的Stannard,用于体积MRI和PET生物标记的稳健建模,以及神经心理学测试。结果表明,使用修正的Huber损失拟合的修正的Stannard函数实现了最佳的建模性能,所有生物标记和自举的平均绝对误差MMAE均为0.059。此外,应用于ADNI测试集,该模型在临床状态预测的ROC曲线MAUC为0.87的情况下实现了多类区域,并且其显着优于类似的现有方法,生物标记建模MMAE为0.059对0.061 p 0.001。最后,实验表明,使用丰富的ADNI数据训练的所提出的模型很好地推广到来自独立NACC数据库的数据,其中与使用相对稀疏的NACC数据训练的模型相比,建模和诊断性能均显着提高了0.001。 |
| Recognition of Ischaemia and Infection in Diabetic Foot Ulcers: Dataset and Techniques Authors Manu Goyal, Neil Reeves, Satyan Rajbhandari, Naseer Ahmad, Chuan Wang, Moi Hoon Yap 糖尿病足溃疡DFU使用计算机化方法检测是一个新兴的研究领域,随着机器学习算法的发展。然而,现有研究的重点是检测和分割溃疡。根据DFU医学分类系统,即德克萨斯大学分类和SINBAD分类,伤口中感染细菌的存在和缺血供血不足对DFU评估具有重要的临床意义,其用于预测截肢的风险。在这项工作中,我们提出了一个新的数据集和新技术,以确定感染和缺血的存在。我们介绍了一个非常全面的DFU数据集,其中包含缺血和感染病例的基本事实标签。对于手工制作的机器学习方法,我们提出了新的特征描述符,即超像素颜色描述符。然后,我们提出了一种使用Ensemble卷积神经网络CNN模型进行缺血和感染识别的技术。新颖性在于我们提出的自然数据增强方法,该方法清楚地识别足部图像上的感兴趣区域,并侧重于找到该区域中存在的显着特征。最后,我们评估了我们提出的二元分类技术的性能,即缺血与非缺血和感染与非感染。总体而言,我们提出的方法在感染的分类中比感染更好。我们发现我们提出的Ensemble CNN深度学习算法对于两种分类任务都比手工制作的机器学习算法表现更好,在缺血分类中有90个准确度,在感染分类中有73个。 |
| Chinese Abs From Machine Translation |
Papers from arxiv.org
更多精彩请移步主页

pic from pexels.com