这篇文章是Python爬虫的第二篇,目标是新浪微博的评论人的性别,地区,等信息,写的不好的地方请指正。
先来分析一下数据的位置。
个人资料的网址有两种,如果用户没有设置个性域名,网址即为图1,微博默认的ID(weibo.cn/u/**********)。否则为图二(weibo.cn/purdence520)。因为我们之前获取的到的信息,可能为域名或id,所以这里需要判断,再获取信息页。

再来看看源码,信息都在
class="c"的
div的第五个子标签内(0索引开始)
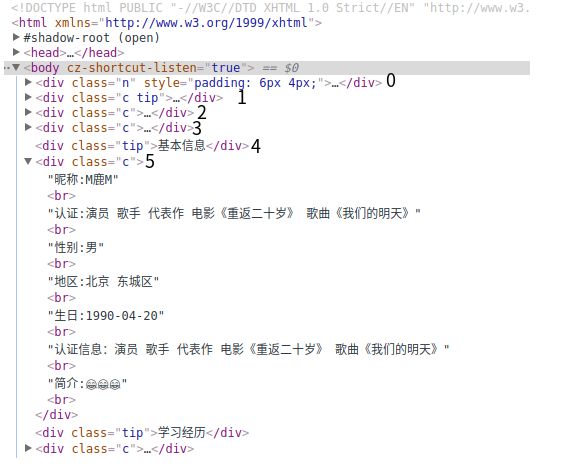
代码
def get_page(self, domain, num):
url = 'https://weibo.cn/{}/info'.format(domain)
print(url)
try:
req = requests.get(url, headers=self.header, timeout=5,
cookies=self.cookie[2],)
soup = BeautifulSoup(req.text, 'lxml')
if req.status_code == 200:
return soup
else:
print(req.status_code)
url = 'https://weibo.cn/{}'.format(domain)
req = requests.get(url, timeout=5,
cookies=self.cookie[self.cg_id],
headers=self.header)
soup = BeautifulSoup(req.text, 'lxml')
domain = re.compile(r'/(\d+)/info').\
findall(str(soup))[0]
return self.get_page(domain, num)
except Exception as e:
raise(e)
此方法用于获取信息页,需判断id页还是个性域名页。domain参数是id/域名,num参数是存到数据库里的自增列,用于定位。如果以id/info的网址可以获取到信息,则返回获取到的页面。否则用域名网站获取最后返回一个信息页面。

个性域名错误网址,页面不存在。
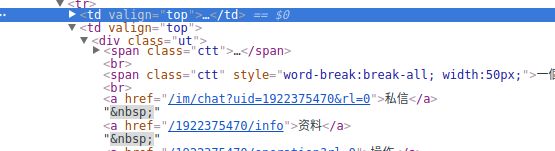
从个性欲名页面爬到ID
用正则表达式匹配信息,把没有填生日的信息设为none,用tools包操作数据库。
def get_sab(self, q):
while True:
num = q.get()
self.user_domain = tools.s_domain(num)
soup = self.get_page(self.user_domain, num)
try:
self.user_sex = re.findall(r'性别:(.*?)用Queue来生成数据库自增num,获取数据库中每一个domain
def set_num(self, q):
global num
while True:
q.put(num)
print(num, 'put')
num += 1
GitHub开源地址:https://github.com/matianhe/crawler