菜鸟学习tensorflow2
我询问了前一篇我提到很推崇的那个博主学习tensorflow的方法,他是先看书籍《深度学习之Tensorflow入门原理与进阶实战》,然后再看MOOC上北京大学曹健老师的《人工智能实践:tensorflow笔记》视频课程,每看完书的一部分就去看视频的对应部分。我觉得他介绍的这两个学习资源很好。我找了很久终于找到了,现在正式开始按部就班的学习。
一、《深度学习之Tensorflow入门原理与进阶实战》
1、第三章
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
trainx=np.linspace(-1,1,100)
trainy=2*trainx+np.random.randn(*trainx.shape)*0.3
#y=2x with noise
plt.plot(trainx,trainy,'ro',label='original data')
plt.legend()
plt.show()
X=tf.placeholder("float")
Y=tf.placeholder("float")
w=tf.Variable(tf.random_normal([1]),name="weight")
b=tf.Variable(tf.zeros([1]),name="bias")
z=tf.multiply(X,w)+b
cost=tf.reduce_mean(tf.square(Y-z))
learning_rate=0.01
optimizer=tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
trainepoch=20
displaystep=2
plotdata = { "batchsize": [] , "loss": [] }
def moving_average(a, w=10):
if len(a) < w:
return a[:]
return [val if idx < w else sum(a[(idx-w):idx])/w for idx, val in enumerate(a)]
saver=tf.train.Saver()
with tf.Session() as sess:
init=tf.global_variables_initializer()
sess.run(init)
for epoch in range(trainepoch):
for (x,y) in zip(trainx,trainy):
sess.run(optimizer,feed_dict={X:x,Y:y})
if epoch%displaystep==0:
loss=sess.run(cost,feed_dict={X:trainx,Y:trainy})
print("epoch:",epoch+1,"cost=",loss,"w=",sess.run(w),"b=",sess.run(b))
if not(loss=="NA"):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
print("Finished!")
print("cost=",sess.run(cost,feed_dict={X:trainx,Y:trainy}),"w=",sess.run(w),"b=",sess.run(b))
saver.save(sess,"D:/CUDA/tensorflow_exam/study/3tensorflow-practice/the3rdmodel")我觉得书上说学习率就像显微镜调焦时的调焦按钮很形象,太大虽然训练速度快但是可能在收敛最小值附近波动而不收敛;太小则训练过慢。其实可以把占位符理解成C++中的变量声明或形参,而实参是在session.run下才可以。网络参数的初始化我记得可以全0初始化也可以随机初始化,那么权重、偏置都随便初始化就像上面这样?还是说权重只能随机初始化,偏置只能全0初始化。
在反馈传播中,每个epoch中,训练数据是每个batch的x和y。每2个epoch就计算一次loss,loss是用的mse来衡量,这里每计算一次loss就需要全部的x和y,我好像记得这种方式并不好,当数据太大时非常耗GPU?
训练完模型后,可以可视化模型、进行预测。由整个例子可以看到tensorflow处理流程:
a、用占位符或字典(数据较多时)定义输入xy
b、直接定义或字典定义网络参数变量如权重偏置wb
c、定义运算op:包括前向结构(不会像上个例子w*x+b这样简单,而是多层NN、ResNet等网络)和反向传播的运算如loss(记住常用的几种就好)
d、反向传播的目标函数(记住常用的几种即可)来调整网络参数(这其中涉及很多技巧:正则化、学习率自适应等)
e、创建session初始化所有变量
f、迭代更新参数得到最优解2、第四章
由之前的了解和这章的解说,其实已经知道tensorflow中 只有session范围内各种常量变量张量和计算操作op才是活了一样,走出session的范围是无法打印各种常量或者进行任何实质的计算,都成了形式而已。所以要实质的进行任何输入输出或者打印计算或保存模型等操作一定要在session内。
a、session的注入机制feed,可以理解为给函数(网络/图)传实参(喂入数据)。b、模型的保存与载入,我试了下保存时OK的可以保存到指定路径,但是载入好像有问题可能时我版本与书上版本不一样所致?会报以下的错误:
#saver=tf.train.Saver(max_to_keep=1)
with tf.Session() as sess:
init=tf.global_variables_initializer()
sess.run(init)
for epoch in range(trainepoch):
for (x,y) in zip(trainx,trainy):
sess.run(optimizer,feed_dict={X:x,Y:y})
if epoch%displaystep==0:
loss=sess.run(cost,feed_dict={X:trainx,Y:trainy})
print("epoch:",epoch+1,"cost=",loss,"w=",sess.run(w),"b=",sess.run(b))
if not(loss=="NA"):
plotdata["batchsize"].append(epoch)
plotdata["loss"].append(loss)
#saver.save(sess,"D:/CUDA/tensorflow_exam/study/3tensorflow-practice/the3rdmodel",global_step=epoch)
print("Finished!")
print("cost=",sess.run(cost,feed_dict={X:trainx,Y:trainy}),"w=",sess.run(w),"b=",sess.run(b))
#saver.save(sess,"D:/CUDA/tensorflow_exam/study/3tensorflow-practice/the3rdmodel")
load_epoch=18
saver2=tf.train.Saver()
with tf.Session() as sess2:
saver2.restore(sess2,"D:/CUDA/tensorflow_exam/study/3tensorflow-practice/3/the3rdmodel")
#saver2.restore(sess2,"D:/CUDA/tensorflow_exam/study/3tensorflow-practice/3/the3rdmodel"+str(load_epoch))
# =============================================================================
# WARNING: Logging before flag parsing goes to stderr.
# W0904 16:21:57.462688 5884 deprecation.py:323] From D:\CUDA\anaconda\lib\site-packages\tensorflow\python\training\saver.py:1276: checkpoint_exists (from tensorflow.python.training.checkpoint_management) is deprecated and will be removed in a future version.
# Instructions for updating:
# Use standard file APIs to check for files with this prefix.
# ============================================================================= b、按epoch来保存中间模型:模型训练过程中可能突然中断,比如停电了,那么在训练中边保存模型就很有必要(保存检查点)。可以每个epoch保存一次模型,但是如果每个epoch都保存一次模型,那样会保存太多的模型,其实我们只要停电的前一次模型就好了,所以上面max_to_keep=1就时这个作用,蛮实用。因为只保存了停电前的模型,所以要去路径下看保存的epoch是第几次的,然后加载时就加载文件夹名对应就行。
c、按训练时间来保存中间模型:一定时间保存一次模型,我感觉我喜欢上一种保存模型的方式即按epoch来保存。
d、tensorflow提供了TensorBoard可视化工具:等需要用时直接来看就好了。
e、tensorflow的基础语法:张量tensor的类型如DT_FLOAT等-->故有类型转换操作、形状即几行几列--->故有形状变换操作和阶,张量涉及的操作很多数值运算、矩阵运算等等,(用时可以来查表)如之前说的那样必须在session下才是活的。特别提到一个规约运算函数形式时reduce_xxx(),xxx有降维作用,如reduce_sum那么出来的只是一个和达到了降维的目的。注意axis=0表示按列计算,axis=1表示按行计算。另外还有序列比较和索引提取,在依据概率判断属于哪个类别时很重要。
f、共享变量我目前用不到,我不会同时训练两个模型,所以暂时不存在一个模型需要另一个模型变量的情况。从下面这个例子可以看到变量只认name不认变量名,所以当不同变量名的name都相同时,tensorflow会自动的在name后面加_0、_1、_2等。
import tensorflow as tf
a = tf.placeholder(tf.int16)
b = tf.placeholder(tf.int16)
add = tf.add(a, b)
mul = tf.multiply(a, b)
#saver=tf.train.Saver()
with tf.Session() as sess:
with tf.device("/gpu:0"):
print ("相加: %i" % sess.run(add, feed_dict={a: 3, b: 4}))
print ("相乘: %i" % sess.run(mul, feed_dict={a: 3, b: 4}))
print("together: ",sess.run([mul,add],feed_dict={a: 3, b: 4}))
#saver.restore(sess,"D:/CUDA/tensorflow_exam/study/3tensorflow-practice/3/the3rdmodel")
var1=tf.Variable(1.0,name='the1st')
print(var1)
print("var1:",var1.name)
var1=tf.Variable(2.0,name='the1st')
print("var1:",var1.name)
var2=tf.Variable(3.0)
print("var2:",var2.name)
var2=tf.Variable(4.0)
print("var2:",var2.name)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("var1=",var1.eval())
print("var2=",var2.eval())
get_var1=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
print("get_var1:",get_var1.name)
get_var1=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.4))
print("get_var1:",get_var1.name)对共享变量(get_variable定义的变量)而言,对于同一个name只能定义一次,无论换不换变量名。一句话来说,普通变量对于同一个name可以定义不同的变量名或同一个变量名靠不同的值定义多次,即可以一对多;但是共享变量对于同一个name却只可以定义一次,无论是同一个变量名多次或不同变量名一次都不行,只能一对一。除非使用作用域variable_scope将两个name的变量隔开,如下所示:
get_var1=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
print("get_var1:",get_var1.name)
#can not declarate variables having the same name.
#get_var2=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.4))
#print("get_var2:",get_var2.name)
with tf.variable_scope("test1",):
get_var3=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
with tf.variable_scope("test2",):
get_var4=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
#我以为这个变量只在作用域(那个with)下有效,像子函数一样,原来不是
#出了那个作用域,这个变量依旧有效,原来只是同name变量定义需放到不同作用域下而已
print("get_var3:",get_var3.name)
print("get_var4:",get_var4.name)
with tf.variable_scope("test1",reuse=True):
get_var5=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
with tf.variable_scope("test2",reuse=True):
get_var6=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
print("get_var5:",get_var5.name)
print("get_var6:",get_var6.name)
#can not share variables having the same name in different varible scopes
# =============================================================================
# with tf.variable_scope("test3",reuse=True):
# get_var7=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
#
# with tf.variable_scope("test4",reuse=True):
# get_var8=tf.get_variable("the1st",[1],initializer=tf.constant_initializer(0.3))
# print("get_var7:",get_var7.name)
# print("get_var8:",get_var8.name)
# =============================================================================作用域variablescope我以为像C++的子函数,出了with定义的scope竟然还可以对变量进行打印,感觉作用域只是为定义同name变量提供的临时保护伞,并不是牢笼,所以变量出了scope还可以操作。另外要共享同name变量必须在同名scope下,否则无法共享。另外variablescope除了可以定义作用域为共享变量提供保护伞,还可以顺便初始化这个变量。
g、图:之前的所有例子都是有默认建立图的,tensorflow会默认建议一个图,就像之前例子中模型的常量变量张量都是默认图的一部分。所以图一直是隐身存在的。当然tensorflow也支持手动建立操作用户自定义的显示图:
c=tf.constant(0.0)
g=tf.Graph()
with g.as_default():
c1=tf.constant(0.0)
print(c1.graph)
print(g)
print(c.graph)
g2=tf.get_default_graph()
print(g2)
tf.reset_default_graph()
g3=tf.get_default_graph()
print(g3)
print(c1.name)
#get information of tensor in graph
t=g.get_tensor_by_name(name="Const:0")
print(t)
obja=tf.constant([[1.0,2.0]])
objb=tf.constant([[1.0],[3.0]])
tensor1=tf.matmul(obja,objb,name='the1stop')
print(tensor1)
print(tensor1.name,tensor1)
test=g3.get_tensor_by_name("the1stop:0")
print(test)
print(tensor1.op.name)
testop=g3.get_operation_by_name("the1stop")
print(testop)
with tf.Session() as sess2:
testnow0=sess2.run(tensor1)
print(testnow0)
testnow=sess2.run(test)
print(testnow)
testnow2=tf.get_default_graph().get_tensor_by_name("the1stop:0")
print(testnow2)我之前一直以为tensorflow中常量变量张量都是tensorflow的数据类型,op是表示操作或运算比如数据之间的加减乘除等,所以以上代码中tensor1的命名应该叫op1之类。原来并非如此,运算如tf.matmul它依旧是张量,而op是张量之间的运算关系!并非运算本身。op只能通过运算如tf.matmul的name由函数get_operation_by_name去获得!!!另外运算如tf.matmul返回的张量tensor1只能在session才能活着运算出结果testnow0,但同时也可以运算这个tensor的name来得到运算结果testnow。我还是喜欢直接运算tf.matmul的tensor1.
h、分布式Tensorflow:大型数据集上的训练用单机很慢,如果能够几台机协同训练一个模型将缩短训练时间提高效率。很激动的看完了这部分内容,这是一个好东西啊!但是不知道对另几台合作的机器有没有要求,如和我这台机器相同版本的tensorflow、GPU型号、tensorflow安装的是GPU版本还是CPU版本等等才能协同训练一个模型?我看了下书上说的ps定义的这台IP对应的主机只起到连接各个端口作用,那么其实它不参与计算,只有workers对应的机器才参加计算训练模型,那么这样说来我必须除了自己的机器作为ps端,另外要再搞至少两台别的机器才可以算得上是分布式训练?
等会儿我实验一下。这里暂时先空着,到时候实验完毕补上。
i、动态图Eager:比静态图快,不需要session来让所有计算活起来。我在想我之前做那么多tensorflow C++提速优化工作比如开启SSE4.1/SSE4.2/AVX/XLA/FMA加速指令集、使用batch inference、使用MKL等优化,预测的时间始终很慢,或许可以考虑使用动态图Eager,也许会比之前做的那些工作更有效提高速度。不过书里介绍较少,我准备学习完书和视频,再去查下关于动态图的信息并测试对比。
3、第五章
这一章主要通过mnist例子讲了如何搭建实质性网络模型、训练、保存模型并进行预测分类。这里不细说,因为上一篇我从那个博主文章里已经实践过了。
4、第六章
这一章内容其实和我之前收集的关于神经网络介绍的各个网站类似,介绍了单层网络下激活函数、损失函数、梯度下降。
1、激活函数(类似之前的w*x+b这种函数关系)的作用就是让模型具有非线性,具有强大的泛化能力。多种激活函数中Relu较常用,但它会抑制全部的负值。其变种Elus好像更好一点,收敛更快,不用使用batch处理效果也很好。还有Swish函数书上也很提倡。等我实际应用时,这三种我都会尝试一下对比。
2、损失函数:对训练集和测试集进行一样的数据处理从而让数据分布相同,然后计算正向传播预测值与真实值之间的误差,让这个误差不断收敛到符合我们要求的那么小而产生的网络就是我们期望训练出的网络。损失函数主要有均值误差MSE和交叉熵Tensorflow没有提供官方MSE函数,所以只能自己定义MSE,tf.reduce_mean(可有多种写法)(之前mnist例子就用了);交叉熵函数tensorflow提供了三四种,其中大名鼎鼎的时softmax交叉熵tf.nn.softmax_cross_entropy_with_logits().
import tensorflow as tf
#one hot label
labels=[[0,0,1],[0,1,0]]
logits=[[2,0.5,6],[0.1,0,3]]
logits_scaled=tf.nn.softmax(logits)
result1=tf.nn.softmax_cross_entropy_with_logits(labels=labels,logits=logits)
#wrong
#logits_scaled2=tf.nn.softmax(logits_scaled)
#result2=tf.nn.softmax_cross_entropy_with_logits(labels=labels,logits=logits_scaled)
#result3=-tf.reduce_sum(labels*tf.log(logits_scaled),1)
with tf.Session() as sess:
print(sess.run(logits_scaled))
print("result1:",sess.run(result1))
#print(sess.run(logits_scaled2))
#print("result2:",sess.run(result2))
#print("result3:",sess.run(result3))
#compare with one hot labels,one hot is better
labels2=[[0.4,0.1,0.5],[0.3,0.6,0.1]]
result4=tf.nn.softmax_cross_entropy_with_logits(labels=labels2,logits=logits)
with tf.Session() as sess2:
print("result4",sess2.run(result4))
resulttmp=tf.nn.softmax_cross_entropy_with_logits_v2(labels=labels2,logits=logits)
with tf.Session() as sess3:
print("result5",sess3.run(resulttmp))
#############################################
#can not use one hot labels
labels3=[2,1]
result6=tf.nn.sparse_softmax_cross_entropy_with_logits(labels=labels3,logits=logits)
with tf.Session() as sess4:
print("result6:",sess4.run(result6))
#as good as softmax_cross_entropy_with_logits with one hot label
#############################################
#softmax just can get array but not a const value
#calculating loss is converting array to a const value
loss=tf.reduce_sum(result1)
with tf.Session() as sess5:
print("loss=",sess5.run(loss))之前一直搞不清softmax或者mse所计算的正向传播预测结果与真实label之间的距离与loss的关系,原来它们计算完毕只是数组,而loss要的只是一个数值,所以计算数组均值就得到loss。
3、梯度下降:帮助寻找到最小的loss,从而反推出最小loss对应的网络参数b和w,即最终的网络。梯度下降方法有好几种,用得较多的就是mini-batch SGD。梯度下降有不同的优化器可使用,常见的是 optimizer=tf.train.GradientDescentOptimizer(learning_rate,use_locking=False,name='GradientDescent') .minimize(loss)再启动一个外循环,这句代码就会按照循环的次数一次次沿着loss最小值的方向优化网络参数。
4、学习率退化:因为学习率过大训练虽然快但精度不高;学习率过小精度可能高但训练慢。所以现实中训练常用办法是先使用较大学习率,然后让其慢慢变小的策略。
global_step = tf.Variable(0, trainable=False)
initial_learning_rate = 0.1 #初始学习率
learning_rate = tf.train.exponential_decay(initial_learning_rate,
global_step,
decay_steps=10,decay_rate=0.9)
opt = tf.train.GradientDescentOptimizer(learning_rate)
add_global = global_step.assign_add(1)
with tf.Session() as sess:
tf.global_variables_initializer().run()
print(sess.run(learning_rate))
for i in range(20):
g, rate = sess.run([add_global, learning_rate])
print(g,rate)如上面所示,当步数到达10步后,每一步减小为原来的0.9。
5、单个神经元maxout:
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("MNIST_data/")
print ('输入数据:',mnist.train.images)
print ('输入数据打shape:',mnist.train.images.shape)
import pylab
im = mnist.train.images[1]
im = im.reshape(-1,28)
pylab.imshow(im)
pylab.show()
print ('输入数据打shape:',mnist.test.images.shape)
print ('输入数据打shape:',mnist.validation.images.shape)
import tensorflow as tf #导入tensorflow库
tf.reset_default_graph()
# tf Graph Input
x = tf.placeholder(tf.float32, [None, 784]) # mnist data维度 28*28=784
y = tf.placeholder(tf.int32, [None]) # 0-9 数字=> 10 classes
# Set model weights
W = tf.Variable(tf.random_normal([784, 10]))
b = tf.Variable(tf.zeros([10]))
z= tf.matmul(x, W) + b
maxout = tf.reduce_max(z,axis= 1,keep_dims=True)
# Set model weights
W2 = tf.Variable(tf.truncated_normal([1, 10], stddev=0.1))
b2 = tf.Variable(tf.zeros([1]))
# 构建模型
pred = tf.nn.softmax(tf.matmul(maxout, W2) + b2)
# 构建模型
#pred = tf.nn.softmax(z) # Softmax分类
# Minimize error using cross entropy
#cost = tf.reduce_mean(-tf.reduce_sum(y*tf.log(pred), reduction_indices=1))
cost = tf.reduce_mean(tf.nn.sparse_softmax_cross_entropy_with_logits(labels=y, logits=z))
#参数设置
learning_rate = 0.04
# 使用梯度下降优化器
optimizer = tf.train.GradientDescentOptimizer(learning_rate).minimize(cost)
training_epochs = 200
batch_size = 100
display_step = 1
# 启动session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())# Initializing OP
# 启动循环开始训练
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# 遍历全部数据集
for i in range(total_batch):
batch_xs, batch_ys = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_xs,
y: batch_ys})
# Compute average loss
avg_cost += c / total_batch
# 显示训练中的详细信息
if (epoch+1) % display_step == 0:
print ("Epoch:", '%04d' % (epoch+1), "cost=", "{:.9f}".format(avg_cost))
print( " Finished!")这个比普通单个神经元要精度高,但可能会导致训练太慢。
5、第七章
这一章的内容也比较重要,很有用。现实项目中基本上用到的都是多层神经网络,来增加模型的非线性,提高泛化能力。
1、两个模拟线性分类的例子,一个是二分类,一个是多分类。二分类使用的是固定learning rate,损失函数是用的自定义的
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
from sklearn.utils import shuffle
#模拟数据点
def generate(sample_size, mean, cov, diff,regression):
num_classes = 2 #len(diff)
samples_per_class = int(sample_size/2)
X0 = np.random.multivariate_normal(mean, cov, samples_per_class)
Y0 = np.zeros(samples_per_class)
for ci, d in enumerate(diff):
X1 = np.random.multivariate_normal(mean+d, cov, samples_per_class)
Y1 = (ci+1)*np.ones(samples_per_class)
X0 = np.concatenate((X0,X1))
Y0 = np.concatenate((Y0,Y1))
if regression==False: #one-hot 0 into the vector "1 0
class_ind = [Y==class_number for class_number in range(num_classes)]
Y = np.asarray(np.hstack(class_ind), dtype=np.float32)
X, Y = shuffle(X0, Y0)
return X,Y
input_dim = 2
np.random.seed(10)
num_classes =2
mean = np.random.randn(num_classes)
cov = np.eye(num_classes)
X, Y = generate(1000, mean, cov, [3.0],True)
colors = ['r' if l == 0 else 'b' for l in Y[:]]
plt.scatter(X[:,0], X[:,1], c=colors)
plt.xlabel("Scaled age (in yrs)")
plt.ylabel("Tumor size (in cm)")
plt.show()
lab_dim = 1
# tf Graph Input
input_features = tf.placeholder(tf.float32, [None, input_dim])
input_labels = tf.placeholder(tf.float32, [None, lab_dim])
# Set model weights
W = tf.Variable(tf.random_normal([input_dim,lab_dim]), name="weight")
b = tf.Variable(tf.zeros([lab_dim]), name="bias")
output =tf.nn.sigmoid( tf.matmul(input_features, W) + b)
ser= tf.square(input_labels - output)
err = tf.reduce_mean(ser)
cross_entropy = -(input_labels * tf.log(output) + (1 - input_labels) * tf.log(1 - output))
loss = tf.reduce_mean(cross_entropy)
optimizer = tf.train.AdamOptimizer(0.04) #尽量用这个--收敛快,会动态调节梯度
train = optimizer.minimize(loss) # let the optimizer train
#optimizer = tf.train.AdamOptimizer(0.04).minimize(loss)
maxEpochs = 50
minibatchSize = 25
# 启动session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(maxEpochs):
sumerr=0
for i in range(np.int32(len(Y)/minibatchSize)):
x1 = X[i*minibatchSize:(i+1)*minibatchSize,:]
y1 = np.reshape(Y[i*minibatchSize:(i+1)*minibatchSize],[-1,1])
tf.reshape(y1,[-1,1])
_,lossval, outputval,errval = sess.run([train,loss,output,err], feed_dict={input_features: x1, input_labels:y1})
#_,lossval, outputval,errval = sess.run([optimizer,loss], feed_dict={input_features: x1, input_labels:y1})
sumerr =sumerr+errval
print ("Epoch:", '%04d' % (epoch+1), "cost=","{:.9f}".format(lossval),"err=",sumerr/np.int32(len(Y)/minibatchSize))
#图形显示
train_X, train_Y = generate(100, mean, cov, [3.0],True)
colors = ['r' if l == 0 else 'b' for l in train_Y[:]]
plt.scatter(train_X[:,0], train_X[:,1], c=colors)
#plt.scatter(train_X[:, 0], train_X[:, 1], c=train_Y)
#plt.colorbar()
# x1w1+x2*w2+b=0
# x2=-x1* w1/w2-b/w2
x = np.linspace(-1,8,200)
y=-x*(sess.run(W)[0]/sess.run(W)[1])-sess.run(b)/sess.run(W)[1]
plt.plot(x,y, label='Fitted line')
plt.legend()
plt.show() 这个例子session里面session.run()是不是几个参数就返回几个结果?之前的例子都是sess.run(optimizer,cost)所以就只返回两个参数,这个例子参数有四个,所以就返回了对应的四个结果。sess.run()参数里是不是所有与w和b有关的tensor都要作为参数放进来,否则无法完成正确的迭代更新wb。
2、非线性分类:无法像线性分类一样用不同的直线将几个类数据分开时需要非线性分类,如多层神经网络。首先举的是用一层隐藏层加一层输出层:
import tensorflow as tf
import numpy as np
# 网络结构:2维输入 --> 2维隐藏层 --> 1维输出
learning_rate = 1e-4
n_input = 2
n_label = 1
n_hidden = 2
x = tf.placeholder(tf.float32, [None,n_input])
y = tf.placeholder(tf.float32, [None, n_label])
#生成数据
X=[[0,0],[0,1],[1,0],[1,1]]
Y=[[0],[1],[1],[0]]
X=np.array(X).astype('float32')
Y=np.array(Y).astype('int16')
weights = {
'h1': tf.Variable(tf.truncated_normal([n_input, n_hidden], stddev=0.1)),
'h2': tf.Variable(tf.random_normal([n_hidden, n_label], stddev=0.1))
}
biases = {
'h1': tf.Variable(tf.zeros([n_hidden])),
'h2': tf.Variable(tf.zeros([n_label]))
}
layer_1 = tf.nn.relu(tf.add(tf.matmul(x, weights['h1']), biases['h1']))
y_pred = tf.nn.tanh(tf.add(tf.matmul(layer_1, weights['h2']),biases['h2']))
loss=tf.reduce_mean((y_pred-y)**2)
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
#加载
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
#训练
for i in range(10000):
sess.run(train_step,feed_dict={x:X,y:Y} )
#计算预测值
print(sess.run(y_pred,feed_dict={x:X}))
#输出:已训练100000次
#查看隐藏层的输出
print(sess.run(layer_1,feed_dict={x:X}))这个例子比较简单。输出如下:
[[0.54473066]
[0.54472923]
[0.5447224 ]
[0.38365033]]
[[0.0000000e+00 0.0000000e+00]
[0.0000000e+00 5.1259995e-06]
[0.0000000e+00 2.9742718e-05]
[0.0000000e+00 5.8101523e-01]]关系如下图所示。但是第一次看到sess = tf.InteractiveSession()这样来创建session,没用with,那后面run第一层第二层结果都在这个session里?而且这个session没看到被手动close啊。我一直在想之前书上说tf的函数要在session下才能算激活,sess.run(train_step,feed_dict={x:X,y:Y} )这句是不是运行了train_step,而train_step的运行依赖于loss的运行,loss的运行又依赖于y_pred运行,y_pred运行又依赖于layer_1的运行。所以不用单独run上面那些tf函数,而只用run一个train_step就可以了?应该是这样吧。

但输出层换不同的激活函数时我测试没发现Relu使用后陷入了局部最优解啊,难道下面输出结果全时0.33333就是局部最优解?
[[0.33333543]
[0.9999989 ]
[0.33333543]
[0.33333543]]
[[0. 0. ]
[0.6142971 0.56117046]
[0. 0. ]
[0. 0. ]]还有什么样才是梯度消失,怎么看?书上说迭代到20000梯度消失,但是我没发现全0的现象啊?哦知道了梯度消失就是loss没有任何下降一直是某个数。下面这个例子比上面模型结构要开始复杂一点了,两个隐藏层加一个输出层共三层来对mnist图片分类。
# 网络结构:mnist784维输入 --> 256维隐藏层--> 256维隐藏层 --> 10维输出
from tensorflow.examples.tutorials.mnist import input_data
mnist = input_data.read_data_sets("/data/", one_hot=True)
#参数设置
learning_rate = 0.001
training_epochs = 25
batch_size = 100
display_step = 1
# Network Parameters
n_hidden_1 = 256 # 1st layer number of features
n_hidden_2 = 256 # 2nd layer number of features
n_input = 784 # MNIST data 输入 (img shape: 28*28)
n_classes = 10 # MNIST 列别 (0-9 ,一共10类)
# tf Graph input
x = tf.placeholder("float", [None, n_input])
y = tf.placeholder("float", [None, n_classes])
# Store layers weight & bias
weights = {
'h1': tf.Variable(tf.random_normal([n_input, n_hidden_1])),
'h2': tf.Variable(tf.random_normal([n_hidden_1, n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_hidden_2, n_classes]))
}
biases = {
'b1': tf.Variable(tf.random_normal([n_hidden_1])),
'b2': tf.Variable(tf.random_normal([n_hidden_2])),
'out': tf.Variable(tf.random_normal([n_classes]))
}
# Create model
def multilayer_perceptron(x, weights, biases):
# Hidden layer with RELU activation
layer_1 = tf.add(tf.matmul(x, weights['h1']), biases['b1'])
layer_1 = tf.nn.relu(layer_1)
# Hidden layer with RELU activation
layer_2 = tf.add(tf.matmul(layer_1, weights['h2']), biases['b2'])
layer_2 = tf.nn.relu(layer_2)
# Output layer with linear activation
out_layer = tf.matmul(layer_2, weights['out']) + biases['out']
return out_layer
# 构建模型
pred = multilayer_perceptron(x, weights, biases)
# Define loss and optimizer
cost = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(logits=pred, labels=y))
optimizer = tf.train.AdamOptimizer(learning_rate=learning_rate).minimize(cost)
# 启动session
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
# 启动循环开始训练
for epoch in range(training_epochs):
avg_cost = 0.
total_batch = int(mnist.train.num_examples/batch_size)
# 遍历全部数据集
for i in range(total_batch):
batch_x, batch_y = mnist.train.next_batch(batch_size)
# Run optimization op (backprop) and cost op (to get loss value)
_, c = sess.run([optimizer, cost], feed_dict={x: batch_x,y: batch_y})
# Compute average loss
avg_cost += c / total_batch
# 显示训练中的详细信息
if epoch % display_step == 0:
print ("Epoch:", '%04d' % (epoch+1), "cost=", \
"{:.9f}".format(avg_cost))
print (" Finished!")
# 测试 model
correct_prediction = tf.equal(tf.argmax(pred, 1), tf.argmax(y, 1))
# 计算准确率
accuracy = tf.reduce_mean(tf.cast(correct_prediction, "float"))
print ("Accuracy:", accuracy.eval({x: mnist.test.images, y: mnist.test.labels}))这个例子结构很清晰,搭建简单,准确率达到95%以上。增加隐藏层的层数、节点个数即维度一定程度上可以提高模型精度降低训练难度,但并不意味着层数和节点越多越好,要测试才知道。
3、训练技巧:通过熟悉的实例演示了过拟合欠拟合,总所周知early stopping、data augmentation、regularization、dropout等可以一定程度上解决过拟合问题。
a、先说的是正则化regularization: 正则化就是在计算loss后加一项干扰项,让loss结果与标准结果的loss不一样,导致反向传播的w和b无法按标准结果的loss的w、b一样调整,那么模型就与标准样本的模型不一样,从而达到防止过拟合目的。(感觉此时此刻的我才真正理解了什么是regularization,之前看的那些关于正则化的语言描述的定义都没真正理解过)所以,如果模型本身就是欠拟合状态,那肯定希望加干扰项后的loss尽量与标准loss一样;如果模型已经是过拟合了,那就希望加干扰项后的loss与标准loss差别尽量大。 L1范数正则化就是指加在loss后的这个干扰项=所有参数w的绝对值之和;L2范数正则化就是指加在loss后的这个干扰项=所有参数w的平方和然后求平方根。 这两种正则化对应的函数是tf.reduce_sum(tf.abs(w))、tf.nn.l2_loss(t,name=None)
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
from sklearn.utils import shuffle
from matplotlib.colors import colorConverter, ListedColormap
# 对于上面的fit可以这么扩展变成动态的
from sklearn.preprocessing import OneHotEncoder
def onehot(y,start,end):
ohe = OneHotEncoder()
a = np.linspace(start,end-1,end-start)
b =np.reshape(a,[-1,1]).astype(np.int32)
ohe.fit(b)
c=ohe.transform(y).toarray()
return c
def generate(sample_size, num_classes, diff,regression=False):
np.random.seed(10)
mean = np.random.randn(2)
cov = np.eye(2)
#len(diff)
samples_per_class = int(sample_size/num_classes)
X0 = np.random.multivariate_normal(mean, cov, samples_per_class)
Y0 = np.zeros(samples_per_class)
for ci, d in enumerate(diff):
X1 = np.random.multivariate_normal(mean+d, cov, samples_per_class)
Y1 = (ci+1)*np.ones(samples_per_class)
X0 = np.concatenate((X0,X1))
Y0 = np.concatenate((Y0,Y1))
if regression==False: #one-hot 0 into the vector "1 0
Y0 = np.reshape(Y0,[-1,1])
#print(Y0.astype(np.int32))
Y0 = onehot(Y0.astype(np.int32),0,num_classes)
#print(Y0)
X, Y = shuffle(X0, Y0)
#print(X, Y)
return X,Y
# Ensure we always get the same amount of randomness
np.random.seed(10)
input_dim = 2
num_classes =4
X, Y = generate(120,num_classes, [[3.0,0],[3.0,3.0],[0,3.0]],True)
Y=Y%2
colors = ['r' if l == 0.0 else 'b' for l in Y[:]]
plt.scatter(X[:,0], X[:,1], c=colors)
plt.xlabel("Scaled age (in yrs)")
plt.ylabel("Tumor size (in cm)")
plt.show()
Y=np.reshape(Y,[-1,1])
learning_rate = 1e-4
n_input = 2
n_label = 1
n_hidden = 200
x = tf.placeholder(tf.float32, [None,n_input])
y = tf.placeholder(tf.float32, [None, n_label])
weights = {
'h1': tf.Variable(tf.truncated_normal([n_input, n_hidden], stddev=0.1)),
'h2': tf.Variable(tf.random_normal([n_hidden, n_label], stddev=0.1))
}
biases = {
'h1': tf.Variable(tf.zeros([n_hidden])),
'h2': tf.Variable(tf.zeros([n_label]))
}
layer_1 = tf.nn.relu(tf.add(tf.matmul(x, weights['h1']), biases['h1']))
#Leaky relus
layer2 =tf.add(tf.matmul(layer_1, weights['h2']),biases['h2'])
y_pred = tf.maximum(layer2,0.01*layer2)
#L2 regularization
reg = 0.01
loss=tf.reduce_mean((y_pred-y)**2)+tf.nn.l2_loss(weights['h1'])*reg+tf.nn.l2_loss(weights['h2'])*reg
train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
#加载
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
for i in range(20000):
X, Y = generate(1000,num_classes, [[3.0,0],[3.0,3.0],[0,3.0]],True)
Y=Y%2
Y=np.reshape(Y,[-1,1])
_, loss_val = sess.run([train_step, loss], feed_dict={x: X, y: Y})
if i % 1000 == 0:
print ("Step:", i, "Current loss:", loss_val)
colors = ['r' if l == 0.0 else 'b' for l in Y[:]]
plt.scatter(X[:,0], X[:,1], c=colors)
plt.xlabel("Scaled age (in yrs)")
plt.ylabel("Tumor size (in cm)")
nb_of_xs = 200
xs1 = np.linspace(-1, 8, num=nb_of_xs)
xs2 = np.linspace(-1, 8, num=nb_of_xs)
xx, yy = np.meshgrid(xs1, xs2) # create the grid
# Initialize and fill the classification plane
classification_plane = np.zeros((nb_of_xs, nb_of_xs))
for i in range(nb_of_xs):
for j in range(nb_of_xs):
#classification_plane[i,j] = nn_predict(xx[i,j], yy[i,j])
classification_plane[i,j] = sess.run(y_pred, feed_dict={x: [[ xx[i,j], yy[i,j] ]]} )
classification_plane[i,j] = int(classification_plane[i,j])
# Create a color map to show the classification colors of each grid point
cmap = ListedColormap([
colorConverter.to_rgba('r', alpha=0.30),
colorConverter.to_rgba('b', alpha=0.30)])
# Plot the classification plane with decision boundary and input samples
plt.contourf(xx, yy, classification_plane, cmap=cmap)
plt.show()
xTrain, yTrain = generate(12,num_classes, [[3.0,0],[3.0,3.0],[0,3.0]],True)
yTrain=yTrain%2
colors = ['r' if l == 0.0 else 'b' for l in yTrain[:]]
plt.scatter(xTrain[:,0], xTrain[:,1], c=colors)
plt.xlabel("Scaled age (in yrs)")
plt.ylabel("Tumor size (in cm)")
#plt.show()
yTrain=np.reshape(yTrain,[-1,1])
print ("loss:\n", sess.run(loss, feed_dict={x: xTrain, y: yTrain}))
nb_of_xs = 200
xs1 = np.linspace(-1, 8, num=nb_of_xs)
xs2 = np.linspace(-1, 8, num=nb_of_xs)
xx, yy = np.meshgrid(xs1, xs2) # create the grid
# Initialize and fill the classification plane
classification_plane = np.zeros((nb_of_xs, nb_of_xs))
for i in range(nb_of_xs):
for j in range(nb_of_xs):
#classification_plane[i,j] = nn_predict(xx[i,j], yy[i,j])
classification_plane[i,j] = sess.run(y_pred, feed_dict={x: [[ xx[i,j], yy[i,j] ]]} )
classification_plane[i,j] = int(classification_plane[i,j])
# Create a color map to show the classification colors of each grid point
cmap = ListedColormap([
colorConverter.to_rgba('r', alpha=0.30),
colorConverter.to_rgba('b', alpha=0.30)])
# Plot the classification plane with decision boundary and input samples
plt.contourf(xx, yy, classification_plane, cmap=cmap)
plt.show() 可以看到代码中改动就比较小,其实就是在loss那一行加上L1或L2正则化函数就好了。
b、再说常听到的dropout:dropout的定义就是随机不让某些节点参与学习。因为任何一个模型的准确率不可能总是100%总会又分类错的概率存在,而过拟合却是不允许这个错分类概率存在而把错分类数据或异常数据来当成一种规律学习,所以我们忽略这些节点的数据让那些错分类存在即dropout。 虽然这样子防止过拟合,模型泛化能力增强,但参与学习的节点变少模型训练速度可能变慢。所以在使用过程中需调节到底dropout多少节点,并不是越多越好。
#train
# Ensure we always get the same amount of randomness
np.random.seed(10)
input_dim = 2
num_classes =4
X, Y = generate(120,num_classes, [[3.0,0],[3.0,3.0],[0,3.0]],True)
Y=Y%2
#colors = ['r' if l == 0.0 else 'b' for l in Y[:]]
#plt.scatter(X[:,0], X[:,1], c=colors)
xr=[]
xb=[]
for(l,k) in zip(Y[:],X[:]):
if l == 0.0 :
xr.append([k[0],k[1]])
else:
xb.append([k[0],k[1]])
xr =np.array(xr)
xb =np.array(xb)
plt.scatter(xr[:,0], xr[:,1], c='r',marker='+')
plt.scatter(xb[:,0], xb[:,1], c='b',marker='o')
plt.show()
Y=np.reshape(Y,[-1,1])
learning_rate = 0.01#1e-4
n_input = 2
n_label = 1
n_hidden = 200
x = tf.placeholder(tf.float32, [None,n_input])
y = tf.placeholder(tf.float32, [None, n_label])
weights = {
'h1': tf.Variable(tf.truncated_normal([n_input, n_hidden], stddev=0.1)),
'h2': tf.Variable(tf.random_normal([n_hidden, n_label], stddev=0.1))
}
biases = {
'h1': tf.Variable(tf.zeros([n_hidden])),
'h2': tf.Variable(tf.zeros([n_label]))
}
layer_1 = tf.nn.relu(tf.add(tf.matmul(x, weights['h1']), biases['h1']))
keep_prob = tf.placeholder("float")
layer_1_drop = tf.nn.dropout(layer_1, keep_prob)
#Leaky relus
layer2 =tf.add(tf.matmul(layer_1_drop, weights['h2']),biases['h2'])
y_pred = tf.maximum(layer2,0.01*layer2)
reg = 0.01
#loss=tf.reduce_mean((y_pred-y)**2)+tf.nn.l2_loss(weights['h1'])*reg+tf.nn.l2_loss(weights['h2'])*reg
loss=tf.reduce_mean((y_pred-y)**2)
global_step = tf.Variable(0, trainable=False)
decaylearning_rate = tf.train.exponential_decay(learning_rate, global_step,1000, 0.9)
#train_step = tf.train.AdamOptimizer(learning_rate).minimize(loss)
train_step = tf.train.AdamOptimizer(decaylearning_rate).minimize(loss,global_step=global_step)
#加载
sess = tf.InteractiveSession()
sess.run(tf.global_variables_initializer())
for i in range(20000):
X, Y = generate(1000,num_classes, [[3.0,0],[3.0,3.0],[0,3.0]],True)
Y=Y%2
Y=np.reshape(Y,[-1,1])
_, loss_val = sess.run([train_step, loss], feed_dict={x: X, y: Y,keep_prob:0.6})
if i % 1000 == 0:
print ("Step:", i, "Current loss:", loss_val)
#####predict
#colors = ['r' if l == 0.0 else 'b' for l in Y[:]]
#plt.scatter(X[:,0], X[:,1], c=colors)
xr=[]
xb=[]
for(l,k) in zip(Y[:],X[:]):
if l == 0.0 :
xr.append([k[0],k[1]])
else:
xb.append([k[0],k[1]])
xr =np.array(xr)
xb =np.array(xb)
plt.scatter(xr[:,0], xr[:,1], c='r',marker='+')
plt.scatter(xb[:,0], xb[:,1], c='b',marker='o')
nb_of_xs = 200
xs1 = np.linspace(-1, 8, num=nb_of_xs)
xs2 = np.linspace(-1, 8, num=nb_of_xs)
xx, yy = np.meshgrid(xs1, xs2) # create the grid
# Initialize and fill the classification plane
classification_plane = np.zeros((nb_of_xs, nb_of_xs))
for i in range(nb_of_xs):
for j in range(nb_of_xs):
#classification_plane[i,j] = nn_predict(xx[i,j], yy[i,j])
classification_plane[i,j] = sess.run(y_pred, feed_dict={x: [[ xx[i,j], yy[i,j] ]],keep_prob:1.0} )
classification_plane[i,j] = int(classification_plane[i,j])
# Create a color map to show the classification colors of each grid point
cmap = ListedColormap([
colorConverter.to_rgba('r', alpha=0.30),
colorConverter.to_rgba('b', alpha=0.30)])
# Plot the classification plane with decision boundary and input samples
plt.contourf(xx, yy, classification_plane, cmap=cmap)
plt.show() 这个例子训练还用了模拟退火学习率下降和dropout结合,训练时让0.4的点不激活,测试时必须让所有点100%激活,所以keep_prob=1.0。
在现实应用中,如果使用浅层神经网络,那么每一层一定得很多神经元(带来参数过多)才能有较好的模型;所以实际一般使用深层神经网络,从而每一层参数较少,同时模型又较好。
c、练习题
这三个练习题的代码已给出,让我们自己找出这三个练习题中的错误并改正,我觉得这种方式很好地考察了我们是否真的理解了这章的内容。建议想学的人都自己独立做这几个练习题。 第一个练习题是仿照书上隐藏层+输出层的例子写的,我看到的问题是: 1、这个例子输入4X2后面接着隐藏层2X2,但是偏置却是1,我觉得应该把这个隐藏层的偏置改成2; 2、这个例子的第二层即输出层是2X1偏置是1,第二层加了激活函数,后面又对激活函数的结果继续乘以第二层的权重和偏置,作为真正的输出层,那就变成了三层,但不对,如果是三层那最后一层的权重和偏置不应该是用第二层的。所以它这里到底是用二层还是三层是混乱的; 3、这里使用了自写的交叉熵,但它错把交叉熵和损失函数搞混,其实也是我以前常理不清的,导致看出这一点花了很久时间; 4、还有一点是我找了很久才发现,这里的输出层不应该用tf.nn.softmax,只要是用了这句,不管别的地方怎么改,跑出来始终是[nan,nan,nan,nan],综上,我改成了下面这样:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(55)
np.random.seed(55)
input_data = [[0., 0.], [0., 1.], [1., 0.], [1., 1.]] # XOR input
output_data = [[0.], [1.], [1.], [0.]] # XOR output
n_input = tf.placeholder(tf.float32, shape=[None, 2], name="n_input")
n_output = tf.placeholder(tf.float32, shape=[None, 1], name="n_output")
################
# hidden layer #
################
hidden_nodes =2
W_hidden = tf.Variable(tf.random_normal([2, hidden_nodes]), name="hidden_weights")
# hidden layer's bias neuron
#b_hidden = tf.Variable(0.1, name="hidden_bias")
b_hidden = tf.Variable(tf.zeros([hidden_nodes]), name="hidden_bias")
hidden = tf.nn.relu(tf.matmul(n_input, W_hidden) + b_hidden)
#hidden = tf.sigmoid(tf.matmul(n_input, W_hidden) + b_hidden)
################
# layer2 #
################
#on the book
#W_layer2 = tf.Variable(tf.random_normal([2, hidden_nodes]), name="hidden2_weights")
#b_layer2 = tf.Variable(tf.zeros([hidden_nodes], name="hidden2_bias")
##should be ?
W_hidden2 = tf.Variable(tf.random_normal([hidden_nodes, hidden_nodes]), name="hidden2_weights")
b_hidden2 = tf.Variable(tf.zeros([hidden_nodes]), name="hidden2_bias")
layer_layer2=tf.matmul(hidden, W_hidden2)+b_hidden2
#layer_2 = tf.nn.relu(layer_layer2)
layer_2 = tf.sigmoid(layer_layer2)
################
# output layer #
################
W_output = tf.Variable(tf.random_normal([hidden_nodes, 1]), name="output_weights")
b_output = tf.Variable(0.1, name="output_bias")
#lastnode=1
#b_output = tf.Variable(tf.zeros([lastnode]), name="output_bias")
output = tf.matmul(layer_2, W_output)+b_output
#output = tf.nn.softmax(y)
#交叉熵 on the book
# =============================================================================
# loss = -(n_output * tf.log(output) + (1 - n_output) * tf.log(1 - output))
# optimizer = tf.train.GradientDescentOptimizer(0.01)
# train = optimizer.minimize(loss) # let the optimizer train
# =============================================================================
crossentropy = -(n_output * tf.log(output) + (1 - n_output) * tf.log(1 - output))
loss=tf.reduce_mean(crossentropy)
#optimizer = tf.train.AdamOptimizer(0.01)
optimizer = tf.train.GradientDescentOptimizer(0.01)
train = optimizer.minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(4001):
sess.run(train,feed_dict={n_input: input_data, n_output: output_data} )
#计算预测值
print(sess.run(output,feed_dict={n_input: input_data}))
#查看隐藏层的输出
print(sess.run(hidden,feed_dict={n_input: input_data}))输出是这样:
[[0.35568202]
[3.599916 ]
[0.35568202]
[0.35602963]]
[[0.0000000e+00 0.0000000e+00]
[1.7047949e+00 0.0000000e+00]
[0.0000000e+00 0.0000000e+00]
[1.8998398e-04 0.0000000e+00]]真的建议大家自己改错误,真的会发现其实自己根本还没理解。应该把前几章细看理解的。我也不知道这个算不算梯度消失啊,之前梯度消失那里没看懂的?所以我也不知道是否改正确了,或者说成功训练出了一个模型?虽然第三个输出是错的。应该还可以继续改正得精度更好。后来我又试了错误代码中的创建sess后的内容稍微修改下:
plotdata = { "epoch":[], "loss":[] }
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(0, 11001):
cvalues = sess.run([train, loss],feed_dict={n_input: input_data, n_output: output_data})
if epoch % 200 == 0:
print("")
print("step: {:>3}".format(epoch))
print("loss: {}".format(cvalues[1]))
plotdata["epoch"].append(epoch)
epochloss = sess.run(loss, feed_dict={n_input: input_data, n_output: output_data})
plotdata["loss"].append(epochloss)
# print("b_hidden: {}".format(cvalues[3]))
# print("W_hidden: {}".format(cvalues[2]))
# print("W_output: {}".format(cvalues[4]))
print(sess.run(output,feed_dict={n_input: input_data}))
plt.figure(1)
plt.plot(plotdata["epoch"], plotdata["loss"], 'b--')
plt.xlabel('epoch number')
plt.ylabel('Loss')
plt.title('epoch vs. Training loss')
plt.show()结果:
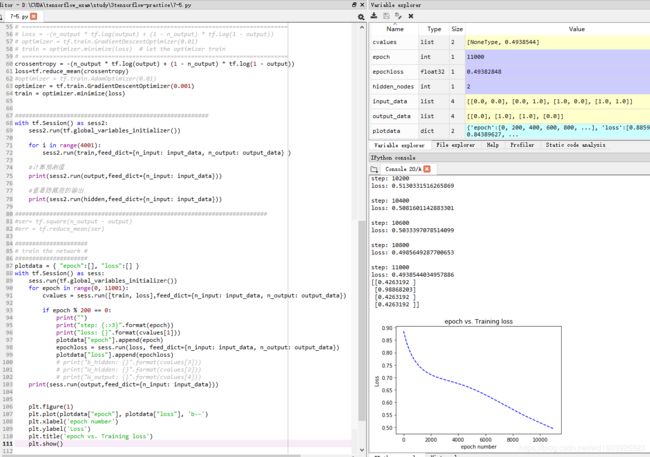
由图可知,并没有收敛,如果我再加大epoch,那么会出现loss=nan情况,是不是这个就意味着梯度消失?所以这个模型还要继续修改才是。
第二个练习题:输出层换成了tanh,其它与第一个例子一样。我改成了下面这样:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(55)
np.random.seed(55)
input_data = [[0., 0.], [0., 1.], [1., 0.], [1., 1.]] # XOR input
output_data = [[0.], [1.], [1.], [0.]] # XOR output
hidden_nodes =2
n_input = tf.placeholder(tf.float32, shape=[None, 2], name="n_input")
n_output = tf.placeholder(tf.float32, shape=[None, 1], name="n_output")
################
# hidden layer #
################
W_hidden = tf.Variable(tf.random_normal([2, hidden_nodes]), name="hidden_weights")
# hidden layer's bias neuron
b_hidden = tf.Variable(tf.zeros([hidden_nodes]), name="hidden_bias")
#hidden = tf.sigmoid(tf.matmul(n_input, W_hidden) + b_hidden)
hidden = tf.nn.relu(tf.matmul(n_input, W_hidden) + b_hidden)
################
# output layer #
################
W_output = tf.Variable(tf.random_normal([hidden_nodes, 1]), name="output_weights")
b_output = tf.Variable(0.1, name="output_bias")
output = tf.nn.tanh(tf.matmul(hidden, W_output)+b_output)
#softmax
#y = tf.matmul(hidden, W_output)+b_output
#output = tf.nn.softmax(tf.matmul(hidden, W_output)+b_output)
#交叉熵
crossentropy = -(n_output * tf.log(output) + (1 - n_output) * tf.log(1 - output))
loss=tf.reduce_mean(crossentropy)
optimizer = tf.train.AdamOptimizer(0.001)
train = optimizer.minimize(loss) # let the optimizer train
plotdata = { "epoch":[], "loss":[] }
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(0, 2001):
cvalues = sess.run([train, loss],feed_dict={n_input: input_data, n_output: output_data})
if epoch % 200 == 0:
print("")
print("step: {:>3}".format(epoch))
print("loss: {}".format(cvalues[1]))
plotdata["epoch"].append(epoch)
epochloss = sess.run(loss, feed_dict={n_input: input_data, n_output: output_data})
plotdata["loss"].append(epochloss)
# print("b_hidden: {}".format(cvalues[3]))
# print("W_hidden: {}".format(cvalues[2]))
# print("W_output: {}".format(cvalues[4]))
print(sess.run(output,feed_dict={n_input: input_data}))
plt.figure(1)
plt.plot(plotdata["epoch"], plotdata["loss"], 'b--')
plt.xlabel('epoch number')
plt.ylabel('Loss')
plt.title('epoch vs. Training loss')
plt.show()
由图可知,好像收敛太快了啊?到500次就收敛了,也还可以继续优化。
第三个练习题:就是交叉熵那里换了自写的交叉熵,然后loss没有与交叉熵搞混,其他与前两个差不多:
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
tf.set_random_seed(55)
np.random.seed(55)
input_data = [[0., 0.], [0., 1.], [1., 0.], [1., 1.]] # XOR input
output_data = [[0.], [1.], [1.], [0.]] # XOR output
hidden_nodes =2
n_input = tf.placeholder(tf.float32, shape=[None, 2], name="n_input")
n_output = tf.placeholder(tf.float32, shape=[None, 1], name="n_output")
W_hidden = tf.Variable(tf.random_normal([2, hidden_nodes]), name="hidden_weights")
b_hidden = tf.Variable(tf.zeros([hidden_nodes]), name="hidden_bias")
hidden = tf.sigmoid(tf.matmul(n_input, W_hidden) + b_hidden)
################
# output layer #
################
W_output = tf.Variable(tf.random_normal([hidden_nodes, 1]), name="output_weights") # output layer's weight matrix
b_output = tf.Variable(0.1, name="output_bias")
output = tf.nn.tanh(tf.matmul(hidden, W_output)+b_output)
cross_entropy = -tf.reduce_sum(n_output * tf.log(output))#
loss = tf.reduce_mean(cross_entropy) # mean the cross_entropy
optimizer = tf.train.AdamOptimizer(0.001)
train = optimizer.minimize(loss) # let the optimizer train
#####################
# train the network #
#####################
plotdata = { "epoch":[], "loss":[] }
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for epoch in range(0, 2001):
cvalues = sess.run([train, loss],feed_dict={n_input: input_data, n_output: output_data})
if epoch % 200 == 0:
print("")
print("step: {:>3}".format(epoch))
print("loss: {}".format(cvalues[1]))
plotdata["epoch"].append(epoch)
epochloss = sess.run(loss, feed_dict={n_input: input_data, n_output: output_data})
plotdata["loss"].append(epochloss)
# print("b_hidden: {}".format(cvalues[3]))
# print("W_hidden: {}".format(cvalues[2]))
# print("W_output: {}".format(cvalues[4]))
print(sess.run(output,feed_dict={n_input: input_data}))
plt.figure(1)
plt.plot(plotdata["epoch"], plotdata["loss"], 'b--')
plt.xlabel('epoch number')
plt.ylabel('Loss')
plt.title('epoch vs. Training loss')
plt.show()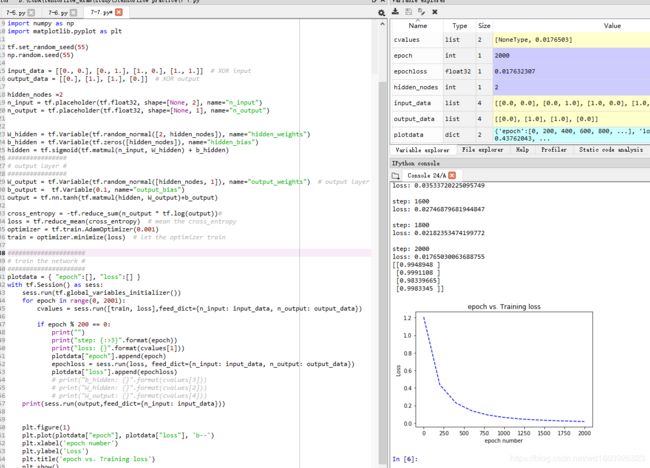
收敛得很快,然后也比较平滑,也没有出现梯度消失,但是预测结果不好?还是要继续优化。。。这三个例子除了告诉我指出的那些问题,是不是还要告诉我们激活函数、交叉熵函数的搭配与训练比较好的模型的关系??
6、第八章
实在忍不住再说一遍,感觉这本书很好,很适合我这样的傻子。这一章开始介绍卷积神经网络,全连接网络有很大局限性(参数过多,对高维数据不友好),而卷积神经网络参数是共享的所以参数少。卷积后的结果不一定在0~255之间,所以常常需要归一化数据后乘以255.。卷积一次后的图片叫feature map。卷积神经网络是复杂的,因为常常一个卷积层有多个filters,会得到多个feature maps。
1、一个卷积神经网络包括5大部分:输入、若干卷积层+池化层的结构、全局平均池化层、输出层。 输入:一个像素代表一个特征节点;池化层主要是对卷积结果降维;全局平均池化层取代了以前的全连接层,建议以后这个部分直接使用效率较高的全局平均池化层;输出层一般几个类就设置几个输出节点,每一个输出表示当前样本属于该类型的概率。
a、卷积层:卷积主要有三种-----窄卷积valid(步长可变,卷积后图片变小)、同卷积same(步长=1,常伴随padding,卷积后尺寸相同)、全卷积full(反卷积,很少用于卷积神经网络中,步长=1,有点像把原图和卷积核的角色互换进行卷积一样,卷积后结果尺寸比原图大) Tensorflow里已经封装好了卷积操作的API是:tf.nn.conv2d(input,filter,strides,padding);这里的padding非常需要搞清楚:padding=valid,那么输出尺寸output_size=(input_size-filter_size+1)/strides_size结果若是小数向上取整;padding=same,那么输出尺寸与卷积核尺寸无关,output_size=(input_size)/strides_size,结果若为小数,向上取整。 图片的尺寸定义是按[batch,input_height,input_width,input_channels],而卷积核是按照[filter_height,filter_width,input_channels,filter_numbers]这样来定义,filter_numbers即表示生成几个features_map。
import tensorflow as tf
# [batch, in_height, in_width, in_channels] [训练时一个batch的图片数量, 图片高度, 图片宽度, 图像通道数]
input = tf.Variable(tf.constant(1.0,shape = [1, 5, 5, 1]))
input2 = tf.Variable(tf.constant(1.0,shape = [1, 5, 5, 2]))
input3 = tf.Variable(tf.constant(1.0,shape = [1, 4, 4, 1]))
# [filter_height, filter_width, in_channels, out_channels] [卷积核的高度,卷积核的宽度,图像通道数,卷积核个数]
filter1 = tf.Variable(tf.constant([-1.0,0,0,-1],shape = [2, 2, 1, 1]))
filter2 = tf.Variable(tf.constant([-1.0,0,0,-1,-1.0,0,0,-1],shape = [2, 2, 1, 2]))
filter3 = tf.Variable(tf.constant([-1.0,0,0,-1,-1.0,0,0,-1,-1.0,0,0,-1],shape = [2, 2, 1, 3]))
filter4 = tf.Variable(tf.constant([-1.0,0,0,-1,
-1.0,0,0,-1,
-1.0,0,0,-1,
-1.0,0,0,-1],shape = [2, 2, 2, 2]))
filter5 = tf.Variable(tf.constant([-1.0,0,0,-1,-1.0,0,0,-1],shape = [2, 2, 2, 1]))
# padding的值为‘VALID’,表示边缘不填充, 当其为‘SAME’时,表示填充到卷积核可以到达图像边缘
op1 = tf.nn.conv2d(input, filter1, strides=[1, 2, 2, 1], padding='SAME') #1个通道输入,生成1个feature ma
op2 = tf.nn.conv2d(input, filter2, strides=[1, 2, 2, 1], padding='SAME') #1个通道输入,生成2个feature map
op3 = tf.nn.conv2d(input, filter3, strides=[1, 2, 2, 1], padding='SAME') #1个通道输入,生成3个feature map
op4 = tf.nn.conv2d(input2, filter4, strides=[1, 2, 2, 1], padding='SAME') # 2个通道输入,生成2个feature
op5 = tf.nn.conv2d(input2, filter5, strides=[1, 2, 2, 1], padding='SAME') # 2个通道输入,生成一个feature map
vop1 = tf.nn.conv2d(input, filter1, strides=[1, 2, 2, 1], padding='VALID') # 5*5 对于pading不同而不同
op6 = tf.nn.conv2d(input3, filter1, strides=[1, 2, 2, 1], padding='SAME')
vop6 = tf.nn.conv2d(input3, filter1, strides=[1, 2, 2, 1], padding='VALID') #4*4与pading无关
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
print("op1:\n",sess.run([op1,filter1]))#1-1 后面补0
print("------------------")
print("op2:\n",sess.run([op2,filter2])) #1-2多卷积核 按列取
print("op3:\n",sess.run([op3,filter3])) #1-3
print("------------------")
print("op4:\n",sess.run([op4,filter4]))#2-2 通道叠加
print("op5:\n",sess.run([op5,filter5]))#2-1
print("------------------")
print("op1:\n",sess.run([op1,filter1]))#1-1
print("vop1:\n",sess.run([vop1,filter1]))
print("op6:\n",sess.run([op6,filter1]))
print("vop6:\n",sess.run([vop6,filter1]))
print("shape op1:",op1)
print("shape op2:",op2)
print("shape op3:",op3)
print("shape op4:",op4)
print("shape op5:",op5)
print("shape op6:",op6)
print("shape vop1:",vop1)
print("shape vop6:",vop6)shape op1: Tensor("Conv2D:0", shape=(1, 3, 3, 1), dtype=float32)
shape op2: Tensor("Conv2D_1:0", shape=(1, 3, 3, 2), dtype=float32)
shape op3: Tensor("Conv2D_2:0", shape=(1, 3, 3, 3), dtype=float32)
shape op4: Tensor("Conv2D_3:0", shape=(1, 3, 3, 2), dtype=float32)
shape op5: Tensor("Conv2D_4:0", shape=(1, 3, 3, 1), dtype=float32)
shape op6: Tensor("Conv2D_6:0", shape=(1, 2, 2, 1), dtype=float32)
shape vop1: Tensor("Conv2D_5:0", shape=(1, 2, 2, 1), dtype=float32)
shape vop6: Tensor("Conv2D_7:0", shape=(1, 2, 2, 1), dtype=float32)这个例子与我草稿纸上计算结果几乎一样,但对于input2的计算,每个通道都用那个filter4,我以为应该生成4个featuresmap,但结果只生成了2个featuresmap。原来是卷积核对多通道输入的卷积处理时多通道的结果叠加。所以其实输入原图的通道即第四维和对应filter的第三维是一定一样的,都不用看,与结果的第思维一定是一样的。结果的第一维与输入图的第一维一样是batch。这样想就简单了。 下面利用卷积操作实现sobel边缘提取:我的图片是4通道
myimg = mpimg.imread('1.png') # 读取和代码处于同一目录下的图片
plt.imshow(myimg) # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()
print(myimg.shape)
full=np.reshape(myimg,[1,925,1234,4])
inputfull = tf.Variable(tf.constant(1.0,shape = [1,925,1234,4]))
filter = tf.Variable(tf.constant([[-1.0,-1.0,-1.0,-1.0], [0,0,0,0], [1.0,1.0,1.0,1.0],
[-2.0,-2.0,-2.0,-2.0], [0,0,0,0], [2.0,2.0,2.0,2.0],
[-1.0,-1.0,-1.0,-1.0], [0,0,0,0], [1.0,1.0,1.0,1.0]],shape = [3, 4, 4, 1]))
op = tf.nn.conv2d(inputfull, filter, strides=[1, 1, 1, 1], padding='SAME') #3个通道输入,生成1个feature ma
#让卷积后的数据在0~255之间
o=tf.cast( ((op-tf.reduce_min(op))/(tf.reduce_max(op)-tf.reduce_min(op)) ) *255 ,tf.uint8)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer() )
t,f=sess.run([o,filter],feed_dict={ inputfull:full})
#print(f)
t=np.reshape(t,[925,1234])
plt.imshow(t,cmap='Greys_r') # 显示图片
plt.axis('off') # 不显示坐标轴
plt.show()b、池化:池化的作用主要是降维。主要有均值池化和最大值池化。API是tf.nn.avg或max_pool(input,pool_size,strides,padding),input一般是卷积后的结果featuremap[batch,height,width,channels],poolsize是池化窗口大小,与input类似,一般是[1,height,width,1];strides也与input类似[1,stride,stride,1]一般来说步长常常设置为与poolsize的尺寸一样!!!这个经常看到;padding=valid与上部分内容卷积的valid一样计算;padding=same也是与卷积的same一样计算。返回结果依旧是[batch,height,width,channel]的tensor。
img=tf.constant([
[[0.0,4.0],[0.0,4.0],[0.0,4.0],[0.0,4.0]],
[[1.0,5.0],[1.0,5.0],[1.0,5.0],[1.0,5.0]],
[[2.0,6.0],[2.0,6.0],[2.0,6.0],[2.0,6.0]],
[[3.0,7.0],[3.0,7.0], [3.0,7.0],[3.0,7.0]]
])
img=tf.reshape(img,[1,4,4,2])
pooling=tf.nn.max_pool(img,[1,2,2,1],[1,2,2,1],padding='VALID')
pooling1=tf.nn.max_pool(img,[1,2,2,1],[1,1,1,1],padding='VALID')
pooling2=tf.nn.avg_pool(img,[1,4,4,1],[1,1,1,1],padding='SAME')
pooling3=tf.nn.avg_pool(img,[1,4,4,1],[1,4,4,1],padding='SAME')
nt_hpool2_flat = tf.reshape(tf.transpose(img), [-1, 16])
pooling4=tf.reduce_mean(nt_hpool2_flat,1) #1对行求均值(1表示轴是列) 0 对列求均值
with tf.Session() as sess:
print("image:")
image=sess.run(img)
print (image)
print("valid:",pooling)
print("valid:",pooling1)
print("same:",pooling2)
print("same:",pooling3)
print("same:",pooling4)和我计算的结果一样。因为stride那里[1,X,X,1],所以池化不会改变输入的通道。之前说到代替以前大名鼎鼎的全连接层的是效率更高的全局池化层,其实就是pooling3这样,使用一个与输入同样尺寸的池化窗进行池化,用于表达图像通过卷积网络处理后的最终的特征。
2、cifar10 例子
其实这个例子我很想跟着书上实践,但发现github上代码可能有更新,跟这本书上不一致。所以这部分只能暂时光说不练了。文中再一次提到了图像标准化,可以使梯度下降算法收敛更快。然后还提到了大量样本坐训练时建议使用queue来读取大数据。还提到了图像多样性扩充如随机裁剪、随机左右翻转、随机亮度变化、随机对比度变化、再就是刚刚说的图像标准化。
class DataPreprocessor(object):
"""Applies transformations to dataset record."""
def __init__(self, distords):
self._distords = distords
def __call__(self, record):
"""Process img for training or eval."""
img = record['image']
img = tf.cast(img, tf.float32)
if self._distords: # training
# Randomly crop a [height, width] section of the image.
img = tf.random_crop(img, [IMAGE_SIZE, IMAGE_SIZE, 3])
# Randomly flip the image horizontally.
img = tf.image.random_flip_left_right(img)
# Because these operations are not commutative, consider randomizing
# the order their operation.
# NOTE: since per_image_standardization zeros the mean and makes
# the stddev unit, this likely has no effect see tensorflow#1458.
img = tf.image.random_brightness(img, max_delta=63)
img = tf.image.random_contrast(img, lower=0.2, upper=1.8)
else: # Image processing for evaluation.
# Crop the central [height, width] of the image.
img = tf.image.resize_image_with_crop_or_pad(img, IMAGE_SIZE, IMAGE_SIZE)
# Subtract off the mean and divide by the variance of the pixels.
img = tf.image.per_image_standardization(img)
return dict(input=img, target=record['label'])a、queue队列机制
queue可以通过多线程将读取数据与计算数据分开,因为读取海量数据时需要时间将其读到内存,所以一边读取数据一边计算训练是一个好主意。
启动线程,向队列里传入数据:
#sess = tf.InteractiveSession()
#tf.global_variables_initializer().run()
#tf.train.start_queue_runners()感觉好像一个session就是一个线程是吗?所以后续如果用with...as这种方式创建线程,一出with就自动关闭了这个线程,那还谈什么一个线程读数据一个线程计算的事儿呢。所以感觉使用queue时还是就像上面代码这样创建session,而尽量别用with...as的方式:
#with tf.Session() as sess:
# tf.global_variables_initializer().run()
# tf.train.start_queue_runners()
# image_batch, label_batch = sess.run([images_test, labels_test])
# print("__\n",image_batch[0])
#
# print("__\n",label_batch[0])
# pylab.imshow(image_batch[0])
# pylab.show()如果不用tf.InteractiveSession(),第二个方法呢就是使用tf.Session()来创建sess,但这种方式需要每次使用session时都指定是哪个session,而且是严重依赖进程结束才会销毁sess。而无法自动关闭,除非使用协调器tf.train.Coordinator,完成线程间的同步。
6