大数据学习之 Hive篇
一 :Hive是什么?
1. hive 是一个sql解析引擎,将sql语句转移成Mapreduce 然后在hadoop平台上运行,达到快速开发的目的
2.hive中的表是纯逻辑表,就只是表的定义等,即表的元数据,本质就是hadoop的目录、文件
达到元数据与数据存储分离的目的
3.hive本身不存储数据,完全依赖HDFS和MapReduce
4.hive的内容是读多写少,不支持对数据的改写和删除
5.hive中没有定义专门的数据格式,由用户指定,需要指定三个属性“
--列分隔符 空格 ; "," ; "\t"
--行分隔符 "\n"
--读取文件数据的方法
二:导入本地local的数据到hive表中
load data local inpath '/home/Documents/code/mr/The_man_of_property.txt'
into table article;
1.创建表
create table orders(
order_id string,
user_id string,
eval_set string,
order_number string,
order_dow string,
order_hour_of_day string,
days_since_prior_order string
)row format delimited fields terminated by ',';
2.导入数据
load data local inpath
'/home/data/orders.csv'
into table orders;
3 建表article
create table article(sentence string)
row format delimited fields terminated by '\n'; (设置分隔符)
导入本地local的数据到hive表中
load data local inpath '/home/badou/Documents/code/mr/The_man_of_property.txt'
into table article;
---查看表结构
desc article
--一句话:the heroic and that there is little heroism in these pages
--['the','heroic','and','that',there is little heroism in these pages]
-- 将一句话通过空格提取单词,然后一句话一行转变成每个单词一行
select
explode(split(sentence, ' ')) as word
from article
--单独对hive函数测试:
select split('the heroic and that there',' ');
--返回结果:["the","heroic","and","that","there"]
select explode(split('the heroic and that there',' '));
--返回结果:
--the
--heroic
--and
--that
--there
select word,count(1) as cnt
from
(
select
explode(split(sentence, ' ')) as word
from article
)t
group by word
limit 100;
--正则
select regexp_extract('(mentioned','[[\\w]]+',0);
select regexp_extract('(mentioned','[[0-9a-zA-Z]]+',0);
-- 正则应用
-- 没有加order by: 一个mapreduce
-- +order by:2个mapreduce
select
regexp_extract(word,'[[0-9a-zA-Z]]+',0) as word,
count(1) as cnt
from
(
select
explode(split(sentence, ' ')) as word
from article
)t
group by regexp_extract(word,'[[0-9a-zA-Z]]+',0)
order by cnt desc
limit 100;
--desc加上了表示降序,没加表示正常升序排列
--split 吧sentence 以空格拆分,生成一个是数组的单词
--expload 把数据里面的每一个参数都生成一列
-- jieba中文切词 ES(ik),hanlp
-- 加上 了 表示 降序 pyspark,scala spark udf
--分区表,partition,hive表名/子文件夹
根据日期做partition,每天一个partition,这一天所有的数据都放到对应日期的文件夹中。dt(date)子文件夹名字:dt=20190421
--对于查询效率上分区表更快:
--1.所有数据都放到一个表的文件夹中查询数据需要遍历(扫一遍所有数据),如果这个文件夹中的数据包含了一年的用户行为数据。这样扫一遍数据就扫一年所有的数据。
--2.如果做了分区,想要获取分析昨天的数据,只需要取对应昨天日期的文件夹中的数据即可。只需用找到对应日期的文件夹就行。具体限定约束条件在where后面: select userid from table where dt='20190420'
-- dt是其中表中的一个日期的字段名(列名),客户端:pc,m,app
-- 建内部表article
create table article(sentence string)
row format delimited fields terminated by '\n';
load data local inpath '/home/badou/Documents/code/mr/The_man_of_property.txt'
into table article;
建立内部表 和外部表的区别:内部表数据由Hive自身管理,外部表数据由HDFS管理,外部表删除表仅仅删除hive中元数据不删除数据和指定的路径,内部表如果drop掉表,数据和默认路径都删除了。
内部转外部 alter table tableA set TBLPROPERTIES('EXTERNAL'='true') 外部转内部 alter table tableA set TBLPROPERTIES('EXTERNAL'='false')
--建立外部表:
create external table art_ext(sentence string)
row format delimited fields terminated by '\n'
--stored as textfile
location '/data/ext';
--select查看数据的时候会打印对应的表头:
set hive.cli.print.header=ture;
-- partition
--1. 创建分区表
create table art_dt(sentence string)
partitioned by (dt string)
row format delimited fields terminated by '\n';
--2. 然后插入数据
insert overwrite table art_dt partition(dt='20190420')
select * from art_ext limit 100;
insert overwrite table art_dt partition(dt='20190421')
select * from art_ext limit 100;--sql做数据的etl,或者统计分析等的处理逻辑
--查看分区数
show partitions art_dt;
--hive任务一般是凌晨定时任务,比如凌晨一点执行这个sql(逻辑:统计分析,etl),跑昨天一天的数据,(昨天以及昨天之前的数据)写入对应昨天日期的文件夹中。离线表T+1。
--bucket:需要查询当前已经在hive中的表的数据进行分桶的。
--1.生成辅助表
create table bucket_num(num int);
load data local inpath '/home/badou/Documents/data/hive/bucket_test.txt'
into table bucket_num;
--2.每个数字进入一个bucket
--2.1建表(表的元数据信息建立)
set hive.enforce.bucketing = true;
create table bucket_test(num int)
clustered by(num)
into 32 buckets;
--2.2查询数据并导入到对应表中
-- number of mappers: 1; number of reducers: 32
insert overwrite table bucket_test
select cast(num as int) as num from bucket_num
--sample
select * from bucket_test tablesample(bucket 1 out of 32 on num);
--第一个bucket,00_0,32
select * from bucket_test tablesample(bucket 1 out of 16 on num);
--第1个和第17个bucket:00_0和16_0, 32和16
--测试1/2个bucket:
set hive.enforce.bucketing = true;
create table bucket_test4(num int)
clustered by(num)
into 4 buckets;
insert overwrite table bucket_test4
select num from bucket_num;
select * from bucket_test4 tablesample(bucket 1 out of 8 on num);
--数据没有分桶,怎么采样数据?
select * from bucket_test4 where num%10>0;
--orders:订单数据表
order_id,user_id,eval_set,order_number,order_dow,order_hour_of_day,days_since_prior_order
2539329,1,prior,1,2,08,
2398795,1,prior,2,3,07,15.0
473747,1,prior,3,3,12,21.0
2254736,1,prior,4,4,07,29.0
431534,1,prior,5,4,15,28.0
3367565,1,prior,6,2,07,19.0
550135,1,prior,7,1,09,20.0
order_id,订单编号
user_id,用户id
eval_set,标识订单数据是否为历史数据
order_number,用户购买订单的编号,按照用户购买的先后顺序编号的
order_dow,dow(day of week)星期几(0-6)
order_hour_of_day,一天中哪一个小时产生的订单
days_since_prior_order 下一个订单距离上一个订单经历的天数
--1.创建表
create table orders(
order_id string,
user_id string,
eval_set string,
order_number string,
order_dow string,
order_hour_of_day string,
days_since_prior_order string
)row format delimited fields terminated by ',';
--2.导入数据
load data local inpath
'/home/badou/Documents/data/order_data/orders.csv'
into table orders;
--看看星期是否为0-6:
select order_dow,count(1) as cnt
from orders
group by order_dow
select distinct(order_hour_of_day) from orders;
--hdfs备份改成1,避免以后使用磁盘不足
--hadoop的配置目录:/usr/local/src/hadoop-2.6.1/etc/hadoop
--hdfs的配置文件:hdfs-site.xml
--
--
--order_products_prior
order_id,product_id,add_to_cart_order,reordered
2,33120,1,1
2,28985,2,1
2,9327,3,0
2,45918,4,1
2,30035,5,0
2,17794,6,1
order_id,订单id
product_id,商品id
add_to_cart_order,加购物车的位置
reordered当前商品是否为重复下单的行为
-- 统计每个用户购买过多少个商品
-- 1.每个订单有多少商品
select order_id,count(1) as prod_cnt
from order_products_prior
group by order_id
order by prod_cnt desc
limit 10;
-- 2.每个用户下过的订单对应商品数量求和起来
order_id,user_id --orders
order_id,prod_cnt -- t2
--根据order_id join:把一个订单中多少个商品的数据带入到有用户user_id
--这个表中。只需要再对这个用户所有订单的商品求和就可以得到一个用户具体购买了多少个商品。
select
t1.user_id as user_id,
sum(t2.prod_cnt) as prod_sum
from orders t1
join
(
select order_id,count(1) as prod_cnt
from order_products_prior
group by order_id
)t2
on (t1.order_id=t2.order_id)
group by t1.user_id
order by prod_sum desc
limit 10;
--笛卡尔积
select t1.user_id as u1,t2.user_id as u2
from
(select user_id from dc)t1
join
(select user_id from dc)t2
--join过程没有on条件
补充:
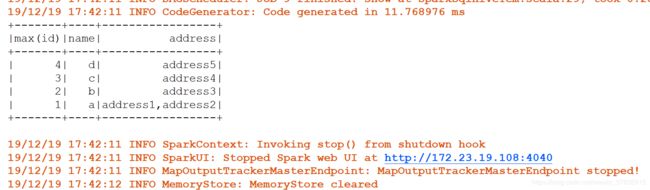
select max(ubi.id), ubi.name, concat_ws(',', collect_set(ua.address)) as address
from user_basic_info ubi
join user_address ua
on ubi.name=ua.name group by ubi.name;
作用:把两张表合并 例如
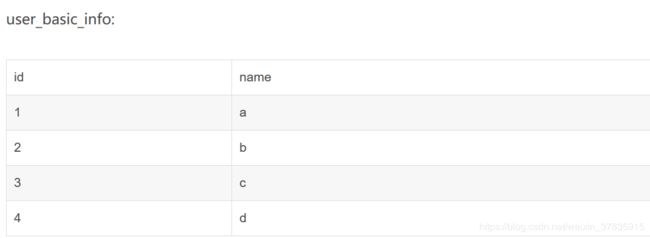
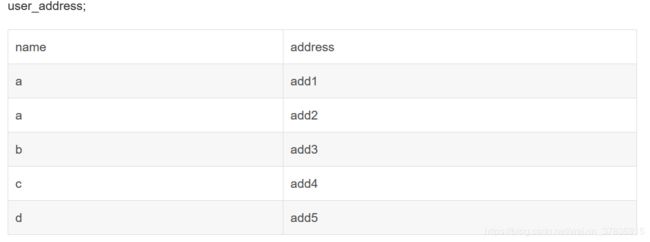
合并成:
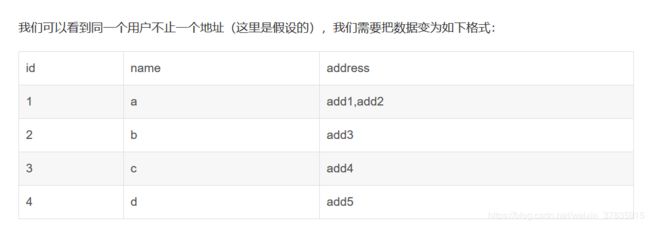
完整代码如下
package com.spark.self
import org.apache.spark.sql.SparkSession
object SparkSqlHiveTem {
def main(args: Array[String]): Unit = {
val warehouseLocation = "C:/hnn/Project/Self/spark/spark-warehouse"
val spark = SparkSession
.builder()
.appName("Spark Hive Example")
.config("spark.sql.warehouse.dir", warehouseLocation)
.master("local[*]")
.enableHiveSupport()
.getOrCreate()
import spark.sql
sql("CREATE TABLE IF NOT EXISTS user_basic_info (id INT, name STRING)")
sql("LOAD DATA LOCAL INPATH 'in/user_basic_info.txt' INTO TABLE user_basic_info")
sql("SELECT * FROM user_basic_info").show()
sql("CREATE TABLE IF NOT EXISTS user_address (name STRING,address STRING)")
sql("LOAD DATA LOCAL INPATH 'in/user_address.txt' INTO TABLE user_address")
sql("SELECT * FROM user_address").show()
sql("select max(ubi.id), ubi.name," +
" concat_ws(',', collect_set(ua.address)) as address " +
"from user_basic_info ubi " +
"join user_address ua " +
"on ubi.name=ua.name " +
"group by ubi.name").show()
}
}
运行结果如下: