scikit-learn学习之神经网络算法
本系列博客主要参考 Scikit-Learn 官方网站上的每一个算法进行,并进行部分翻译,如有错误,请大家指正
转载请注明出处,谢谢
======================================================================
scikit-learn博主使用的是0.17版本,是稳定版,当然现在有0.18发行版,两者还是有区别的,感兴趣的可以自己官网上查看
scikit-learn0.17(and 之前)上对于Neural Network算法 的支持仅限于 BernoulliRBM
scikit-learn0.18上对于Neural Network算法有三个 neural_network.BernoulliRBM ,neural_network.MLPClassifier,neural_network.MLPRgression
具体可参考:点击阅读
1:神经网络算法简介
2:Backpropagation算法详细介绍
3:非线性转化方程举例
4:自己实现神经网络算法NeuralNetwork
5:基于NeuralNetwork的XOR实例
6:基于NeuralNetwork的手写数字识别实例
7:scikit-learn中BernoulliRBM使用实例
8:scikit-learn中的手写数字识别实例
一:神经网络算法简介
1:背景
以人脑神经网络为启发,历史上出现过很多版本,但最著名的是backpropagation
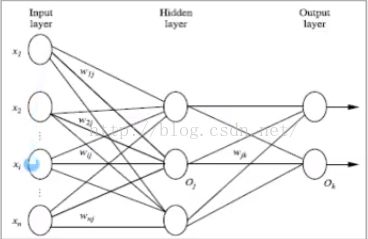
2:多层向前神经网络(Multilayer Feed-Forward Neural Network)

多层向前神经网络组成部分
输入层(input layer),隐藏层(hiddenlayer),输出层(output layer)
3:设计神经网络结构
4:算法验证——交叉验证法(Cross- Validation)
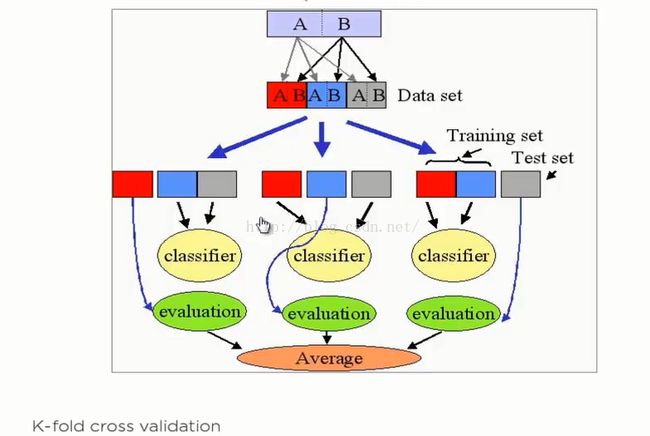
解读: 有一组输入集A,B,可以分成三组,第一次以第一组为训练集,求出一个准确度,第二次以第二组作为训练集,求出一个准确度,求出准确度,第三次以第三组作为训练集,求出一个准确度,然后对三个准确度求平均值
二:Backpropagation算法详细介绍
1:通过迭代性来处理训练集中的实例
2:输入层输入数
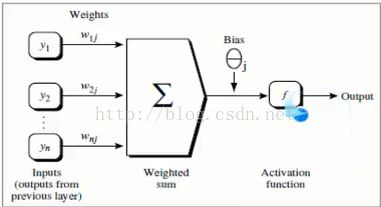
经过权重计算得到第一层的数据,第一层的数据作为第二层的输入,再次经过权重计算得到结果,结果和真实值之间是存在误差的,然后根据误差,反向的更新每两个连接之间的权重
3:算法详细介绍
输入:D : 数据集,| 学习率(learning rate),一个多层前向神经网络
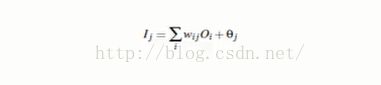
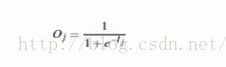
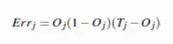 Tj:真实值,Qj表示预测值
Tj:真实值,Qj表示预测值
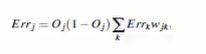 Errk 表示前一层的误差, Wjk表示前一层与当前点的连接权重
Errk 表示前一层的误差, Wjk表示前一层与当前点的连接权重
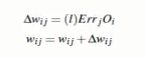 l:指学习比率(变化率),手工指定,优化方法是,随着数据的迭代逐渐减小
l:指学习比率(变化率),手工指定,优化方法是,随着数据的迭代逐渐减小
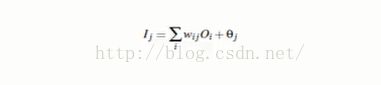 l:同上
l:同上
4:结合实例讲解算法
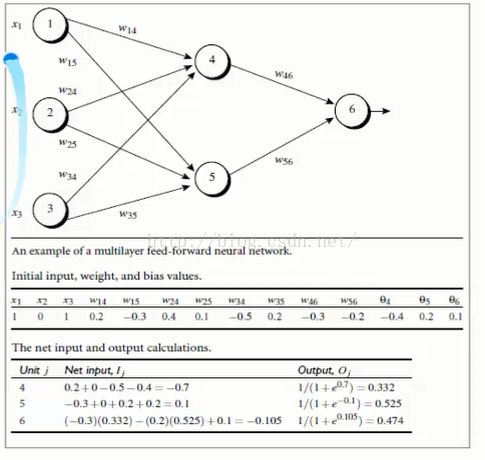

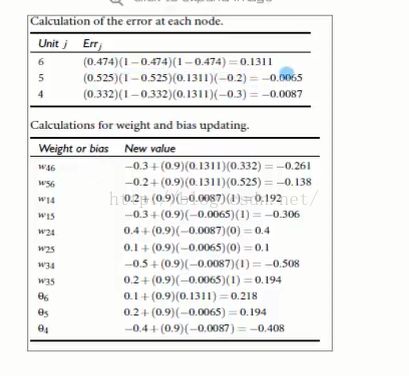
0.9对用的是L,学习率
三:非线性转化方程举例
在二中Activation Function对计算结果进行转换,得到下一层的输入,这里用到的f函数就是非线性转换函数,Sigmoid函数(S曲线)用来做f函数,Sigmoid函数是一类函数,只要S曲线满足一定的性质就可以作为activation Function函数
Sigmoid函数:
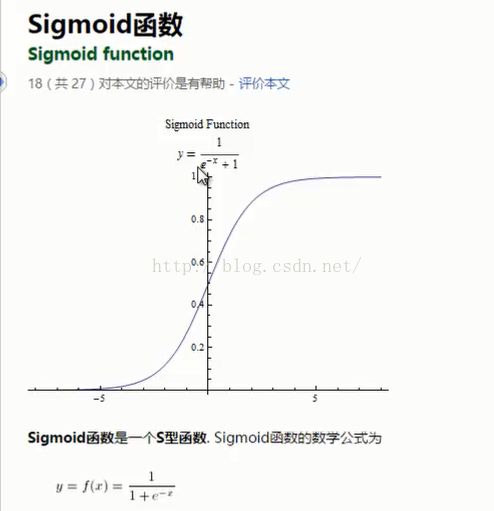
常见的Sigmoid函数
1:双曲函数(参考百科,下面以tan函数为例)

双曲函数的导数为:

2:逻辑函数(Logistic函数)

逻辑函数的导数形式为:

四:自己实现神经网络算法NeuralNetwork
建立NeuralNetwork.py,添加以下代码
#coding:utf-8
'''
Created on 2016/4/27
@author: Gamer Think
'''
import numpy as np
#定义双曲函数和他们的导数
def tanh(x):
return np.tanh(x)
def tanh_deriv(x):
return 1.0 - np.tanh(x)**2
def logistic(x):
return 1/(1 + np.exp(-x))
def logistic_derivative(x):
return logistic(x)*(1-logistic(x))
#定义NeuralNetwork 神经网络算法
class NeuralNetwork:
#初始化,layes表示的是一个list,eg[10,10,3]表示第一层10个神经元,第二层10个神经元,第三层3个神经元
def __init__(self, layers, activation='tanh'):
"""
:param layers: A list containing the number of units in each layer.
Should be at least two values
:param activation: The activation function to be used. Can be
"logistic" or "tanh"
"""
if activation == 'logistic':
self.activation = logistic
self.activation_deriv = logistic_derivative
elif activation == 'tanh':
self.activation = tanh
self.activation_deriv = tanh_deriv
self.weights = []
#循环从1开始,相当于以第二层为基准,进行权重的初始化
for i in range(1, len(layers) - 1):
#对当前神经节点的前驱赋值
self.weights.append((2*np.random.random((layers[i - 1] + 1, layers[i] + 1))-1)*0.25)
#对当前神经节点的后继赋值
self.weights.append((2*np.random.random((layers[i] + 1, layers[i + 1]))-1)*0.25)
#训练函数 ,X矩阵,每行是一个实例 ,y是每个实例对应的结果,learning_rate 学习率,
# epochs,表示抽样的方法对神经网络进行更新的最大次数
def fit(self, X, y, learning_rate=0.2, epochs=10000):
X = np.atleast_2d(X) #确定X至少是二维的数据
temp = np.ones([X.shape[0], X.shape[1]+1]) #初始化矩阵
temp[:, 0:-1] = X # adding the bias unit to the input layer
X = temp
y = np.array(y) #把list转换成array的形式
for k in range(epochs):
#随机选取一行,对神经网络进行更新
i = np.random.randint(X.shape[0])
a = [X[i]]
#完成所有正向的更新
for l in range(len(self.weights)):
a.append(self.activation(np.dot(a[l], self.weights[l])))
#
error = y[i] - a[-1]
deltas = [error * self.activation_deriv(a[-1])]
#开始反向计算误差,更新权重
for l in range(len(a) - 2, 0, -1): # we need to begin at the second to last layer
deltas.append(deltas[-1].dot(self.weights[l].T)*self.activation_deriv(a[l]))
deltas.reverse()
for i in range(len(self.weights)):
layer = np.atleast_2d(a[i])
delta = np.atleast_2d(deltas[i])
self.weights[i] += learning_rate * layer.T.dot(delta)
#预测函数
def predict(self, x):
x = np.array(x)
temp = np.ones(x.shape[0]+1)
temp[0:-1] = x
a = temp
for l in range(0, len(self.weights)):
a = self.activation(np.dot(a, self.weights[l]))
return a
五:基于NeuralNetwork的XOR(异或)示例
代码如下:
#coding:utf-8
'''
Created on 2016/4/27
@author: Gamer Think
'''
import numpy as np
from NeuralNetwork import NeuralNetwork
'''
[2,2,1]
第一个2:表示 数据的纬度,因为是二维的,表示两个神经元,所以是2
第二个2:隐藏层数据纬度也是2,表示两个神经元
1:表示输入为一个神经元
tanh:表示用双曲函数里的tanh函数
'''
nn = NeuralNetwork([2,2,1], 'tanh')
X = np.array([[0, 0], [0, 1], [1, 0], [1, 1]])
y = np.array([0, 1, 1, 0])
nn.fit(X, y)
for i in [[0, 0], [0, 1], [1, 0], [1,1]]:
print(i,nn.predict(i)) ([0, 0], array([ 0.02150876]))
([0, 1], array([ 0.99857695]))
([1, 0], array([ 0.99859837]))
([1, 1], array([ 0.04854689]))
六:基于NeuralNetwork的手写数字识别示例
代码如下:
import numpy as np
from sklearn.datasets import load_digits
from sklearn.metrics import confusion_matrix,classification_report
from sklearn.preprocessing import LabelBinarizer
from sklearn.cross_validation import train_test_split
from NeuralNetwork import NeuralNetwork
digits = load_digits()
X = digits.data
y = digits.target
X -= X.min()
X /= X.max()
nn =NeuralNetwork([64,100,10],'logistic')
X_train, X_test, y_train, y_test = train_test_split(X, y)
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
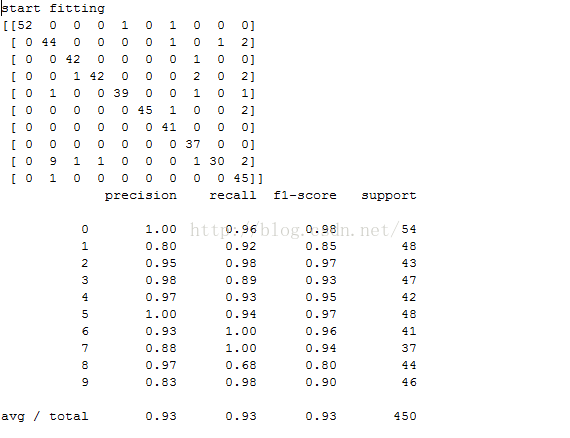
print "start fitting"
nn.fit(X_train,labels_train,epochs=3000)
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i])
predictions.append(np.argmax(o))
print confusion_matrix(y_test, predictions)
print classification_report(y_test, predictions) 输出结果:
七:scikit-learn中的BernoulliRBM使用实例
from sklearn.neural_network import BernoulliRBM
X = [[0,0],[1,1]]
y = [0,1]
clf = BernoulliRBM().fit(X,y)
print clf输出结果为:
BernoulliRBM(batch_size=10, learning_rate=0.1, n_components=256, n_iter=10,
random_state=None, verbose=0)
注意此模块不支持predict函数,这与以往的算法有很大的不同
八:scikit-learn中的手写数字识别实例
import numpy as np
import matplotlib.pyplot as plt
from scipy.ndimage import convolve
from sklearn import linear_model, datasets, metrics
from sklearn.cross_validation import train_test_split
from sklearn.neural_network import BernoulliRBM
from sklearn.pipeline import Pipeline
###############################################################################
# Setting up
def nudge_dataset(X, Y):
"""
This produces a dataset 5 times bigger than the original one,
by moving the 8x8 images in X around by 1px to left, right, down, up
"""
direction_vectors = [
[[0, 1, 0],
[0, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[1, 0, 0],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 1],
[0, 0, 0]],
[[0, 0, 0],
[0, 0, 0],
[0, 1, 0]]]
shift = lambda x, w: convolve(x.reshape((8, 8)), mode='constant',
weights=w).ravel()
X = np.concatenate([X] +
[np.apply_along_axis(shift, 1, X, vector)
for vector in direction_vectors])
Y = np.concatenate([Y for _ in range(5)], axis=0)
return X, Y
# Load Data
digits = datasets.load_digits()
X = np.asarray(digits.data, 'float32')
X, Y = nudge_dataset(X, digits.target)
X = (X - np.min(X, 0)) / (np.max(X, 0) + 0.0001) # 0-1 scaling
X_train, X_test, Y_train, Y_test = train_test_split(X, Y,
test_size=0.2,
random_state=0)
# Models we will use
logistic = linear_model.LogisticRegression()
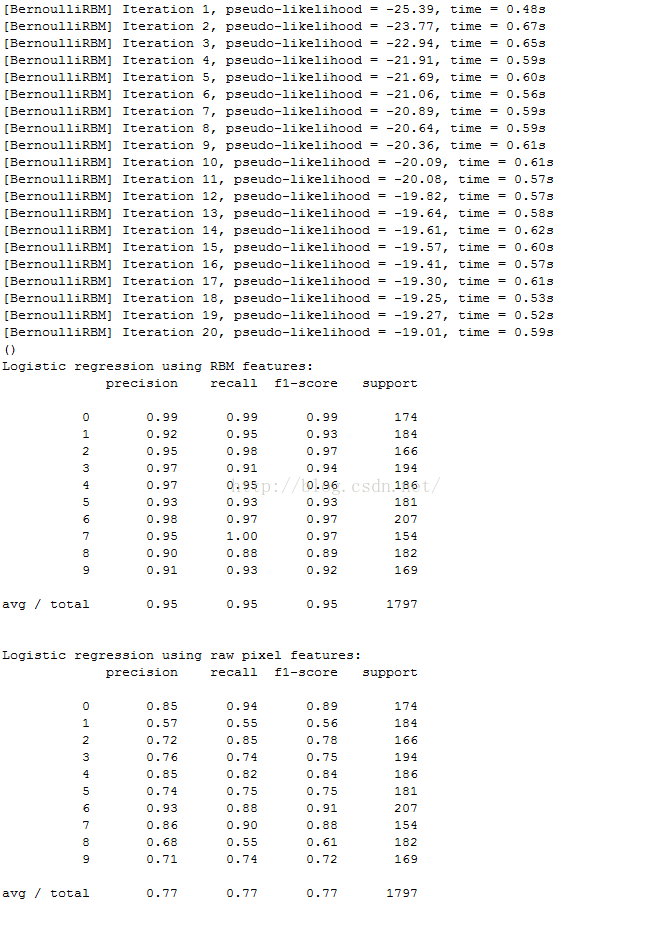
rbm = BernoulliRBM(random_state=0, verbose=True)
classifier = Pipeline(steps=[('rbm', rbm), ('logistic', logistic)])
###############################################################################
# Training
# Hyper-parameters. These were set by cross-validation,
# using a GridSearchCV. Here we are not performing cross-validation to
# save time.
rbm.learning_rate = 0.06
rbm.n_iter = 20
# More components tend to give better prediction performance, but larger
# fitting time
rbm.n_components = 100
logistic.C = 6000.0
# Training RBM-Logistic Pipeline
classifier.fit(X_train, Y_train)
# Training Logistic regression
logistic_classifier = linear_model.LogisticRegression(C=100.0)
logistic_classifier.fit(X_train, Y_train)
###############################################################################
# Evaluation
print()
print("Logistic regression using RBM features:\n%s\n" % (
metrics.classification_report(
Y_test,
classifier.predict(X_test))))
print("Logistic regression using raw pixel features:\n%s\n" % (
metrics.classification_report(
Y_test,
logistic_classifier.predict(X_test))))
###############################################################################
# Plotting
plt.figure(figsize=(4.2, 4))
for i, comp in enumerate(rbm.components_):
plt.subplot(10, 10, i + 1)
plt.imshow(comp.reshape((8, 8)), cmap=plt.cm.gray_r,
interpolation='nearest')
plt.xticks(())
plt.yticks(())
plt.suptitle('100 components extracted by RBM', fontsize=16)
plt.subplots_adjust(0.08, 0.02, 0.92, 0.85, 0.08, 0.23)
plt.show()显示结果:

附:博主对于前边的原理其实很是明白了,但是对于scikit-learn实现手写数字识别系统这个代码优点迷乱,如果路过大神明白的,可以给小弟指点迷津
import numpy as np
from sklearn.datasets import load_digits
from sklearn.metrics import confusion_matrix,classification_report
from sklearn.preprocessing import LabelBinarizer
from sklearn.cross_validation import train_test_split
from NeuralNetwork import NeuralNetwork
digits = load_digits()
X = digits.data
y = digits.target
X -= X.min()
X /= X.max()
nn =NeuralNetwork([64,100,10],'logistic')
X_train, X_test, y_train, y_test = train_test_split(X, y)
labels_train = LabelBinarizer().fit_transform(y_train)
labels_test = LabelBinarizer().fit_transform(y_test)
print "start fitting"
nn.fit(X_train,labels_train,epochs=3000)
predictions = []
for i in range(X_test.shape[0]):
o = nn.predict(X_test[i])
predictions.append(np.argmax(o))
print confusion_matrix(y_test, predictions)
print classification_report(y_test, predictions)