NSGA-III相关笔记
NSGA-III
- 目录
- 目的
- 区别
- NSGA-III的算法流程
- 非支配排序详解
- 归一化详解
目录
NSGA-III基于matlab的实现
参考文献
1.An Evolutionary Many-Objective Optimization Algorithm Using Reference-point Based Non-dominated Sorting Approach,Part I: Solving Problems with Box Constraints.
2.An Evolutionary Many-Objective Optimization Algorithm Using Reference-point Based Non-dominated Sorting Approach, Part II: Handling Constraints and Extending to an Adaptive Approach.
版权声明:本文为CSDN博主「sunny落花生」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wayjj/article/details/78954506
版权声明:本文为CSDN博主「Fengfeng__y」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/Fengfeng__y/article/details/93776983
知乎用户:https://www.zhihu.com/question/41365143?sort=created
链接https://www.zhihu.com/question/41365143/answer/137162878
目的
首先,非支配解的比例在随机选择目标向量集中与目标的数量呈指数相关(非支配解的比例随目标数量的增加而成指数增长),因为非支配解占据了种群中大部分位置,任何精英保护的EMO都很难容纳下足够数量的种群中的新解,这大大减慢了搜索过程;
其次,实现多样性保存(类似于拥挤度距离和聚类)将是一项计算耗时非常大的操作;
最后,超维前沿可视化是一个很困难的任务,因此导致了后续决策任务和算法性能评估的困难。
————————————————
区别
NSGA3与NSGA2的算法框架大致相同,只是在选择机制有所不同。NSGA2用拥挤距离对同一非支配等级的个体进行选择(拥挤距离越大越好),而NSGA3用的是基于参考点的方法对个体进行选择。NSGA3采用基于参考点的方法就是为了解决在面对三个及其以上目标的多目标优化问题时,如果继续采用拥挤距离的话,算法的收敛性和多样性不好的问题(就是得到的解在非支配层上分布不均匀,这样会导致算法陷入局部最优)。
————————————————
NSGA-III的算法流程
两种算法都是多目标进化算法,大致可以分为两步:第一步是非支配分层,第二步是从最后一个非支配层级中挑选个体进入子代。
NSGA-III算法其实可以被划分为以下五步:
1)首先假设有一个规模为N的种群A,用遗传算子(选择、重组、变异)对种群A进行操作,得到一个规模为N的种群B,再将种群A和种群B混合,得到一个规模为2N的种群C。
2)对种群C进行非支配排序(详见NSGA-II),得到非支配层级为1、2、3、4……的诸层个体。把非支配层级为1、2、3……的个体依次加入下一代子代的集合D,直到集合D的规模大于N。记下这个时候的非支配层级L。
我们接下来要做的,就是从L层级里挑选出K个个体,使得K和之前所有层级个体之和等于N
3)函数标量化操作这一步是要对多目标函数进行标量化操作,方便下一步关联参考点。首先需要计算M个目标函数中每一个目标维度i上的最小值(就是遍历取到Min啦,很简单的),得到第i个目标上对应的最小数值为Zi,此Zi的集合即为NSGA-III算法中提到的理想点集合(ideal points)。得到该理想点集合后,便有第一步的标量化公式,如下所示:

完成这一步之后,需要寻找极值点,也即NSGA-III算法中提到的extreme points,在此需要用到一个名为ASF(achievement scalarizing function)的函数,公式如下所示,该公式同样作用于每个维度的目标函数。
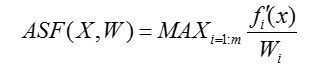
遍历每个函数,找到ASF数值最小的个体,这些个体就是extreme points,根据这些点的具体函数值,就能算出对应坐标轴上的截距,在这里,这个截距的实际意义是每个坐标点在对应坐标轴上的坐标值,可以将其记录为ai。得到ai和zi的具体数值以后,可以按如下所示的公式进行归一化运算:

4)个体关联参考点
NSGA-III是一种基于参考点的多目标进化算法,这个参考点至关重要,以四划分三个目标函数为例,参考点分布如下图所示(图片来源自NSGA-III原论文):

参考点的排列方式:
可以看到参考点是依次往上,逐级递减,一种简单的方法就是递归!虽然递归开销巨大,但是参考点又不需要每一代都算,可以一劳永逸。
得到相应划分的参考点之后,接下来要做的即为构建参考点向量(参考点到原点的连线,即为一条参考向量)。与其说NSGA-III是基于参考点的算法,不如说是基于参考向量的算法,
做完这一步以后,需要针对每一个种群个体遍历所有向量,找到距离每个种群个体最近的参考点(这里需要用到点到向量的距离公式),同时记录下参考点的信息和对应的最短距离。其中,种群个体到参考点向量的距离将用垂直距离来描述,三维示例如下图(图片来源自NSGA-III原论文):

因为要保存个体点、参考点、距离等等相关联的信息,实现的时候可以用结构体封装所有数据,或者新建一个类
5)最后一步,筛选子代与删除参考点
一个参考点可能有一个或多个种群成员与之相关,或者不需要任何种群成员与之关联。
经过非支配排序后,假设从第一个非支配层级到第FL层级的种群成员数目总和第一次超过种群规模N,那么定义St+1为包含了FL中全部个体的集合,由于St+1的规模超过了预先设定的种群成员数目,因此需要进行相应的筛选。筛选的第一步是对每个参考点进行遍历,查看它被不包含FL的St+1引用的次数,并且寻找到被引用次数最少的参考点,也即被数量最少的种群个体所关联的参考点,将其被引用次数记录为pj。
然后对pj分情况讨论:
(1)假如这个参考点关联的种群个体数量为零,也即pj等于零,但在FL中有个体被关联到这个参考点向量,则从中寻找距离最小的点,并将其从FL中抽取,加入到被选择的下一代种群中,设置pj=pj+1
(2)如果在FL中没有个体被引用到该参考点,则删除该参考点向量,倘若pj>0,则从中选择距离最近的参考点直到种群规模为N为止,就大功告成了!
非支配排序详解
/***NSGA-III 首先定义一组参考点。然后随机生成含有 N 个(原文献说最好与参考点个数相同)个体的初始种群,其中 N 是种群大小。接下来,算法进行迭代直至终止条件满足。在第 t 代,算法在当前种群 Pt的基础上,通过随机选择,模拟两点交叉(Simulated Binary Crossover,SBX)和多项式变异 产生子代种群 Qt。Pt和 Qt的大小均为 N。因此,两个种群 Pt和 Qt合并会形成种群大小为 2N 的新的种群 Rt=Pt∪Qt。
为了从种群 Rt中选择最好的 N 个解进入下一代,首先利用基于Pareto支配的非支配排序将 Rt分为若干不同的非支配层(F1,F2等等)。然后,算法构建一个新的种群St,构建方法是从 F1开始,逐次将各非支配层的解加入到 St,直至 St的大小等于 N,或首次大于 N。假设最后可以接受的非支配层是 L层,那么在 L+ 1 层以及之后的那些解就被丢弃掉了,且 St\ FL中的解已经确定被选择作为 Pt+1中的解。Pt+1中余下的个体需要从 FL中选取,选择的依据是要使种群在目标空间中具有理想的多样性。***/
举个例子说明一下,比如你的N设置为100,那么Pt大小为100,Qt是Pt交叉和变异后的个体,Qt的数目也是100,那么Rt=Pt∪Qt,Rt数目是两百,现在只要从这两百中选100个个体进行下一轮迭代。
那么怎么从这两百个选一百个呢?NSGA的思想首先是把所有解进行分非支配排序,这里目标值越小越好,甲三个目标值是(2,3,5),乙的三个目标是(4,3,5),丙的三个目标是(3,3,4),那么给甲和丙在F1层即等级为1,F2层是乙,等级为2,以此类推。假如一共有8层非支配层(F1,F2,。。。,F8),你选到F1+F2+F3+…+F7时候已经有90个个体了,而F8层有20个个体,那么怎么在F8选这10个个体,即怎么在F8里的20个选十个,NSGA2用的是基于拥挤距离的方法,而NSGA3用的是基于参考点的方法。( St\ FL里面,St就是这里的F1到F7的所有个体的总和,F8就是FL,St\ FL这个符号意思就是已经被选择的F1到F7所有个体)
在原始NSGA-II中,FL中具有较大拥挤距离的解会优先被选择。然而,拥挤距离度量并不适合求解 MaOPs(三个及更多目标的多目标优化问题)。因此 NSGA-III 不再采用拥挤距离,而是采用了新的选择机制(这个机制就是NSGA3与2之间的最大区别之处),该机制会通过所提供的参考点,对 St中的个体进行更加系统地分析,以选择 FL中的部分解进入 Pt+1。
归一化详解
a) 先对目标值进行映射(映射的方法是减去理想点的值)
b) 然后找到每个维度的极端点(也就是离每个坐标轴比较近的点)
c) 找极端点的方法是:固定某一个维度,该维度的权重设为1,其他维度的权重设为一个很小的值,对于每一个解,用ASF计算它的值(以所有维度上的最大值表示这个解),选择所有解中ASF值最小的解作为极端点。
d) 一般情况下,所有维度的极端点可以确定一个超平面。e) 计算这个超平面和各个坐标轴的交点(截距)
f) 归一化的时候直接除以截距