Source: Connected Brain
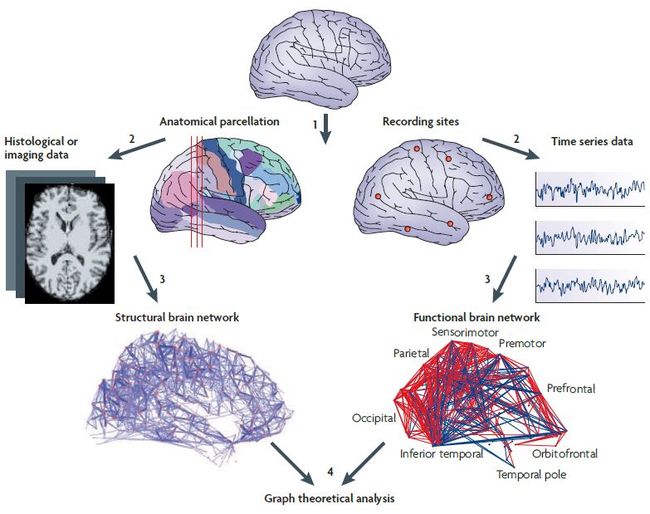
Figure above: Bullmore E, Sporns O. Complex brain networks: graph theoretical analysis of structural and functional systems.[J]. Nature Reviews Neuroscience, 2009, 10(3):186-198.
Graph measures
A graph G consisting of a set of vertices V and a set of edges E can be characterized by several measures, some relatively simple, others quite complex. Here we describe measures for unweighted networks. For most of these measures weighted versions have now been described as well.
- Degree
One of the most important and elementary measures is the degree, often indicated by k. The degree of a vertex is the number of connections or edges it has. The probability that a randomly chosen vertex will have degree k is given by the degree distribution, indicated by P(k). The form of the degree distribution provides important information about the structure of the network. As described below, different types of graphs have their own characteristic degree distribution.
- Clustering coefficient
The clustering coefficient of a vertex is the probability that the neighors of this vertex (all other vertices to which it is connected by an edge) are also connected to each other. The clustering coefficient of a vertex ranges between 0 and 1. The average clustering coefficient C of the whole network is the average of the clustering coefficients of all individual vertices. The clustering coefficient is considered to be a measure of the local connectivity or “cliqueness” of a graph. High clustering is associated with robustness of a network, that is resilience against random network damage.
- Motifs and modules
The clustering coefficient is a special case of a more general graph property referred to as motifs. The clustering coefficient depends upon the presence of the triangle motif, consisting of three vertices fully connected by edges. Other more complex motifs exists as well, and their presence in graphs can be quantified. Subgraphs that consist of sets of vertices that are more strongly connected to each other than to the rest of the network are called modules. Identification of modules within complex networks is important, since modules often correspond to different functional aspects of the networks, and modules may also be important for the way normal and abnormal activity can spread through the network. It is also possible to define modules within modules. Networks with such a structure are said to have a hierarchical modularity. The concept of a module is a statistical one. Different definitions of modularity exist, the most well known being the modularity as defined by Newman. Alternatively, modularity can also be defined in terms of the eigenvalues and eigenvectors of the graphs matrix. Please note that the clustering coefficient, motifs and modules are descriptions of network structure at increasingly larger scales.
- Pathlength and efficiency
Whereas clustering reflects local network structure, the shortest pathlength reflects the level of global integration in the network. A shortest path between two nodes A and B is the path between A and B with the smallest number of edges. The average shortest path L of a network is the average of all shortest paths between all pairs of vertices. The diameter of a graph is the longest of all shortest paths. Related to the idea of the average shortest path is that of global efficiency, which is the inverse of the average shortest path. The local efficiency of a particular vertex is the inverse of the average shortest path connecting all neighbors of that vertex.
- Assortativity
Related to the notion of degree is the concept of mixing or assortativity. If vertices with a high degree tend to be connected to other vertices with a high degree, and vertices with a low degree to other low degree vertices, the graph is said to be assortative. An assortative graph has a positive degree correlation. In a disassortative graph, the degree correlation is negative, and high degree vertices tend to connect to low degree vertices and vice versa.
- Centrality and hubs
Another important concept related to that of node degree is centrality. Centrality refers to the relative importance of a node or vertex within the network. Node degree is in fact one, relatively simple measure of centrality. A more sophisticated measure of centrality is betweenness. The betweenness centrality of a particular vertex is the fraction of shortest paths in the network that pass through this vertex. In a similar way, betweenness centrality can also be defined for edges (edge centrality). Another concept of centrality is based upon graph spectral analysis. Eigenvector centrality of a vertex is the value of the vector component, where the vector is vector that corresponds to the largest eigenvalue (spectral radius) of the adjacency matrix. If the notion of hub centrality is combined with the definition of modules it becomes possible to classify hubs. Hubs that are mainly connected to other vertices in the same module are referred to as provincial hubs; hubs that are mainly connected to vertices in other modules are called connector hubs. Provincial and connector hubs may play different functional roles within a network.
- Graph spectral analysis
Graph spectral analysis is an interesting alternative way to characterize the adjacency matrix of a graph and its related Laplacian matrix. The Laplacian matrix contains the node degree as diagonal elements, and -1 for all cells corresponding to existing edges and 0 for cells corresponding to absent edges. If the adjacency and Laplacian matrix are symmetrical, and eigenvalue / eigenvector analysis can be performed, resulting in a series of eigenvalues and corresponding eigenvectors. It is assumed that the series of eigenvalues and eigenvectors represent all information present in the graph. Some graph spectral measures have special significance. The largest eigenvalue of the adjacency matrix is called the spectral radius and is inversely related to the synchronization threshold of dynamical processes on the graph. In addition, the values of its corresponding vector are a measure of centrality. The spectral gap (the difference between the largest and the second largest eigenvalue) provides information on how rapid the synchronous state is reached. The second smallest eigenvalue of the Laplacian matrix is called the algebraic connectivity. It is a measure of network robustness. If the algebraic connectivity is 0, the network consists of at least two disconnected components. The ratio of the largest and the second smallest eigenvalues of the Laplacian matrix is a measure of the stability of the synchronous state of a dynamical process on the network. The information contained in graph spectral analysis can also be used to identify modules within the network.
Models of complex networks
Models are extremely important in modern network theory. It can be argued that the discovery of models for very large networks with a mixture of randomness and order lies at the heart of the transition from conventional graph theory to the modern science of networks. Here we describe three prototype models that illustrate many of the key principles.
- Random graphs
The oldest model of complex networks is that of random graphs as introduced by Rapoport and analyzed in detail by Erdos and Renyi. In a random graph G(V,E) edges between any pair of vertices exist with a probability p. The properties of the random graph have been studies extensively and many important mathematical results have been obtained. For instance, if p is increased from 0 to 1, the size of the largest connected component in the graph will undergo a phase transition at p=0.5. Random graphs have a low clustering coefficient, a small average shortest path length, no assortativity, a narrow degree distribution and not real hubs. While random graphs can explain some properties of real complex networks, notably the short distances between any two nodes, they fail in other respects. In particular, random graphs cannot explain the ubiquitous presence of clustering, modularity and hubs in real networks. Some of these problems were solved by the introduction of more sophisticated models at the end of the nineties in the last century.
- Small-world networks
Watts and Strogatz (1998) considered a network on a ring, where each vertex is connected to k neighbors, k/2 in the clockwise direction, and k/2 counter clockwise. This is an ordered, lattice-like network. It has a high clustering coefficient, a long average shortest path length, no modularity or assortativity, a symmetric degree distribution, and no hubs. Next, with a probability p, edges are disconnected and attached to a randomly chosen other vertex. For p = 1 all edges are reconnected, and a random network is obtained, with all corresponding properties such as low clustering and short path lengths. The interesting region is for intermediate values of p. Even for small but non zero values of p, with only a small fraction of rewired edges, the path length already drops to very low values, while the clustering coefficient still maintains its original high values. This type of network, that combines high clustering with short pathlengths, is called a small-world network. Despite its apparent simplicity it is in fact a very powerful model of many real networks that often display the same combination of high clustering and short pathlengths. However, the Watts and Strogatz (WS) model fails to explain other important properties of natural networks such as modularity and broad degree distributions with hub like nodes. This last problem was solved in another model.
- Scale-free networks
Barabasi and Albert proposed a model of a growing network. At each iteration, a new vertex is added, and it is connected to existing vertices with a probability that depends upon the degree of that node. As a consequence, nodes with a high degree are more likely to receive more connections, increasing their degree even further. This is an example of positive feedback or preferential attachment. The most interesting feature of the model is the shape of its degree distribution. After a sufficient number of iterations the degree distribution becomes a power law: P(k) = kgamma, where gamma = 3. This power law distribution reflects the presence of large number of highly connected nodes or hubs. Networks with a power law degree distribution are referred to as scale-free (SF). In contrast to WS networks, scale-free networks can explain the presence of hubs in networks, and suggest a growth scenario that gives rise to these hubs. For these reasons SF models have become very important in modern network research. However, even SF models have their limitations: they do not explain clustering very well, they are not assortative, and have no real modules.