祝自己生日快乐 | 利用Python和R分析一年写作
想不清自己有多久没有过生日了,即便是18岁那年的生日,也是上完课照常回去。或许是我的日子过得过于浑浑噩噩,没有什么可以庆祝,或许我认为过生日是过于矫情的一种行为吧。
但是反刻奇也是一种刻奇,没有必要坚持不过,显得自己标新立异。而这一年或许是我生长最多的一年,或许是我高中毕业后打字最多的一年了,记录了大量文字在我的简书,公众号,为知笔记,GitHub Page。
时间匆忙,所以只能对我简书发布的文章做了简单的数据分析。
数据获取
我用Python从简书上爬取了我所有文章的发布时间,题目名和连接,把他们存放在了MySQL里。
- 首先,定义数据库结构
# 创建数据库
mysqladmin.exe -u root -p create jianshu
# 创建数据表
use jianshu;
CREATE TABLE `master` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`time` varchar(255) COLLATE utf8_bin NOT NULL,
`url` varchar(255) COLLATE utf8_bin NOT NULL,
`title` varchar(255) COLLATE utf8_bin NOT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 COLLATE=utf8_bin
AUTO_INCREMENT=1 ;
- 其次,写爬虫爬取数据
import time
import re
import requests
from random import randint
def data_parse(url, headers=None ):
response = requests.get(url)
pattern = re.compile(r'.*?(.*?)',flags=re.S)
results = re.findall(pattern, response.text)
time.sleep(randint(1,5))
for res in results:
names = ["time","url","title"]
info_dict = dict(list(zip(names,res)))
yield info_dict
为了不给他们服务器太大压力,爬取之间有1到3秒的延迟。利用正则提取目标区域
- 最后运行
for i in range(0,16):
url = 'http://www.jianshu.com/u/9ea40b5f607a?order_by=shared_at&page=' + str(i)
dicts = data_parse(url)
save_data(db="jianshu",password="********",dicts=dicts)
简书采用的是瀑布流方式展示信息,所以需要查看页面了解规律。
简单数据分析
从数据库加载数据
require(RMySQL)
con <- dbConnect(RMySQL::MySQL(),
host="localhost",
user="root",
port=3306,
password="********",
dbname="jianshu")
tables <- dbReadTable(con, 'master')
Encoding(tables$title) <- "UTF-8"
注意: 要使用Encoding处理编码问题
分析文章时间分布
简单看下从去年5月份到8月份,我的写作分布
require(tidyverse)
time_matrix <- str_match(tables$time, '(\\d+-\\d+-\\d+)T(\\d{2}):(\\d{2})')
time_matrix <- as.tibble(time_matrix)
colnames(time_matrix) <- c('date','ymd','hour','minutes')
time_matrix$ymd <- as.Date(time_matrix$ymd)
month_df <- time_matrix %>% mutate(ym = str_c(str_sub(ymd, 1,7),'-01')) %>% group_by(ym) %>% summarise(articles=n()) %>% ungroup() %>% mutate(ym=as.Date(ym, "%Y-%m-%d"))
p1 <- ggplot(month_df, aes(x=ym,y=articles)) + geom_bar(stat = "identity")
# 添加数据标签
p1 + geom_text(aes(label=articles), vjust=1.5, colour="white")
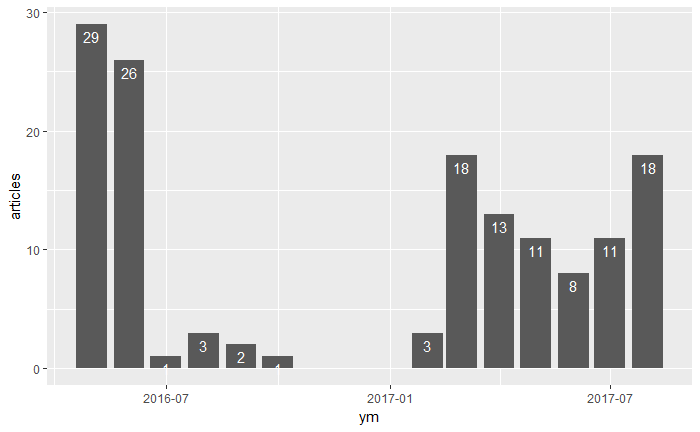
2016年5月11日,我刚开通简书,而那个月文章发布不可思议的多,一共发了29篇,6月也有26篇。然后后面基本就没写了,原因就是我在家里学车,荒废人生中。从今年2月份开始,我重新建起了简书,后面基本上保持每个月10多篇的产出。
然后,我们还可以看下每天的时间段分布:
day_df <- time_matrix %>% group_by(hour) %>% summarise(hours=n())
ggplot(day_df, aes(x=hour, y=hours)) + geom_bar(stat="identity") + geom_text(aes(label=hours), vjust=-1.5) + ylim(0,20)
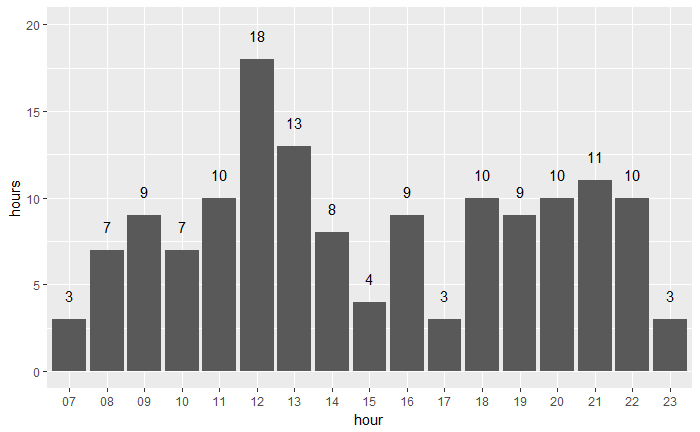
从早上7点到晚上23点基本都有文章发布,说明了我没事就发,写好就发的特点
标题分析
本来我是想对我的文章内容进行分析的,但是时间有限,所以退而求其次,只能对标题进行分析了。
require(jiebaR)
require(wordcloud2)
cutter <- worker()
words <- cutter <= tables$title
word_tb <- filter_segment(words, c("的","组","更","的","在","和"))
word_tb <- table(word_tb)
wordcloud2(word_tb, size=0.5, shape='cardioid')

Python, 爬虫, 数据分析,R 这些其实是贯穿我这一年的关键词。经过这一年的时间,至少我能用这些技能做一篇文章的分析了。
最后说几句
其实也没有啥好说的,希望接下来一年自己能有更多的进步,给自己提供更多的数据进行分析,有更多的信息能够挖掘。