2019独角兽企业重金招聘Python工程师标准>>> 
知识点一:执行计划
1)概念
a) 一段SQL在执行之前,都需要SQL编译器,查询优化器进行编译优化,SQL编译主要是解析语句,创建解析树,表达式树,执行计划(主要是查询优化器处理)。这个工作其实是比较耗时,所以SQL希望尽可能的做一次编译好后,然后缓存,下次继续使用。但也可能过期,也可能优化器优化的不够好(可能是其他原因造成,比如语句复杂度等)。
b) 执行计划也是我们能够分析语句执行中间步骤与信息的一个较好的途径。
c) 执行计划有估计计划和实际的计划,估计计划是不运行SQL语句产生的。实际计划是需要SQL运行才能获取的到
2)查看方式
a) 估计执行计划。快捷键CTRL+L
b) 实际执行计划。快捷键CTRL+M

3)实际的执行计划种类
a) 图表方式
直观,也是最常用的,在SSMS中显示实际计划按钮执行后即可。
b) 文本方式
i. 打开方式:SET SHOWPLAN_TEXT on
ii. 特点:以文本形式显示,显示的信息较简单。

c) xml方式
i. 打开方式:SET SHOWPLAN_XML ON
ii. 特点:带有结构的信息,显示的信息比较详细。
4)示例与解说
a) 几个概念:
i. 聚集索引:聚集索引确定了表中数据的物理存储顺序,因此每个表只可能存在一个聚集索引。叶子节点就是表中的数据。
ii. 非聚集索引:该索引的逻辑顺序与物理顺序是不一致的。叶子节点不是表的数据,依然是索引,只是有一个地址指向了数据节点。
iii. 堆表:当一个表的数据存储是无序的,即不包含聚集索引,则为堆表。
iv. 聚集表:当一个表的表结构是有序的时候,即包含了聚集索引,则为聚集表
b) 表准备:
drop table tbtest
--执行计划讲解脚本
create table tbtest(id int,name char(7000),age int,name1 varchar(10))
GO
insert into tbtest
select
number,ltrim(floor(rand(checksum(newid()))*1000))+char(floor(rand(checksum(newid()))*(122-97)+97)),
floor(rand(checksum(newid()))*101),char(floor(rand(checksum(newid()))*(122-97)+97))
from
master..spt_values
where
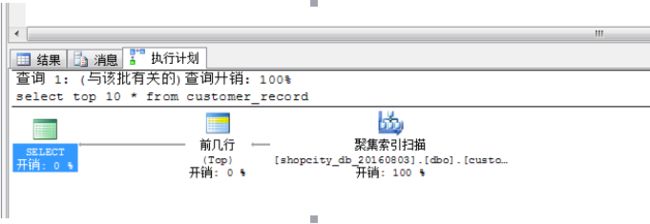
type='p' and number between 0 and 2048c) 示例一:表扫描
i. select * from tbtest
ii. 说明:由于表中没有建任何索引字段,因此此时查表为表扫描。
iii. 执行计划图:
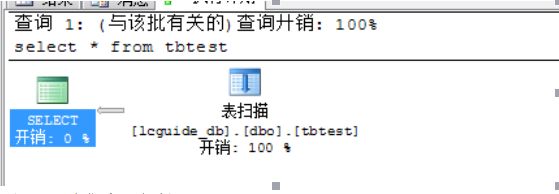
d) 示例二:聚集索引扫描
i. 执行建立聚集索引的脚本:create clustered index idx_id on tbtest(id)。
ii. 执行查询语句:select * from tbtest ,此时代表的是聚集索引扫描。
iii. 执行计划图:
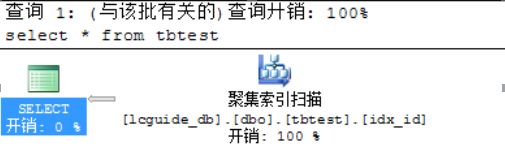
e) 示例三:聚集索引查找
i. 查询语句:select * from tbtest where id = 1
ii. 根据聚集索引字段去查找。
iii. 执行计划图:

f) 示例四:聚集索引查找+扫描
i. 一般是范围查找,先通过聚集索引定位到首行,然后进行后续范围扫描
ii. 示例语句:select * from tbtest where id between 1 and 200
iii. 执行计划图:

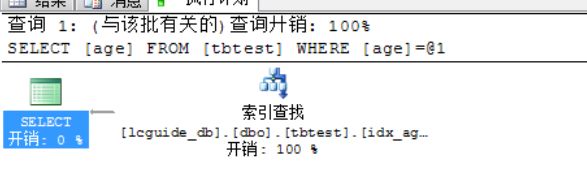
g) 示例五:非聚集索引查找
i. 在age字段创建非聚集索引:create index idx_age on tbtest(age)
ii. 查询sql:select age from tbtest where age = 10(注意只是查询非聚集索引的字段)
iii. 执行计划图:
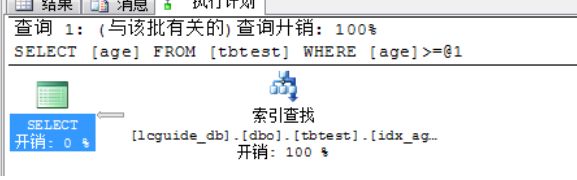
h) 非聚集索引查找+扫描
i. 示例语句:select age from tbtest where age >= 10(注意只是查询非聚集索引的字段)
ii. 执行计划图:
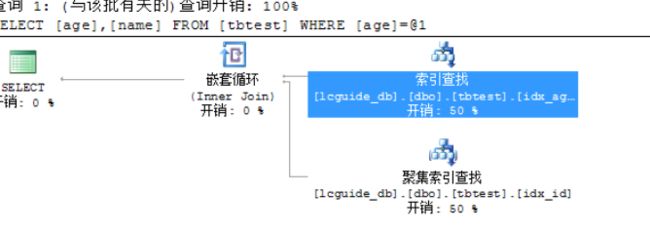
i) 非聚集索引查找+书签查找
i. 示例语句:select age,name from tbtest where age = 4(name列没有索引)
ii. 执行计划图:
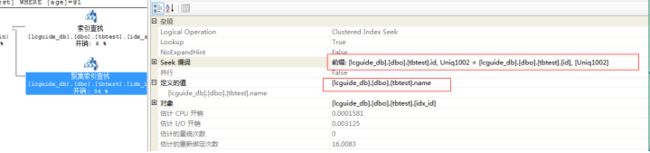
iii. 详细说明:
1. 根据seek谓词age字段进行非聚集索引查找,获得三列:id、age、临时的一个rowid(图中的名字表示Uniq1002)。

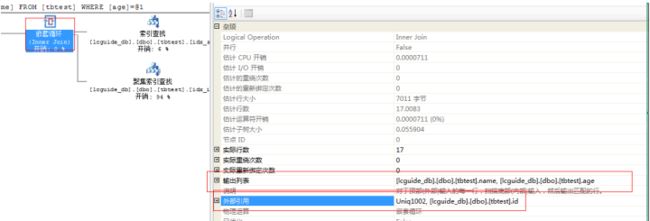
2. 根据第一步聚集索引得到的id、rowid。通过聚集索引查找取得name字段。
3. 最后通过inner join组合出需要的两列:age,name
知识点二:语句运行信息分析
1)概念
a) 比如编译时间,执行时间,每个表的相关扫描次数,逻辑读取,物理读取等信息
b) 根据这些信息进行分析语句执行所花的时间,所花的IO进行一定优化可行性分析。
c) 可与执行计划一起配合综合性分析
2)查看方式
a) SET STATISTICS TIME ON:显示SQL执行语句的编译时间,执行时间
b) SET STATISTICS IO ON:显示SQL执行语句的 磁盘IO信息
c) SET STATISTICS PROFILE ON:显示SQL执行的计划信息以及消耗信息,还有估计与实际的行数信息,这是数据表显示方式,在图表中也有显示,XML也有显示,但是数据表信息更为直观
3)示例
a) 显示语句的编译和执行时间
i. SET STATISTICS TIME ON; select * from tbtest where age != 9999999(执行前要清下数据库缓存,因为数据库第一次执行的时候会将编译后的结果缓存起来,避免下次再重新编译,看不出效果)
ii. 结果:
SQL Server 分析和编译时间:
CPU 时间 = 15 毫秒,占用时间 = 63 毫秒。
SQL Server 执行时间:
CPU 时间 = 16 毫秒,占用时间 = 377 毫秒。
iii. 说明:
1. 分析编译时间:cpu时间是所花纯cpu时间 。占用时间是所花总时间,一般相差不多
2. 执行时间:cpu是执行所花纯cpu,占用时间是总时间,可能还有花磁盘IO时间 或者等待时间
3. 总运行时间:cpu总时间是分析编译+执行,执行总时间是占用时间总和
b) 显示SQL执行磁盘IO信息
i. SET STATISTICS IO ON; select * from tbtest where age != 9999999
ii. 结果:
表 'tbtest'。扫描计数 1,逻辑读取 2056 次,物理读取 1 次,预读 2049 次,lob 逻辑读取 0 次,lob 物理读取 0 次,lob 预读 0 次
iii. 说明:
物理读取加预读,如果不为0则数据没在内存中,逻辑读取越大则需要读取的页数越大,扫描计数越大则表明对表扫描次数多。Lob代表读取大数据。
c) 显示SQL执行的计划信息以及消耗等其他详细信息
i. SET STATISTICS profile ON; select * from tbtest where age = 10
ii. 结果(从下往上看):

知识点三:常见T-SQL语句写法问题与优化
1)常见问题一:字段用函数处理或者字段用表达式计算问题
查询时将条件字段用函数或者计算处理:
例如:select * from tbtest where age/10=10; -- or age+90=100
改写:select * from tbtest where age=100;--age=10
如果条件列能用上索引。用函数处理过后,计划是需要先进行表达式计算才能进行过滤,导致索引无法使用。
时间查询处理:
例如:select * from tb where datediff(dd,dtcol,getdate())=0查询当天的。
改写:select * from tb where dtcol>=date and dtcol 疑问:查看两者的执行计划,基本一样,怎么理解第一条语句无法使用索引。 2)常见问题二:隐式转换问题:参数类型,字段类型不一致 结果: 第一条sql: 第二条sql: 总结:看详细计划。你可以看到第一个里面进行了一个常量转换。索引查找里面也将列进行了一个列转换而第二个则是直接索引查找。 3)其他一些注意点: 1)语句复杂度,尽量简单 2)视图和过程的深度:尽量不要嵌套过多 3)表格联接数量:尽量不要太多,与复杂度类似 4)尽量不要用select*号:主要是尽量返回所需要的数量列即可。 5)尽量去除不必要的排序与计算。 6)动态exec语句要注意:编译问题,注入问题。 7)尽量union all 不要union :union内部会进行去重计算。 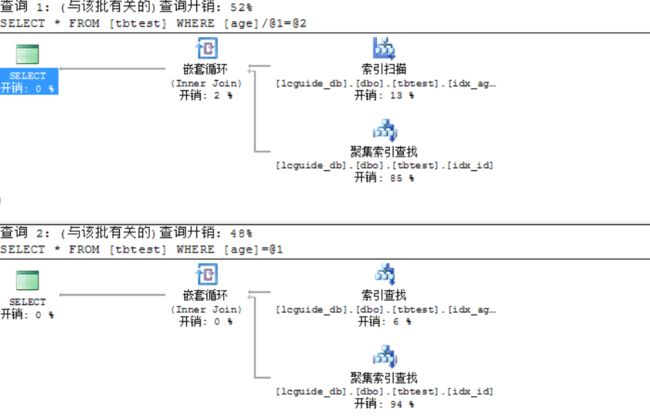
declare @age nvarchar(10)
set @age='10'
select age from tbtest where age=@age;
declare @age1 int
set @age1=10
select age from tbtest where age=@age1;
![]()
