jaeger实现了opentracing的规范,对Tracer与Span等接口写了自己的实现。根据opentracing的规范,每个服务建议只有一个Tracer,Tracer创建方法由实现类决定。
我们按照以下顺序来整理思路:
- 构建
Tracer - 构建
Span并启动、管理 - 获取
Span添加信息 - 结束并发送
Span
构建Tracer
jaeger采用builder模式来构建Tracer,较为简便的构建方式为:
Tracer tracer = new Tracer.Builder("myServiceName").build()
这时,仅需要传入服务名即可,其他trace中的参数在build()方法中可以看到有默认实现。
下面是上述调用的详细描述
Builder("myServiceName")方法
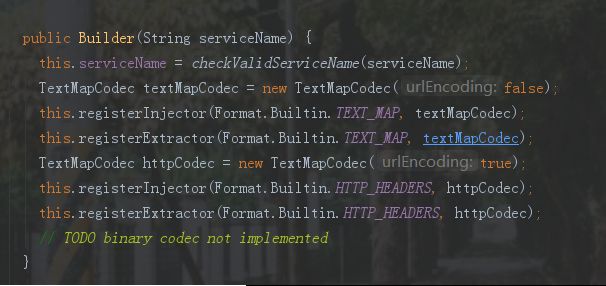
该方法除了对serviceName属性赋值外,还对属性registry进行初始化,如图中的this.registerInjector(Format.Builtin.TEXT_MAP, textMapCodec);
this.registerExtractor(Format.Builtin.TEXT_MAP, textMapCodec);
两个方法,对使用TEXT_MAP方式来injector与extractor数据的类进行注册,在之后需要将traceId,spanId等信息在服务间传递时,可以从注册中心取出该类进行injector与extractor操作,opentracing强制要求实现的除了TEXT_MAP的方式还有binary方式,在jaeger中使用的是opentracing中的默认实现,没有自己实现。
build()方法
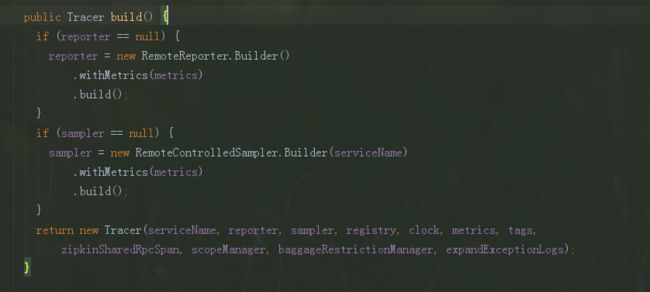
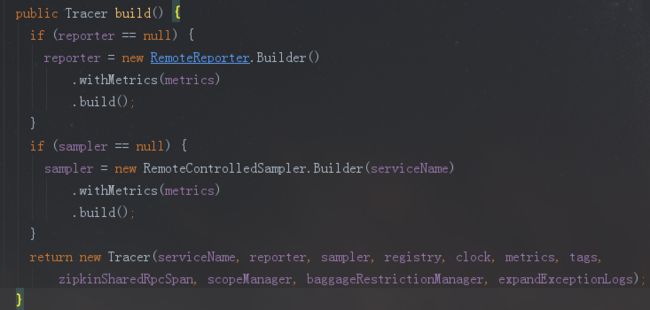
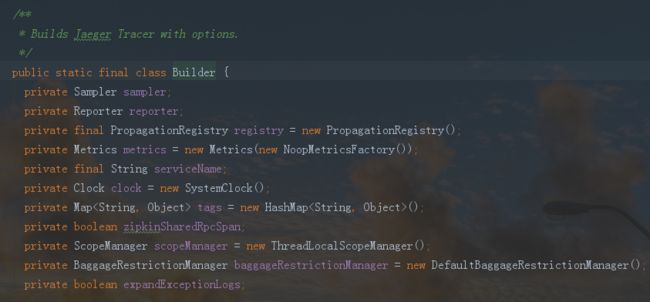
builde()方法最终完成了Tracer对象的构造。这里默认使用RemoteReporter来report Span到agent,采样默认使用RemoteControlledSampler。而这里共同使用的metrics是在Builder内部类中的有默认值的成员变量metrics,如下图:
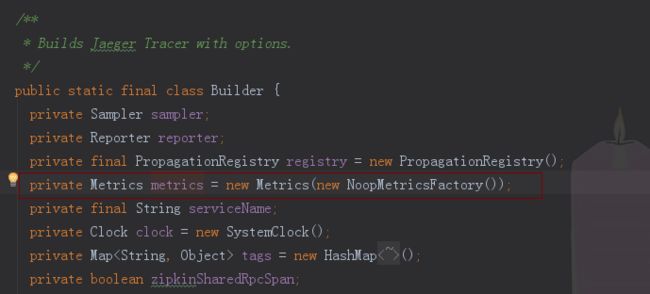
这里我们依次关注下RemoteReporter与RemoteControlledSampler。
RemoteReporter
reporter = new RemoteReporter.Builder() .withMetrics(metrics) .build();
其中build()方法如下
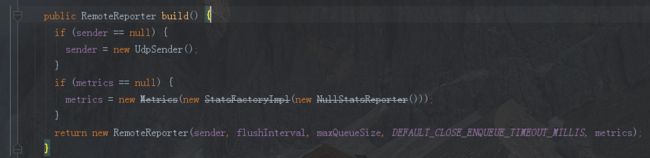
由于调用了withMetrics(metrics)方法,因此上图中的if(metrics == null)分支不会进入,而我们的关注重点在于RemoteReporter在Tracer中的默认实现是使用的UdpSender来发送span到agent,因此如果我们有需要可以使用RemoteReporter.Builder中的withSender(Sender sender)替换为我们想要的发送方式。
这里和brave类似,jaeger自己写了个了Report接口,定义了两个方法如下:
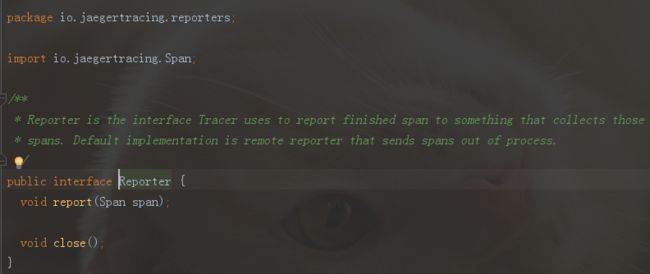
下面是jaeger中实现的该Report接口的实现类
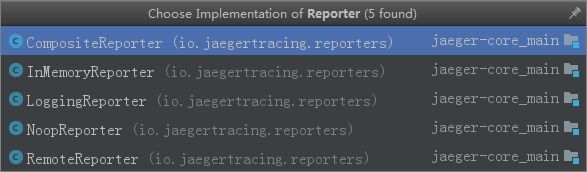
这里做一下简要介绍,总的来说只有RemoteReporter这个实现类还有点技术含量,另外的四个实现类里,
-
CompositeReporter顾名思义就是将各个reporter组合起来,内部有一个list,它所实现的接口的report(Span span)方法也只是把list中的所有reporter依次调用report(Span span)方法而已。 -
InMemoryReporter类是将Span存到内存中,该类含有一个list用于存储span,该类中的report方法即为将span通过add方法添加到list中,通过getSpans()方法获取到list,同时有clear()方法清除list数据。 -
LoggingReporter类作用是将span作为日志内容打印出来,其report方法即为log.info()打印span的内容。 -
NoopReporter是一个实现了Reporter接口但是实现方法为空的一个类,表示使用该类report span将毫无影响。
RemoteControlledSampler
sampler = new RemoteControlledSampler.Builder(serviceName) .withMetrics(metrics) .build();
同样的我们再看一看Tracer中采样率控制类的默认实现。
build()方法如下:
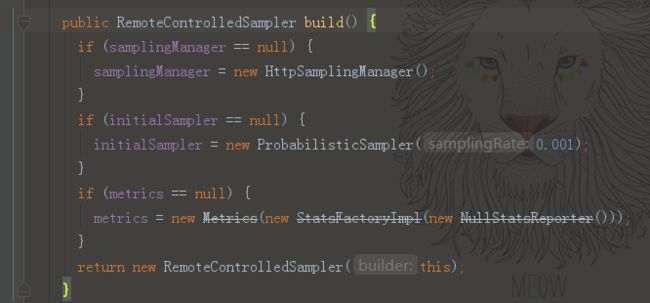
如同上面的RemoteReporter一样,分支if(metrics == null)不会执行,而上面的两个if分支都会执行。首先先介绍initialSampler属性,我们看到默认的实现中给initialSampler(初始化采样率)设置采样率为0.001,而为什么叫他initialSampler(初始化采样率)呢?因为该类叫做RemoteControlledSampler也就是可以动态的调整采样策略,包括单纯的采样率的改变以及基于spanName的采样策略,这适用于同一个服务中不同的方法吞吐量不同,可以通过基于spanName的采样策略来实现更细粒度的采样。
同样的,jaeger自己定义了一个Sampler接口来完成采样的工作,该接口如下:
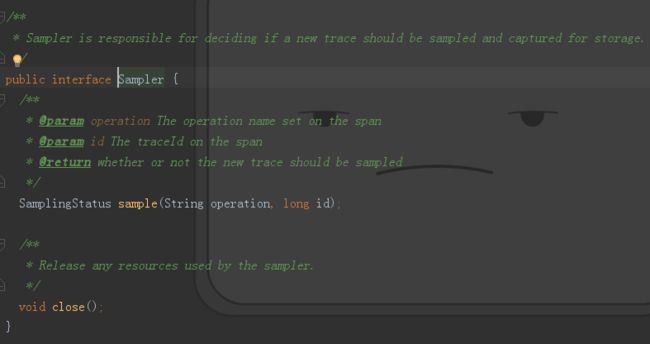
核心方法 sample(String operation, long id)可以根据 operation也就是spanName与 id也就是traceId来判断是否对该条trace采样。
该接口的实现类有:
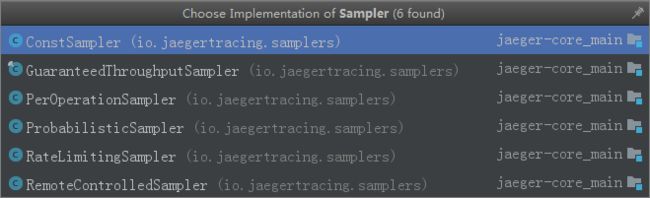
下面做简要介绍
-
ConstSampler类,顾名思义,一个固定值的采样,并非固定数值而是指要么都采样要么都不采样。 -
RateLimitingSampler类,控制每秒流量的一个采样类,每次调用sample(String operation, long id)方法都会根据上次调用与这次调用的时间差乘以我们设置的maxTracesPerSecond参数并累加后与1比较,超过1就返回true否则返回false继续累加。该类不会区分spanName。之后的文档会详细介绍原理。 -
ProbabilisticSampler类是一个按照固定概率采样的类,根据traceId来判断是否对该trace采样。 -
GraranteedThroughtputSampler该类用到了RateLimitingSampler与ProbabilisticSampler,采样策略为RateLimitingSampler与ProbabilisticSampler任意一个同意采样即可采样,若两个类都返回true则ProbabilisticSampler有更高的优先级。 -
PerOperationSampler类用到了GraranteedThroughtputSampler,该类实现了根据spanName来控制不同的spanName采用不同的GraranteedThroughtputSampler来采样。 -
RemoteControlledSampler没有更高级的实现,只是开启一个守护线程定时从服务端获得响应,然后决定使用RateLimitingSampler,ProbabilisticSampler与PerOperationSampler中的哪一个。
至此,Tracer的初始化完成。
其中我们介绍了serviceName,reporter,sampler,registry,metrics的初始化,其他Tracer构造函数中的参数的初始值见下图
小结:通过上述内容,我们可以了解并认识到Tracer类的重要性,从其构造函数也可见一斑。jaeger中的Tracer控制了一个完整的服务的追踪,包括注册服务名(serviceName),发送span(reporter),采样(sampler),对span的序列化与反序列化以及传输(registry的injector,extractor),统计追踪系统的信息(metrics,如发送span成功数量等)这些我们讨论到的如何初始化的属性以及构造函数中其他参数。因此opentracing建议每个服务使用一个Tracer,除此之外Tracer还担负构造span,获取当前span以及获取scopeManager的功能。通过opentracing的规范亦可以看出,opentracing对Tracer的功能描述为:Tracer is a simple, thin interface for Span creation and propagation across arbitrary transports. 而jaeger只是在其基础上增加了其他功能。在jaeger中还有使用
Configuration类来构建Tracer的方式,这里我们暂不介绍。
构建Span并启动、管理
构建Span是一件很复杂的事情,并非构造Span本身很困难让人难以理解,而是为了更好的控制构造出来并启动的span,需要考虑到多种情况,这使构造并启动Span这件事情在形式上解释起来有点复杂。下面会根据opentracing对构造并启动span的介绍以及jaeger对opentracing的代码实现来尽量解释清楚。
简单的构造Span对象是一件很简单的事情,通过opentracing对Tracer接口的规定可知Span是由Tracer负责构造的,如下:
Span span = tracer.buildSpan("someWork").start();
我们“启动”了一个Span(实际上只是构造了该对象而已),但是这样的一个span并不能很好的满足我们的要求,试想一下,如果我们只是简单的构造一个Span对象出来,对当前方法A进行记录,若方法A中调用了方法B,我们在方法B中同样构造了Span,那如何保证将B的span的parent设置为A的span呢?最直观的办法就是在A方法调用B方法时,把A方法的span作为参数传入B方法中,显然这样是非常不合理的,如果在多线程环境下问题就会更复杂。
因此需要有一个类来管理span,使得编写方法的人无需为span预留参数,又可以随时获取到当前线程中的 活动的 span,以便在新构造Span对象时可以获取到当前中的 活动的 span作为新span的parent。
在opentracing中提供了这样的接口规范:ScopeManager与Scope
-
ScopeManagerThe ScopeManager interface abstracts both the activation of Span instances via activate(Span, boolean) and access to an active Span/Scope via active(). 该接口提供了将给定的span变为 活动的 span的功能以及获取当前 活动的 span/scope。 -
ScopeA Scope formalizes the activation and deactivation of a Span, usually from a CPU standpoint.
Many times a Span will be extant (in that Span.finish() has not been called) despite being in a non-runnable state from a CPU/scheduler standpoint. For instance, a Span representing the client side of an RPC will be unfinished but blocked on IO while the RPC is still outstanding. A Scope defines when a given Span is scheduled and on the path.
我的理解是:在多线程环境下ScopeManager管理着各个线程的Scope,而每个线程中的Scope管理着该线程中的Span。这样当某个线程需要获取其线程中当前 活动的 span时,可以通过ScopeManager找到对应该线程的Scope,并从Scope中取出该线程 活动的 span。
在 java 中是怎么实现的呢?与brave类似,opentracing使用的是ThreadLocal,而jaeger直接使用了opentracing提供的ThreadLocalScopeManager并没有自己重写一个实现类。而opentracing对ScopeManager接口写了如下几个实现:

第一个是jaeger在测试类中写的一个无借鉴意义的匿名内部类实现,我们略过。
-
AutoFinishScopeManager与下面的ThreadLocalScopeManager类似,只是可以自动finish span 这里略过。 -
NoopScopeManager与NoopScopeManagerImpl一起来讨论,NoopScopeManager返回的当前span/scope为null,而将一个有内容的span传入active(span,bool)方法中将该span激活,总会返回一个noopScope,而noopScope返回当前的 活动的 span总为 noopSpan 也就是内容为空的span。 -
ThreadLocalScopeManager使用ThreadLocal来存储不同线程的scope对象,在多线程环境下可以通过获取到当前线程的scope来获取当前线程的活动的 span。
下面我们着重看一下opentracing中实现了Scope接口的ThreadLocalScope类是如何工作的,以及解释为什么说ThreadLocalScope管理着单个线程中的所有的span:
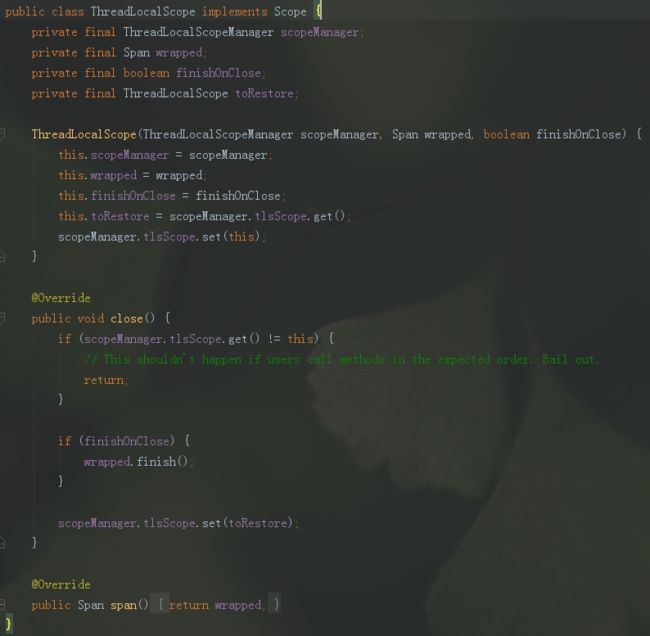
在ThreadLocalScopeManager中会通过activate(Span span, boolean finishOnClose)调用ThreadLocalScope的构造方法,将传入的span激活为 当前活动的 span。我们看一下其构造函数就能发现,与其说是激活传入的span倒不如说是激活包裹(wrapped)该span的scope为 当前活动的 scope。我们看到这两句:
this.toRestore = scopeManager.tlsScope.get();
scopeManager.tlsScope.set(this);
将之前活动的scope作为当前scope的属性toRestore来存储,并将当前scope设置到scopeManager中作为当前线程最新的scope,或许你已经联想到了FIFO先入先出队列,有些类似栈中的元素,以及链表,当前活动的元素指向下一级,如果当前活动元素被取出栈中,则链表指向的元素被设置为当前活动元素。
同理,ThreadLocalScope也需要实现上面说的 如果当前活动元素被取出栈中,则链表指向的元素被设置为当前活动元素 。这在其close()方法中体现了:
scopeManager.tlsScope.set(toRestore);
同样在close()方法中也能看到,我们激活span时调用的
ThreadLocalScopeManager.activate(Span span, boolean finishOnClose)
方法中boolean finishOnClose参数在close()方法中的作用,用于判断当scope close时,要不要同时finish span。
所以,不难理解当前线程中的ThreadLocalScope管理着当前线程所有曾被激活还未释放的span。
以上我们对
Span的构造以及为什么要引入ScopeManager与Scop做了解释。我们可以做个小结方便后续内容的理解。Span的构造完成后,必须要注册到ScopeManager中激活才能为之后的追踪构建正确的span之间的如parnet-child之类的关系。
下面我们看一下如何启动一个span。
try-with-resource方式
try (Scope scope = tracer.buildSpan("someWork").startActive(true)) {
// Do things.
//
// `scope.span()` allows us to pass the `Span` to newly created threads.
//上面这句话是opentracing中的,我的理解是scope.span()只能在同线程的不同方法栈中传递,而无法跨线程传递
//这是因为scopeManager中使用ThreadLocal而ThreadLocal.get()是根据线程来区分的
//不同线程的scope=thradLocal.get()是不同的,scope.span()获取到的span必然不一样。
} catch(Exception ex) {
// cannot record the exception in the span since scope is not accessible and span is finished
}
我们看到在try中通过tracer 构造了一个spanName为someWork的span并将其启动与激活,且当scope close时,span也会finish。
由于Scope接口继承了Closeable接口,因此会在catch 与 finally 语句执行前就会调用close()方法,如果我们向上面那样设置为startActive(true),就会在scope.close()时同时调用span.finish(),这样就会导致我们所追踪的方法catch到异常或要在catch与finally中添加tag变得不可能,因为在scope.close()后我们已经无法获取到那个包裹着我们所需要的span的scope了,也就无法通过scope获取到span。
同理设置为false也会导致由于无法获取到当时的scope而无法获取到想要的span的情况,更可怕的是,如果我们设置为false,那个span是没有finish的,而我们又无法获取到当时的span了,所以除非我们在try语句中手动的设置scope.span.finish(),否则span永远没有finish。
因此opentracing中也建议谨慎的使用startActive(true)
opentracing推荐的方式是start一个span后,在需要的时候active激活它,也就是注册到scopeManager中。
如下:
Span span = tracer.buildSpan("someWork").start();
try (Scope scope = tracer.scopeManager().activate(span, false)) {
// Do things.
} catch(Exception ex) {
Tags.ERROR.set(span, true);
span.log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
span.finish();
}
可以看到这里设置了activate(span, false),因为根据opentracing的span接口的规范定义的finish方法: With the exception of calls to context, this should be the last call made to the span instance. Future calls to finish are defined as noops, and future calls to methods other than context lead to undefined behavior. 这就意味着如果不是设置为false,则会在try中finish span,则在catch于finally中无法在对span进行设置。
那是不是只能使用try的方式,必须要注册到scopeManager中激活当前span呢?我的理解是注册到scopeManager是为了用于建立span间的如parent-child之类的关系,当方法嵌套调用并去我们两个方法都想要进行追踪时,将span注册到scopeManager中是必须的,否则就只能向之前讨论的一样将span作为方法的参数进行传递。
而如果我们知道目前追踪的方法是最后的一个span,我们不会有其他新产生的span与其产生关系(之前的旧span是会与其产生关系的,如作为某个之前产生的旧span的child),那我们就可以直接:
Span span = tracer.buildSpan("someWork").start();
//do something
span.log("some event");
//do second thing
span.log("second event");
//
span.finish();
这样也是可以的。只是没有将span注册到scopeManager中也就无法在别处获取到这个span,仅此而已。
这里要说一点,即便是将span注册到scopeManager中,如果scope close之后,也无法在别处获取到那个span,即便如上面第二种方法,也只能在当前方法中获取span对象。
下面我们讨论下,某些情况中,我们需要两个线程间的span产生关系,但是通过上面的讨论我们知道scopeManage与scope都是与线程相关的,不同线程的span无法取得联系,但是在某些情况下,不同线程中的span可以产生联系。下面的示例是opentracing的一个示例,演示了一个span在一个线程中start但是在另一个线程中finish的情况:
// STEP 1 ABOVE: start the Scope/Span
try (Scope scope = tracer.buildSpan("ServiceHandlerSpan").startActive(false)) {
...
final Span span = scope.span();
doAsyncWork(new Runnable() {
@Override
public void run() {
// STEP 2 ABOVE: reactivate the Span in the callback, passing true to
// startActive() if/when the Span must be finished.
try (Scope scope = tracer.scopeManager().activate(span, false)) {
...
}
}
});
}
下面我们引申一下,线程A中start SpanA,然后在线程B 中start SpanB 并且 SpanB 是 SpanA 的child。
try (Scope scope = tracer.buildSpan("SpanA").startActive(false)) {
...
final Span spanA = scope.span();
doAsyncWork(new Runnable() {
@Override
public void run() {
// STEP 2 ABOVE: reactivate the Span in the callback, passing true to
// startActive() if/when the Span must be finished.
try (Scope scope = tracer.buildSpan("SpanB").asChildOf(spanA).startActivate(false)) {
...
Span spanB = scope.span();
}catch{
...
}finally{
spanB.finish();
spanA.finish();
}
}
});
}catch{
...
}finally{
...
}
这里我们根据上面的scopeManager,scope与span的启动做一个小讨论:
public void outerMehtod(){
Span outerSpan = tracer.buildSpan("outerMethod").start();
try (Scope scope = tracer.scopeManager().activate(outerSpan , false)) {
innerMethod();//调用innerMethod
} catch(Exception ex) {
Tags.ERROR.set(outerSpan , true);
outerSpan .log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
outerSpan .finish();
}
}
public void innerMethod(){
Span innerspan = tracer.buildSpan("innerMethod").start();
try (Scope scope = tracer.scopeManager().activate(innerspan , false)) {
//do something
} catch(Exception ex) {
Tags.ERROR.set(innerspan , true);
innerspan .log(Map.of(Fields.EVENT, "error", Fields.ERROR_OBJECT, ex, Fields.MESSAGE, ex.getMessage()));
} finally {
innerspan .finish();
}
}
如上面的示例中,我们对
outerMethod与innerMethod都构建了span进行追踪,并且显然outerSpan是innerSpan的parent span,并且我们可以在outerMethod中对outerSpan设置tag等信息,同时也可以在innerMethod中对innerSpan设置tag等信息。
现在设想这么一种情况,我们在outerMethod有些数据想要设置到innerMethod的innerSpan中,这该如何做呢?或许你会疑惑,为什么要做么做。如果我们考虑grpc的追踪,java中可以使用grpc提供的拦截器对client与server之间的通信进行拦截,这时我们就可以将grpc通过proto文件自动生成的方法看做innerMethod,将我们封装的方法看做outerMethod,java中可以使用拦截器对innerMethod进行拦截并设置span信息,但是我们自己封装的outerMethod中有些如关键的参数值等也想要进行记录该如何做呢?
一是如上面一样对我们自己封装的outerMethod也构造span
二是想办法将outerMethod中的想要被记录的数据写入innerMethod的innerSpan中,显然通过方法参数传递的思路是不合适的。
第一种办法就如上文一样。这里介绍第二种思路该如何做,既然我们通过拦截器拦截innerMethod,那就需要我们提供一个拦截器的实现,我们就可以在这个拦截器的实现中做文章,该类中可以放入一个接口类作为成员变量,并作为拦截器实现类的构造函数的参数,该接口中有如log(Span,String)类似的方法,这样在grpc构造channel中传入拦截器时,我们需要传入自己实现的拦截器实现类的实例,我们就可以在构造拦截器实现类时,将一个实现上述有log功能的接口实现类作为方法参数传入构造函数,从而构造出拦截器实现类,传入channel对象中实现拦截目的。
通过上述讨论,两种方式都可以实现在outerMethod中对innerMethod的innerSpan进行操作。
现在我们跟进一步讨论,我们希望提供一套工具,让开发人员通过使用我们的工具能够以尽量少的代码让其系统增加追踪的功能,就以grpc为例,面对上面讨论的问题与我们开发一套简洁易用工具的要求,我们该采用何种方式呢?
若采用第一种方式,用户有相当的自由决定添加什么信息存储到span中,但是需要书写很多代码。当然我们还可以对outerMethod进行一下封装,很容易看到用户的核心业务代码为innerMethod,而outerMethod中其余代码类似于模板代码,我们可以只让用户提供innerMethod方法作为参数,而其余内容我们为用户提供默认实现。而将函数作为参数进行传递只能在java8 中使用lambda表达式,这就使得我们的工具要求用户必须使用JDK1.8+,若我们要考虑兼容性,则可以提供一个接口,有一个process方法,用户需要实现接口并实现process方法,实现process的内容为innerMethod。且不说兼容性与代码简洁性(实现接口也需要很多模板代码)的矛盾,这样做看起美好比起之前的简洁了(lambda表达式),但是用户失去了自由控制记录何种信息的权利,只能使用我们在catch语句中的记录异常的默认实现。
若采用第二种方式,用户可以不用再outerMethod中构建span并书写多行模板代码了,但是用户需要在添加grpc拦截器时就要提前写好含有log(Span,String)方法的接口的实现类,然后作为方法参数传入拦截器的构造函数中。且不说使用起来不方便(要在outerMethod方法外书写将要记录outerMethod方法中的什么信息),由于拦截器作用于channel上,而client与server之间只有一个channel实例存在,因此拦截器一旦添加到channel上之后无法更改。且client与server之间有多个方法调用时,如对于地图服务,server端可能同时提供计算点point与计算线line的功能,这显然是两个方法,用户就需要在实现含有log(Span,String)方法的接口时判断一下若是计算point的方法log什么信息到span中,若是计算line的方法log什么信息到span中。
以上讨论是我对这个问题的理解,可能有理解的不对的地方或者您有更好的方案可以解决上面提到的问题,请不吝告知。
引申一下,我们最希望用户的使用体验是在
outerMethod中通过span.log(String)就可以将outerMethod中关键信息设置到innerMethod的innerSpan中,但是通过前面对scopeManage与scope的讨论我相信你会认同这种方式尽管简洁但是是不可行的,因为在outerMethod中innerMethod的innerSpan还没有构建更不用说变量的生命周期等问题了。
下面我们详细看看,span为什么在初始化的时候就能自带与之间构造的旧的span建立起关系,与我们刚刚了解到的scopeManager与scope有什么关系,以及如何自定义在初始化span时不构建关系。
我们从上面的示例看到启动span似乎有两种方式,start()与startActive(boolean finishSpanOnClose),而实际上startActive(boolean finishSpanOnClose)也调用了start()方法,而关系的构建就是在这一步完成的,所以我们先研究下start()方法。以下是jaeger的实现。
public io.opentracing.Span start() {
SpanContext context;
// Check if active span should be established as CHILD_OF relationship
if (references.isEmpty() && !ignoreActiveSpan && null != scopeManager.active()) {
asChildOf(scopeManager.active().span());
}
String debugId = debugId();
if (references.isEmpty()) {
context = createNewContext(null);
} else if (debugId != null) {
context = createNewContext(debugId);
} else {
context = createChildContext();
}
long startTimeNanoTicks = 0;
boolean computeDurationViaNanoTicks = false;
if (startTimeMicroseconds == 0) {
startTimeMicroseconds = clock.currentTimeMicros();
if (!clock.isMicrosAccurate()) {
startTimeNanoTicks = clock.currentNanoTicks();
computeDurationViaNanoTicks = true;
}
}
Span span =
new Span(
Tracer.this,
operationName,
context,
startTimeMicroseconds,
startTimeNanoTicks,
computeDurationViaNanoTicks,
tags,
references);
if (context.isSampled()) {
metrics.spansStartedSampled.inc(1);
} else {
metrics.spansStartedNotSampled.inc(1);
}
return span;
}
其中:
/ Check if active span should be established as CHILD_OF relationship
if (references.isEmpty() && !ignoreActiveSpan && null != scopeManager.active()) {
asChildOf(scopeManager.active().span());
}
这一部分指明了span在初始化时就先构建了与之前span的关系。opentracing说有两种甚至未来会支持更多的span间的关系,现在的两种关系为:CHILD_OF,FOLLOWS_FROM。由于我们构造span时没有调用addReference, asChildOf等方法,因此references为空,也就是说,我们可以人为的指定当前构造的span与当前active的span的关系是CHILD_OF还是FOLLOWS_FROM,若我们没有指定,则如上面看到的,会默认使用CHILD_OF关系。
另外,如果我们不希望初始化span时为其构建任何关系,则将ignoreActiveSpan设置为true即可。
同时我们再看在初始化span时,除了构建span间的关系,还做了什么事情。
String debugId = debugId();
if (references.isEmpty()) {
context = createNewContext(null);
} else if (debugId != null) {
context = createNewContext(debugId);
} else {
context = createChildContext();
}
构造该span的spancontext,这里有三种情况,如果references即span间的关系为空,则认为该span为rootSpan即根span,若不为空再看debugId是否为null,不为null则根据debugId构建context,最后一种情况是构建一个span作为reference中与当前span为child_of关系的span的child。可以看到这里有些复杂,分为三个分支,其中debugId这个分支是用于debug的,jaeger中是这么解释的:
the name of HTTP header or a TextMap carrier key which, if found in the carrier, forces the trace to be sampled as "debug" trace. The value of the header is recorded as the tag on the root span, so that the trace can be found in the UI using this value as a correlation ID.
这里说的the value of the header is recorded as the tag on the root span 是指会将debugId放入tag中,而为什么是root span?这是因为在span构造中,如果发现有debugId会构造一个root span,只不过将其spancontext的flag属性做一个标识,以便于真正的root span区分,并将debugId放入tag中。
这就意味着我们将一个包含debugId的spancontext在进程间传递,这些span不会连接成trace,因为有debugId,每个span都会有自己的traceId与spanId同时parentId为0,这种情况下逻辑上是同一条trace的span在其tag中有相同的debugId。虽然有点绕,但是还是要解释清楚,并且不建议使用debug模式。
因此在我们去除debug后再来看spanContext的生成,逻辑就比较清楚了,如果是root span就随机生成id作为traceId与spanId,如果不是root span则使用reference属性中找到该span的parent span(根据是否为child_of的关系来判断)获取其traceId作为自己的traceId,获取其spanId作为自己的parentId。
这里值得一说的是,在opentracing中增加了Baggage用于在整个trace中传递用户自定义的内容,因此这里在构建child span的时候同时需要将该span的reference中所有的span的baggage内容传递过来作为当前span的spanContext中的一部分,以便实现baggage在整个trace中的传递,也就是baggage必须在每个span中都存在然后不断传递给后续的span。
start()方法剩下的的工作就是记录开始时间并构造span对象,使用metrics统计信息与返回span。
Span的构建,启动与管理就写到这里。这一部分并没有涉及到jaeger如何实现opentracing的Span接口的,下面会介绍jaeger中Span接口的实现。
获取Span添加信息
理解了上面的ScopeManager,Scope后对于如何获取span应该很熟悉了,下面着重介绍能对span添加什么信息,结合jaeger对opentracing的Span接口的实现来解释。
在jaeger的实现中,Span的信息分为如下几方面:
- span核心信息,如:traceId,spanId,parentId,baggage等
- log信息 与tag的区别是带有时间戳
- tag信息
- span的其他信息,如:startTime,duration
其中span的核心信息存储在SpanContext中,在构建span是就会创建,为了防止用户擅自修改核心信息,spanContext中的所有成员都是final修饰的。根据opentracing的规范, SpanContext represents Span state that must propagate to descendant Spans and across process boundaries. SpanContext is logically divided into two pieces:
(1) the user-level "Baggage" that propagates across Span boundaries and
(2) any Tracer-implementation-specific fields that are needed to identify or otherwise contextualize the associated Span instance (e.g., a
上面是说SpanContext代表的是span中必须传递的信息,在逻辑上分为两部分,一分部分是普通的traceId,spanId等信息,另一部分是baggage这种用户自定义需要传递的信息。
startTime与duration是span会自己进行记录,用户无需干预。
因此用户能够使用的就是log与setTag以及setBaggage。用户只需通过span调用相应方法即可。
这里值得一提是是jaeger实现的span中对baggage的赋值。
@Override
public Span setBaggageItem(String key, String value) {
if (key == null || (value == null && context.getBaggageItem(key) == null)) {
//Ignore attempts to add new baggage items with null values, they're not accessible anyway
return this;
}
synchronized (this) {
context = tracer.setBaggage(this, key, value);
return this;
}
}
当然,通过上面对spanContext的说明,我们知道上面同tracer返回的context肯定是重新new的一个spanContext对象,因为spanContext中所有成员都是final的。
而tracer中的方法:
SpanContext setBaggage(Span span, String key, String value) {
return baggageSetter.setBaggage(span, key, value);
}
看到是由baggageSetter来完成baggage的注入,我们继续进入setBaggage方法,为了方便理解,将方法注释也粘贴过来。
/**
* Sets the baggage key:value on the Span and the corresponding
* logs. Whether the baggage is set on the span depends on if the key
* is allowed to be set by this service.
* A SpanContext is returned with the new baggage key:value set
* if key is valid, else returns the existing SpanContext
* on the Span.
*/
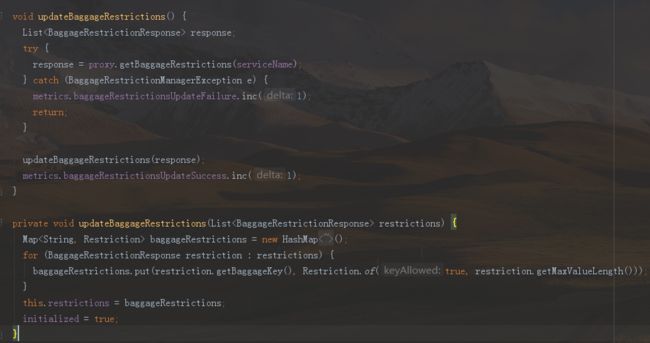
public SpanContext setBaggage(Span span, String key, String value) {
Restriction restriction = restrictionManager.getRestriction(span.getServiceName(), key);
boolean truncated = false;
String prevItem = null;
if (!restriction.isKeyAllowed()) {
metrics.baggageUpdateFailure.inc(1);
logFields(span, key, value, prevItem, truncated, restriction.isKeyAllowed());
return span.context();
}
if (value != null && value.length() > restriction.getMaxValueLength()) {
truncated = true;
value = value.substring(0, restriction.getMaxValueLength());
metrics.baggageTruncate.inc(1);
}
prevItem = span.getBaggageItem(key);
logFields(span, key, value, prevItem, truncated, restriction.isKeyAllowed());
metrics.baggageUpdateSuccess.inc(1);
return span.context().withBaggageItem(key, value);
}
方法的注释解释了方法的逻辑为:该方法会将baggage 的key与value添加到相应的span的log中去。而这个baggage能够添加到spanContext中还要看server是否认定该key合法。如果不合法,会返回未修改的spanContext,若合法,则会返回新的spanContext其包含添加新数据后的baggage。
这里我们看一下tracer中的baggageSetter。
通过之前最简单的构建tracer的方式tracer = Tracer.Builder("serviceNmae").build()构建的tracer,其baggageRestrictionManager为DefaultBaggageRestrictionManager
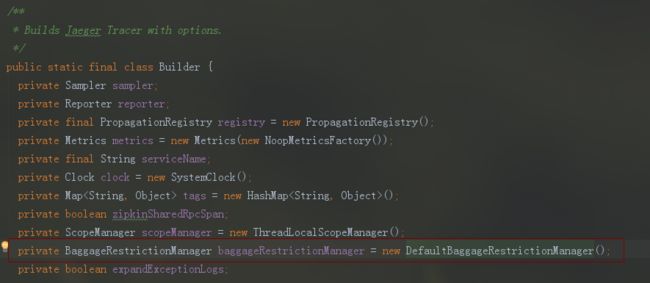
在tracer的构造函数中,通过baggageRestrictionManager构造了baggageSetter
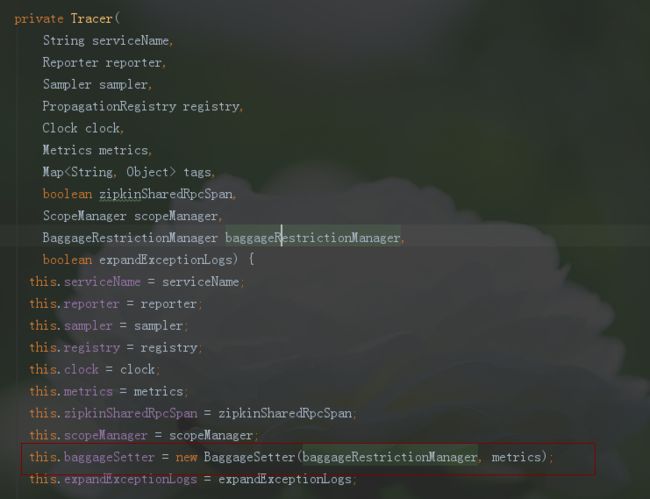
通过上面的setBaggage(Span span, String key, String value)方法可以看到,关键在于
Restriction restriction = restrictionManager.getRestriction(span.getServiceName(), key);
该方法返回的restriction通过调用isKeyAllowed()来判断能否将该key-value数据添加到baggage中。而默认的DefaultBaggageRestrictionManager
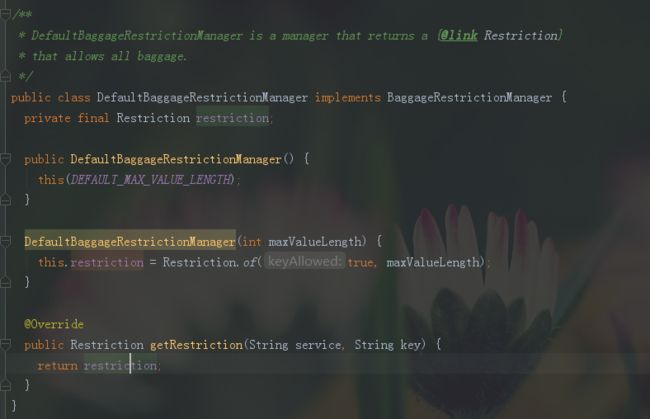
通过注释可以看到,它允许所有的baggage数据。
我们按照同样的思路再看另一个实现类
RemoteBaggageRestrictionManager
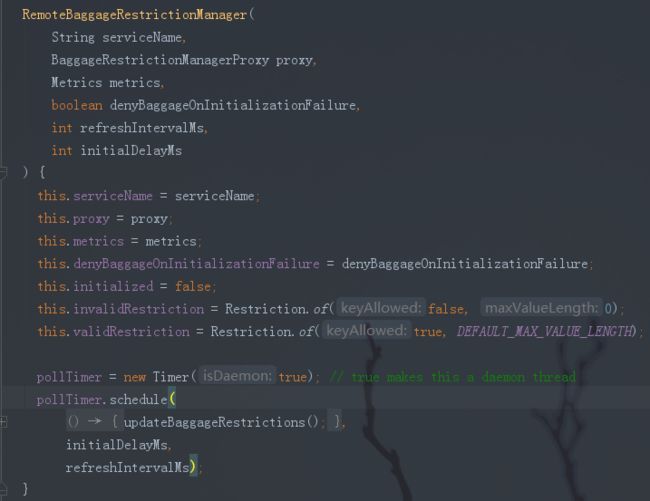
可以看到RemoteBaggageRestrictionManager的构造方法开启了一个定时任务,定时从服务端获取baggage的策略。
其获取思路为定时从服务端获取该serviceName也就是该服务对应的所有的baggage的key的策略。也就是该服务允许哪些key设置到baggage中,将这些信息放到一个map中,这个map每个从服务端获取策略后都会更新。等到传入某个key判断该key能否加入baggage时,再去map中去找有没有该key,若有则允许,若没有则不允许。
结束并发送Span
调用span.finish()方法标志着span的结束,上面也提到过,finish方法应该是对应span实例的最后一个调用的方法。在span中finish方法还只是校验和记录的作用,真正发送span的就是开头提到的tracer,tracer包含了sampler、report等全局的功能,因此在finish中调用了tracer.report(span)方法。而tracer中的report方法是使用其成员report的report方法,上面讲过默认实现是RemoteReporter,它默认使用的是UdpSender。
我们分析下report是如何发送数据的。
在RemoteReporter中有一个BlockingQueue队列其作用是接收Command接口的实现类,其长度可在构造方法中传入。在RemoteReporter的构造函数中开启了两个守护线程。一个线程定时往BlockingQueue队列中添加flush命令,另外一个线程不停的从BlockingQueue队列中take数据,然后执行Command.excute()方法。而report(span)方法就是往BlockingQueue队列中添加AppendCommand类。
@Override
public void report(Span span) {
// Its better to drop spans, than to block here
boolean added = commandQueue.offer(new AppendCommand(span));
if (!added) {
metrics.reporterDropped.inc(1);
}
}
可以看到如果返回的added变量为false,也就是队列满了无法再加入数据,就会抛弃该span的,最终该span的信息不会发送到agent中。因此队列的长度也是有一定的影响。
而AppendCommand类的excute()方法为:
class AppendCommand implements Command {
private final Span span;
public AppendCommand(Span span) {
this.span = span;
}
@Override
public void execute() throws SenderException {
sender.append(span);
}
}
所以,我们看到,execute()方法并不是真正的发送span了,而只是把span添加到sender中去,由sender实现span的发送,reporter类只负责发送刷新与发送的命令。
如果我们继续深入下去,会发现UdpSender是抽象类ThriftSender的实现类,sender.append(span)方法调用的是ThriftSender的append(Span)方法,而该方法又会调用ThriftSender的flush()方法,最后这个flush()方法会调用抽象类ThriftSender的抽象方法send(Process process, List。该方法在实现类UdpSender中表示如下:
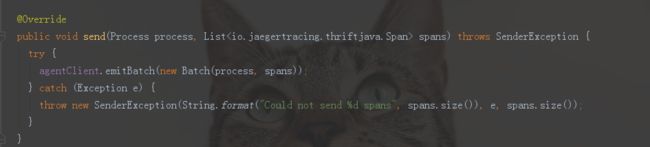
而该方法中使用的是thrift插件编译thrift文件自动生成的类和方法,用于client和server端发送和接收对象信息。这里作为方法参数的Process类也是自动编译生成的类。
thrift文件内容如下:

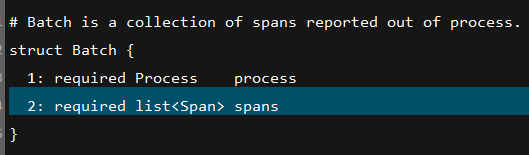
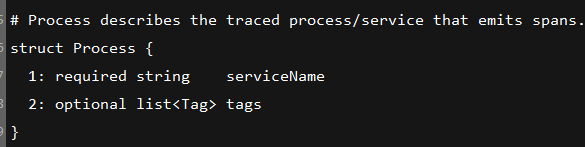
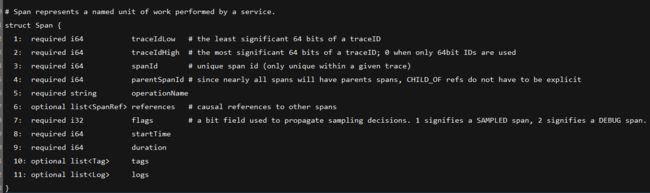
从对Span对象的定义可以看到,jaeger并没有将baggage的内容发送给agent,也就是说agent处理数据后发送到collector或者直接存储到es都不会看到baggage的内容,后期我们要实现自己的目的还是要修改一下。
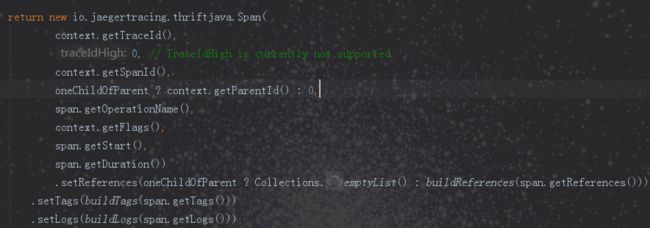
我们也看到在定义文件中,Span提供了类似brave中的traceIdHigh构建128位的traceId的功能,但是实际在jaeger的实现中还未支持,见下图:
对jaeger-core的设计思路就解析到这里,刚刚粗略看完一遍还有疏漏和理解的不对的地方,请不吝指出。对这方面感兴趣的朋友也欢迎多多交流。