机器学习:什么是预测模型性能评估
https://www.toutiao.com/a6667486251471340035/
介绍
评价指标与机器学习任务具有相关性。分类、回归、排序、聚类、主题建模等任务都有不同的度量标准。一些度量标准,如精度、召回率,可用于多个任务。分类、回归和排序是监督学习的例子,它包含了大多数机器学习应用程序。在本文中,我们将关注监督机器学习模块的度量标准。
什么是模型评估?
评估模型是整个机器学习模型开发过程中非常重要的一步。一些方法,如神经网络模型在执行反向传播时进行评估。尽管如此,我们仍然通过各种方法手工执行模型的评估。
监督学习下的机器学习模型大致分为两类 - 回归问题和分类问题。此外,评估这些模型的方法也仅属于这两类。
评估回归和分类模型的方法之间存在根本区别:
- 通过回归,我们处理连续值,其中可以识别实际输出和预测输出之间的误差。
- 在评估分类模型时,重点是我们可以正确分类的预测数量。为了正确评估分类模型,我们还必须考虑我们错误分类的数据点。此外,我们处理两种类型的分类模型。其中一些产生类输出,如KNN和SVM,其输出只是类标签。其他是概率生成模型,如Logistic回归,随机森林等,它们的输出是数据点属于特定类的概率,通过使用截止值,我们能够将这些概率转换为类标签,然后我们可以最终对数据点进行分类。
模型评估技术
模型评估是模型开发过程中不可或缺的一部分。它有助于找到代表我们数据的最佳模型。它还关注所选模型在未来的运作情况。使用训练数据评估模型性能在数据科学中是不可接受的。它可以轻松生成过度优化和过度拟合的模型。在数据科学中,有两种评估模型的方法,即保持和交叉验证。为避免过度拟合,两种方法都使用测试集(模型未见)来评估模型性能。
模型评估是模型开发过程中不可或缺的一部分。它有助于找到表示数据的最佳模型。它还关注所选模型在未来的运作情况。在数据科学中,用训练数据评价模型性能是不可接受的。在数据科学中,有两种评估模型的方法:Hold-Out和交叉验证法。为了避免过度拟合,两种方法都使用测试集来评估模型性能。
Hold-Out
在这种方法中,大多数大型机器学习数据集被随机分为三个子集:
- 训练集是构建预测模型的数据集的子集。
- 验证集是数据集的子集,用于评估在训练阶段构建的机器学习模型的性能。它提供了一个测试平台,用于微调模型的参数并选择性能最佳的模型。并非所有建模算法都需要验证集。
- 测试集是数据集的子集,用于评估模型的未来可能性能。如果模型拟合训练集比拟合测试集的好的多,那么原因可能是过度拟合。
交叉验证
当只有有限数量的数据可用时,为了实现对模型性能的无偏差估计,我们使用k-fold交叉验证。在k-fold交叉验证中,我们将数据划分为大小相等的k个子集。我们构建模型时,每次从训练中删除一个子集,并将其作为测试集使用。如果k等于样本大小,这是一个“leave-one-out”方法。
回归模型评估方法
在构建了许多不同的回归模型之后,我们可以通过丰富的标准来评估和比较它们
均方根误差
RMSE是衡量回归模型错误率的常用公式。我们只能比较在相同单位下可以测量的模型的误差
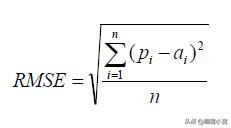
相对平方误差
与RMSE不同的是,相对平方误差(RSE)可以在模型之间进行比较,我们可以用不同的单位测量模型的误差
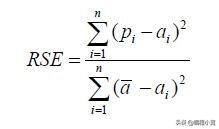
平均绝对误差
平均绝对误差是原始值和预测值之间差异的平均值。它为我们提供了预测与实际输出相距多远的度量。然而,它们并没有给我们任何关于误差方向的概念,即我们是对数据预测不足还是预测过度。数学上表示为:
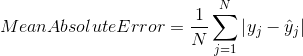
相对绝对误差
与RSE一样,相对绝对误差(RAE)可以在不同单位测量误差的模型之间进行比较。
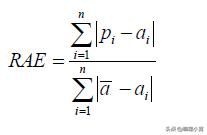
决定系数
决定系数(R2)总结了回归模型的解释力,并根据平方和项计算。

R2描述了由回归模型解释的因变量的方差比例。如果回归模型为“完美”,则SSE为零,R2为1。如果回归模型为完全失败,则SSE等于SST,回归不解释方差,R2为零。
标准化残差(Errors)图
标准化残差图是一种有用的可视化工具,可以在标准化的尺度上显示残差的分布规律。标准化残差图的模式与常规残差图中的模式没有本质区别。唯一不同的是y轴上的标准化尺度,它允许我们轻松地检测潜在的离群值。
分类模型评估方法
混淆矩阵
混淆矩阵显示分类模型与数据中的实际结果(目标值)相比所做的正确和不正确预测的数量。矩阵是N × N,其中N是目标值(类)的数量。通常使用矩阵中的数据来评估这些机器学习模型的性能。下表显示了两个类(正和负)的2×2混淆矩阵。

- 准确性(Accuracy):正确的预测总数的比例。
- 阳性预测值(Positive Predictive Value)或精度(Precision):正确识别的阳性实例的比例。
- 阴性预测值(Negative Predictive Value):正确识别的阴性实例的比例。
- 灵敏度(Sensitivity )或召回率(Recall):正确识别的实际阳性实例的比例。
- 特异性(Specificity):正确识别的实际阴性实例的比例。

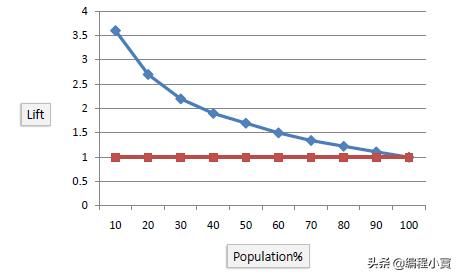
Gain和Lift
Gain和Lift是分类模型有效性的度量,其计算方法是使用该模型和不使用该模型的结果之间的比值。这些图是用于评估分类模型性能的视觉辅助工具。与评估整个群体的模型的混合矩阵相比,Lift图评估一部分群体的模型性能。

例:
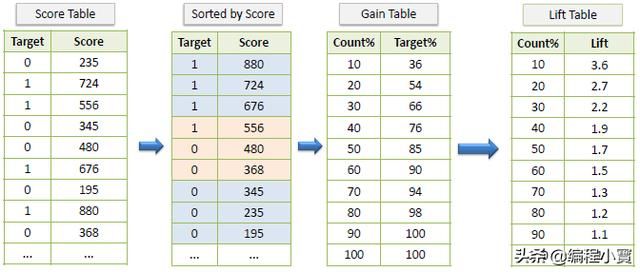
Gain Chart
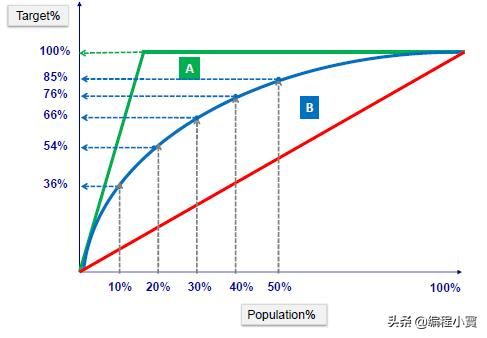
Lift Chart
Lift Chart显示,与随机抽样的客户相比,我们收到正面回应的可能性要大得多。举例来说,通过我们的预测模型仅联系10%的客户,我们将达到没有模型的三倍的受访者。
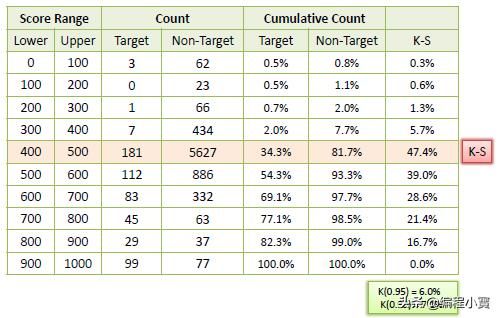
KS图
KS或Kolmogorov-Smirnov图测量分类模型的性能。更准确地说,KS是衡量正负分布之间分离程度的指标。如果得分将群体划分为两个独立的组,其中一组包含所有正面而另一组包含所有负面,K-S为100。另一方面,如果模型不能区分正面和负面,那么就好像模型从总体中随机选择案例,K-S将为0。在大多数分类模型中,K-S将介于0和100之间,并且值越高,模型在分离正面和负面情况时越好。
示例:以下示例显示分类模型的结果。该模型为每个positive (Target)和negative (Non-Target)结果分配0-1000之间的分数。

ROC
ROC图类似于gain或lift图,因为它们提供了分类模型之间比较的方法。ROC曲线还显示x轴为假阳性率(1-特异度),真值为0时目标为1的概率,y轴为真阳性率(灵敏度),真值为1时目标为1的概率。理想情况下,曲线会迅速向左上方攀升,这意味着模型的预测是正确的。此外,对角线红线是一个随机模型。

曲线下面积(AUC)
ROC曲线下面积通常是分类模型质量的度量。随机分类器的曲线下面积为0.5,而完美分类器的AUC等于1.实际上,大多数分类模型的AUC在0.5和1之间。

例如,ROC曲线下面积为0.8,表示从目标值为1的组中随机抽取的样本,80%的时间得分大于目标值为0的组中随机抽取的样本得分。此外,当分类器无法区分这两组时,面积将等于0.5(与对角线重合)。当两组完全分离时,即分布不重叠,ROC曲线下面积达到1 (ROC曲线将达到图的左上角)。