import tensorflow as tf
from tensorflow import keras
import numpy as np
print(tf.__version__)
boston_housing=keras.datasets.boston_housing
(train_data,train_labels),(test_data,test_labels)=boston_housing.load_data()
#shuffle the training set
order = np.argsort(np.random.random(train_labels.shape))
train_data = train_data[order]
train_labels=train_labels[order]
print("Training set:{}".format(train_data.shape))
print("Testing set:{}".format(test_data.shape))
1.8.0
Training set:(404, 13)
Testing set:(102, 13)
import pandas as pd
column_names = ['CRIM', 'ZN', 'INDUS', 'CHAS', 'NOX', 'RM', 'AGE', 'DIS', 'RAD',
'TAX', 'PTRATIO', 'B', 'LSTAT']
df = pd.DataFrame(train_data,columns=column_names)#列的标号,行的标号为index,不是rows
df.head()

mean = np.mean(train_data,axis=0)#按行求均值:这里按行的意思是对应某一列的和求均值
std = np.std(train_data,axis=0)
train_data=(train_data-mean)/std
test_data=(test_data-mean)/std#注意测试数据集也是减训练数据集的均值,也就是说默认测试数据集分步与训练集一致
#Models、Layers、Initializations、Activations、Objectives、Optimizers、Preprocessing、#metrics
#目前使用的都是序贯模型,是函数模型的特例
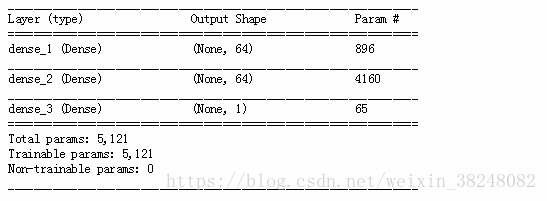
def build_model():
model=keras.Sequential([
keras.layers.Dense(64,activation=tf.nn.relu,input_shape=(train_data.shape[1],)),
keras.layers.Dense(64,activation=tf.nn.relu),
keras.layers.Dense(1)
])
optimizer=tf.train.RMSPropOptimizer(0.001)
#compile配置训练模型,比如损失函数,优化器,评价指标等
model.compile(loss='mse',
optimizer=optimizer,
metrics=['mae'])#mean absolute error
return model
model = build_model()
model.summary()#显示模型概况
class PrintDot(keras.callbacks.Callback):
def on_epoch_end(self,epoch,logs):
if epoch%100==0:
print('')
print('.',end='')
EPOCHS=500
history = model.fit(train_data,train_labels,epochs=EPOCHS,validation_split=0.2,
verbose=0,callbacks=[PrintDot()])
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
....................................................................................................
import matplotlib.pyplot as plt
def plot_history(history):
plt.figure()
plt.xlabel('Epoch')
plt.ylabel('Mean Abs Error [1000$]')
plt.plot(history.epoch,np.array(history.history['mean_absolute_error']),
label='Train Loss')
plt.plot(history.epoch,np.array(history.history['val_mean_absolute_error']),
label='Train Loss')
plt.legend()#图例
plt.ylim([0,5])#设置坐标范围,limit
plt.show()
model=build_model()
early_stop=keras.callbacks.EarlyStopping(monitor='val_loss',patience=20)
#monitor:acc,loss,val_acc,val_loss
#min_delta: minimum change in the monitored quantity to qualify as an improvement
#patience: 容忍度,比如本实验容忍20epochs没有变化(提升或者下降),则训练停止
#mode:auto,min,max, min意味着误差下降停止训练,max,意味着正确率停止增加则停止训练
history = model.fit(train_data,train_labels,epochs=EPOCHS,
validation_split=0.2,verbose=0,
callbacks=[early_stop,PrintDot()])
plot_history(history)

[loss,mae]=model.evaluate(test_data,test_labels,verbose=1)
print("Testing set Mean Abs Error: ${:7.2f}".format(mae * 1000))
102/102 [==============================] - 0s 202us/step
Testing set Mean Abs Error: $2632.74
test_predictions = model.predict(test_data).flatten()
plt.scatter(test_labels,test_predictions)
plt.xlabel('True Values [1000$]')
plt.ylabel('Predictions [1000$]')
plt.axis('equal')#设置坐标轴参数,‘equal’表示x轴与y轴相等
print(plt.xlim())
plt.xlim(plt.xlim())#有点自动限制坐标适合图的意味
plt.ylim(plt.ylim())
plt.plot([-100,100],[-100,100])#画线条,范围是[-100,100],[-100,100]
plt.show()

error = test_predictions-test_labels
plt.hist(error,bins=50)
plt.xlabel('Prediction Error [1000$]')
plt.ylabel('Count')
plt.show()
