house price predict
波士顿房价这个项目是我自己在kaggle上做的第二个项目了,第一次自己做只达到前50%,之后看了kaggle上一位大神的思路,对自己的项目进行了改善,例如结合多个基本模型进行预测,果然误差率降低了很多,排名达到前20%,果然跟着大神走不会错。这里只做一个个人的学习总结,之后也会不断再完善。
先说下我的思路:
1. 导入数据
2. 数据处理:
——outliers 关于outliers的处理,应该仔细阅读数据描述,里面有很多关于竞赛的要求。
——目标变量 观察目标变量的分布情况,对于连续型变量
——Feature Engineering ——填补缺失值
——转化变量
——LabelEncoding 变量
——降维
——特征变量偏斜度
3. 建模
——基本模型
——打分
——叠加基本模型
——预测
4. 导出并提交
接下来看具体怎么做:
1. 导入数据并查看数据
train=pd.read_csv('houseprice/train.csv')
test=pd.read_csv('houseprice/test.csv')train.head(5)test.head(5)
2. 数据处理
outliers:
当我阅读kaggle的overview时,发现在description中的Acknowledgment中有个The Ames Housing dataset 的详细介绍,仔细阅读发现在文档中有outliers的线索,所以下一步就是按照文档中要求的,处理outliers。
先plot一遍GrLivArea与SalePrice之间的图像,观察有哪些点属于outliers:
fig,ax=plt.subplots()
ax.scatter(x=train['GrLivArea'],y=train['SalePrice'])
plt.xlabel('GrLivArea',fontsize=15)
plt.ylabel('SalePrice',fontsize=15)
plt.show()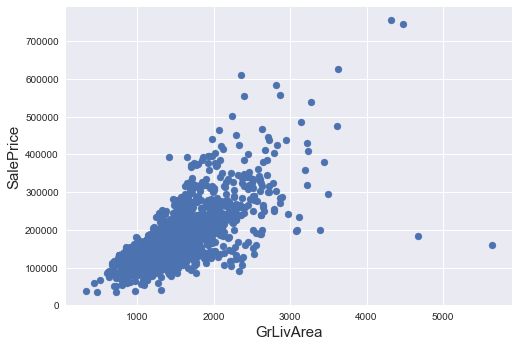
通过阅读The Ames Housing dataset 知道应该去除GrLivArea<4000的四个outliers,但我觉得有些大房子确实挺贵,所以像SalePrice>700000的outliers我还是保留下来了。
train=train.drop(train[(train['GrLivArea']>4000)&(train['SalePrice']<300000)].index)再plot一遍:
fig,ax=plt.subplots()
ax.scatter(x=train['GrLivArea'],y=train['SalePrice'])
plt.xlabel('GrLivArea',fontsize=15)
plt.ylabel('SalePrice',fontsize=15)
plt.show()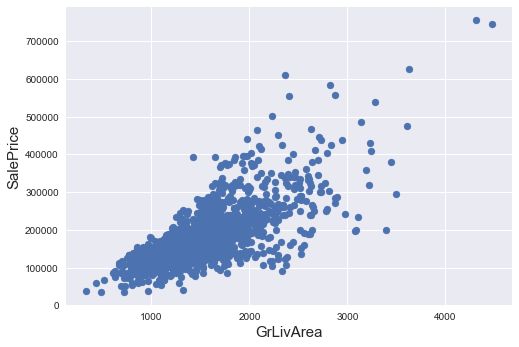
OK,outliers处理完毕。接下来处理目标变量。
目标变量:
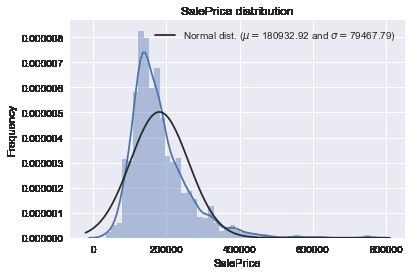
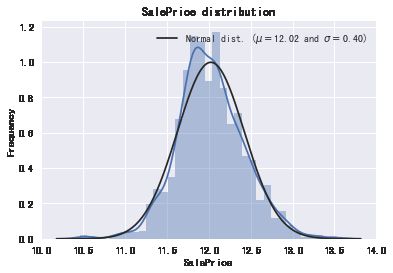
先plot出房价的分布发现房价呈右偏态分布:
sns.distplot(train['SalePrice'],fit=norm)
(mu,sigma)=norm.fit(train['SalePrice'])
print('\n mu={:.2f} and sigma={:.2f}\n'.format(mu,sigma))
plt.legend(['Normal dist. ($\mu=${:.2f} and $\sigma=${:.2f})'.format(mu,sigma)],loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')![]()
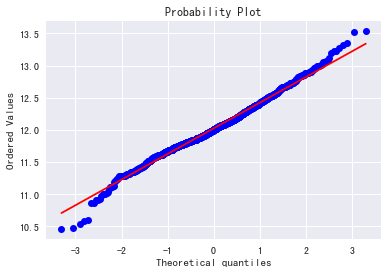
用分位数图看的更明显点:
fig=plt.figure()
res=stats.probplot(train['SalePrice'],plot=plt)
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.ylabel('经验分位点')
plt.xlabel('理论分位点')
plt.show()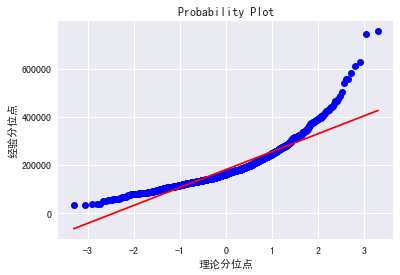
接下来我们在用log处理下salePrice,使它尽可能靠近正态分布。
train['SalePrice']=np.log1p(train['SalePrice'])sns.distplot(train['SalePrice'],fit=norm)
(mu,sigma)=norm.fit(train['SalePrice'])
print('\n mu={:.2f} and sigma={:.2f}\n'.format(mu,sigma))
plt.legend(['Normal dist. ($\mu=${:.2f} and $\sigma=${:.2f})'.format(mu,sigma)],loc='best')
plt.ylabel('Frequency')
plt.title('SalePrice distribution')
fig=plt.figure()
res=stats.probplot(train['SalePrice'],plot=plt)
plt.show()![]()
关联下两个表格接下来要开始特征工程了。
特征工程:
all_data_na=(all_data.isnull().sum()/len(all_data))*100
all_data_na=all_data_na.drop(all_data_na[all_data_na==0].index).sort_values(ascending=False)
missing_data=pd.DataFrame({'Missing Ratio':all_data_na})
missing_data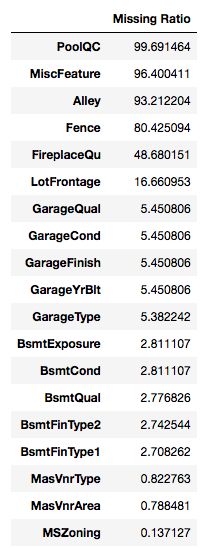
根据不同的变量进行不同的填充null值:
for col in ('GarageType', 'GarageFinish', 'GarageQual', 'GarageCond','PoolQC','MiscFeature','Alley','Fence',
'FireplaceQu','BsmtExposure','BsmtCond','BsmtQual','BsmtFinType2','BsmtFinType1','MasVnrType'):
all_data[col] = all_data[col].fillna('None')#按照地区分组,用每个地区的中位数填充null值
all_data['LotFrontage']=all_data.groupby('Neighborhood')['LotFrontage'].transform(lambda x: x.fillna(x.median()))for col in ('GarageYrBlt', 'GarageArea', 'GarageCars','BsmtFinSF1', 'BsmtFinSF2', 'BsmtUnfSF',
'TotalBsmtSF', 'BsmtFullBath', 'BsmtHalfBath','MasVnrArea',):
all_data[col] = all_data[col].fillna(0)对于这个特征,其具体值除了一个“NoSeWa”和2个NA之外,所有记录都是“AllPub”,因为认为它对SalePrice影响不大,所以删掉。
all_data = all_data.drop(['Utilities'], axis=1)对于一下这些变量采取众数填充:
all_data['Electrical'] = all_data['Electrical'].fillna(all_data['Electrical'].mode()[0])
all_data['KitchenQual'] = all_data['KitchenQual'].fillna(all_data['KitchenQual'].mode()[0])
all_data['Exterior1st'] = all_data['Exterior1st'].fillna(all_data['Exterior1st'].mode()[0])
all_data['Exterior2nd'] = all_data['Exterior2nd'].fillna(all_data['Exterior2nd'].mode()[0])
all_data['SaleType'] = all_data['SaleType'].fillna(all_data['SaleType'].mode()[0])
all_data['MSZoning'] = all_data['MSZoning'].fillna(all_data['MSZoning'].mode()[0])all_data["Functional"] = all_data["Functional"].fillna("Typ")最后再检查一遍是否还有缺失值:

从特征中提取特征:
先观察是否有要转化类型的特征,例如以下我把一些用数字表示的评估质量等级,以及年份月份都转化成了字符串类型:
all_data['MSSubClass'] = all_data['MSSubClass'].astype(str)
all_data['OverallCond'] = all_data['OverallCond'].astype(str)
all_data['OverallQual'] = all_data['OverallQual'].astype(str)
all_data['YrSold'] = all_data['YrSold'].astype(str)
all_data['MoSold'] = all_data['MoSold'].astype(str)
all_data['GarageYrBlt'] = all_data['GarageYrBlt'].astype(str)
all_data['YearBuilt'] = all_data['YearBuilt'].astype(str)
all_data['YearRemodAdd'] = all_data['YearRemodAdd'].astype(str)然后选取一些可能对房价有影响的字符串类型特征变量,对他们进行labelencoder编码:
from sklearn.preprocessing import LabelEncoder
col=('FireplaceQu', 'BsmtQual', 'BsmtCond', 'GarageQual', 'GarageCond',
'ExterQual', 'ExterCond','HeatingQC', 'PoolQC', 'KitchenQual', 'BsmtFinType1',
'BsmtFinType2', 'Functional', 'Fence', 'BsmtExposure', 'GarageFinish', 'LandSlope',
'LotShape', 'PavedDrive', 'Street', 'Alley', 'CentralAir', 'MSSubClass',
'OverallCond', 'YrSold', 'MoSold','YearBuilt','YearRemodAdd')
for c in col:
lb=LabelEncoder()
lb.fit(all_data[c])
all_data[c]=lb.transform(all_data[c])对一些变量进行类似变量进行降维:
all_data['TotalSF'] = all_data['TotalBsmtSF'] + all_data['1stFlrSF'] + all_data['2ndFlrSF']好了,特征变量都清洗完毕,接下来看下特征变量的分布特征:
这里我用偏斜度来查看特征变量的分布情况(偏斜度绝对值越大,说明变量越偏离正态分布,与房价的线性关系越稀疏。)
numeric_feats = all_data.dtypes[all_data.dtypes != "object"].index
skewed_feats=all_data[numeric_feats].apply(lambda x: skew (x.dropna())).sort_values(ascending=False)
print("\n所有数值型变量的偏斜度:\n")
skewness = pd.DataFrame({'Skew' :skewed_feats})
skewness.head(10)

对于偏斜度绝对值较大(>0.75)的变量进行box-cox转换,从而减小最小二乘系数估计带来的误差;使不符合正态分布的变量更符合正态分布,降低伪拟合的概率:
skewness=skewness[abs(skewness)>0.75]
print("有 {} 个变量需要进行box-cox转换".format(skewness.shape[0]))![]()
from scipy.special import boxcox1p
skewed_feat=skewness.index
lam=0.15
for feat in skewed_feat:
all_data[feat]=boxcox1p(all_data[feat],lam)然后应用到full_data:
all_data = pd.get_dummies(all_data)all_data.head()
特征变量处理完毕,对full_data进行拆分:
train = all_data[:1458]
test = all_data[1459:]开始建模:
为了模型最后的误差尽量小,我用了多种模型来预测,最后参考了kaggle上一个大神自己封装的模型叠加函数,将我使用的模型综合叠加,得出最后的误差率。
from sklearn.linear_model import ElasticNet, Lasso
from sklearn.ensemble import RandomForestRegressor, GradientBoostingRegressor
from sklearn.kernel_ridge import KernelRidge
from sklearn.pipeline import make_pipeline
from sklearn.preprocessing import RobustScaler
from sklearn.base import BaseEstimator, TransformerMixin, RegressorMixin, clone
from sklearn.model_selection import KFold, cross_val_score
from sklearn.metrics import mean_squared_error#采用kfold拆分法进行交叉检验,建立打分系统,命名为rmsle_cv
n_folds = 5
def rmsle_cv(model):
kf = KFold(n_folds, shuffle=True, random_state=42)
kf = kf.get_n_splits(train.values)
rmse= np.sqrt(-cross_val_score(model, train.values, y_train, scoring="neg_mean_squared_error", cv = kf))
return(rmse)#rf=make_pipeline(RobustScaler(),RandomForestRegressor(n_estimators=1000,max_features='sqrt',random_state=3))
#score=rmsle_cv(rf)
#print("\nRandomForestRegressor score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
#在前期数据处理时有些outliers的变量,所以这里使用RobustScaler对结果进行处理
lasso = make_pipeline(RobustScaler(), Lasso(alpha =0.0005, random_state=1))
score = rmsle_cv(lasso)
print("\nLasso score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))
ENet = make_pipeline(RobustScaler(), ElasticNet(alpha=0.0005, l1_ratio=.7, random_state=3))
score = rmsle_cv(ENet)
print("ElasticNet score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))![]()
KRR = KernelRidge(alpha=0.6, kernel='polynomial', degree=2, coef0=2.5)
score = rmsle_cv(KRR)
print("Kernel Ridge score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))![]()
GBoost = GradientBoostingRegressor(n_estimators=1000, learning_rate=0.05,
max_depth=4, max_features='sqrt',
min_samples_leaf=15, min_samples_split=10,
loss='huber', random_state =5)
score = rmsle_cv(GBoost)
print("Gradient Boosting score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))![]()
Gboost的参数配置根据自己的电脑性能来,我一开始将n_estimators设置为3000,差点卡死。
#叠加基础模型class
class AveragingModels(BaseEstimator, RegressorMixin, TransformerMixin):
def __init__(self, models):
self.models = models
# we define clones of the original models to fit the data in
def fit(self, X, y):
self.models_ = [clone(x) for x in self.models]
# Train cloned base models
for model in self.models_:
model.fit(X, y)
return self
#Now we do the predictions for cloned models and average them
def predict(self, X):
predictions = np.column_stack([
model.predict(X) for model in self.models_
])
return np.mean(predictions, axis=1) AverangingModels是我在kaggle一个大神那里看到的,已经封装完成,可以直接把代码考来使用。最后会发现确实结合了多种基础模型的score值会提升空间确实很大。大神链接我已给出。
averaged_models = AveragingModels(models = (ENet, GBoost, KRR, lasso))
score = rmsle_cv(averaged_models)
print(" Averaged base models score: {:.4f} ({:.4f})\n".format(score.mean(), score.std()))![]()
def rmsle(y, y_pred):
return np.sqrt(mean_squared_error(y, y_pred))averaged_models.fit(train.values, y_train)
averaged_train_pred = averaged_models.predict(train.values)
averaged_pred = np.expm1(averaged_models.predict(test.values))
print(rmsle(y_train, averaged_train_pred))sub = pd.DataFrame()
sub['Id'] = test_ID
sub['SalePrice'] = averaged_pred
sub.to_csv('houseprice/submission.csv',index=False)
sub.head()