爬取豆瓣电影数据(基于R)
爬取豆瓣电影数据(基于R)
- 爬取豆瓣电影数据
- 了解网页结构
- 自动收集单个网页数据
- 自动收集多个网页数据
爬取豆瓣电影数据
网络爬虫,就是从网页中获取需要的信息,提取相应的数据。
可以利用R语言爬虫获取网页数据信息,便于统计分析。
常用的从网页中获取信息的包有RCurl,XML,rvest等 。还可以利用RSslenium包或者Rwebdriver包模拟浏览器爬取异步加载等较难爬取的网页信息。
本文便以爬取豆瓣电影数据为例,来描述网络爬虫过程。
爬取网址如下:
https://movie.douban.com/top250?start=0&filter=
<本文是学习《R语言统计分析与机器学习》后的学习笔记>
了解网页结构
所需要的数据概况:

从网页中大概能发现,该网页含有电影名称,电影评分,电影主题,电影别称等数据信息。
再进入网页源代码界面找规律

可以发现有十分一致的规律:
电影名称,电影别称:
<a href="https://movie.douban.com/subject/1292052/" class="">
<span class="title">肖申克的救赎</span>
<span class="title"> / The Shawshank Redemption</span>
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
</a>
电影评分,电影主题:
<div class="star">
<span class="rating5-t"></span>
<span class="rating_num" property="v:average">9.7</span>
<span property="v:best" content="10.0"></span>
<span>1987790人评价</span>
</div>
<p class="quote">
<span class="inq">希望让人自由。</span>
</p>
具体的对应情况如下:
电影名称:
<span class="title">肖申克的救赎</span>
电影别称:
<span class="other"> / 月黑高飞(港) / 刺激1995(台)</span>
电影评分:
<span class="rating_num" property="v:average">9.7</span>
电影主题:
<span class="inq">希望让人自由。</span>
下面便利用发现的规律,利用R进行数据爬取。
自动收集单个网页数据
- 导入需要的包 ,导入需要的包;
library(rvest)
library(stringr)
- 读取网页,并进行数据提取 ,读取网页,程序如下:
## 读取网页,获取电影的名称
top250 <- read_html("https://movie.douban.com/top250")
title <-top250 %>% html_nodes("span.title") %>% html_text()
head(title)
## 获取电影第一个名字
title <- title[is.na(str_match(title,"/"))]
#这里使用str_match()函数来匹配带有“/”的字符串,并进行剔除,只保留想要的内容
head(title)
## 获取电影的评分
score <-top250 %>% html_nodes("span.rating_num") %>% html_text()
filmdf <- data.frame(title = title,score = as.numeric(score))
## 获取电影的主题
term <-top250 %>% html_nodes("span.inq") %>% html_text()
##获取电影的别称
other <-top250 %>% html_nodes("span.other") %>% html_text%>%str_trim()%>%str_replace_all("\\/|","")%>%str_replace_all("(\u00A0)", "")#最后那部分是剔除文本中的特殊符号
filmdf$term <-term
filmdf$other<-other
head(filmdf)
运行结果
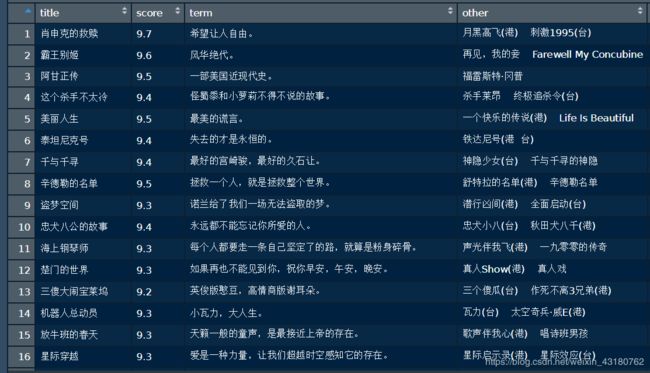
此时,我们成功爬取了第一页的数据,那么如何利用程序自动爬取其他页面的数据呢?
我们可以观察网址的规律。
- 第一页:https://movie.douban.com/top250?start=0&filter=
- 第二页:https://movie.douban.com/top250?start=25&filter=
- 第三页:https://movie.douban.com/top250?start=50&filter=
我们可以发现加粗部分,存在以25递增的关系,其他的保持不变。故我们可以考虑利用循环的方式进行爬取。
自动收集多个网页数据
字符串的拼接,网址是一串较为复杂的字符串,但本例之中,大部分内容不改变,改变的仅仅是数字,故我们可以考虑利用字符串拼接的方式,得到不同页面的网址链接。
字符串拼接函数:
paste(......, sep = " ", collapse = NULL)
其中……表示一个或多个可以被转化为字符型的对象;
参数sep表示分隔符,默认为空格;
参数collapse可选,如果不指定值,那么函数paste的返回值是自变量之间通过sep指定的分隔符连接后得到的一个字符型向量; 如果为其指定了特定的值,那么自变量连接后的字符型向量会再被连接成一个字符串,之间通过collapse的值分隔。下面用具体的例子说明各参数的作用
本例中,对网页进行拼接可得到:
> i=1
> u1<-paste("https://movie.douban.com/top250?start=", 25*i,"&filter=",sep = "", collapse = NULL)#字符串拼接
> print(u1)
[1] "https://movie.douban.com/top250?start=25&filter="
其中i是从0开始增加,每个i对应一个网页页面,故可由i循环,以达到反复爬取网页数据的功能。
程序如下:
filmdf <- data.frame()
data<-data.frame()
for(i in 0:10){
u1<-paste("https://movie.douban.com/top250?start=", 25*i,"&filter=",sep = "", collapse = NULL)#字符串拼接
top250 <- read_html(u1)
title <-top250 %>% html_nodes("span.title") %>% html_text()
head(title)
## 获取第一个名字
title <- title[is.na(str_match(title,"/"))]
head(title)
## 获取电影的评分
score <-top250 %>% html_nodes("span.rating_num") %>% html_text()
## 获取电影的主题
term <-top250 %>% html_nodes("span.inq") %>% html_text()
#获取电影的别名
other <-top250 %>% html_nodes("span.other") %>% html_text%>%str_trim()%>%str_replace_all("\\/|","")%>%str_replace_all("(\u00A0)", "")
#获取电影的主题
quote <-top250 %>% html_nodes("p.quote") %>% html_text()%>%str_trim()%>%str_replace_all("\\\n|","")
#将数据添加进数据框
filmdf <- data.frame(title = title,score = as.numeric(score))
filmdf$term <- term
filmdf$other<-other
filmdf$quote<-quote
head(filmdf)
#以行的形式,对数据框进行拼接
data<-rbind(data,filmdf)
}
运行结果如下:
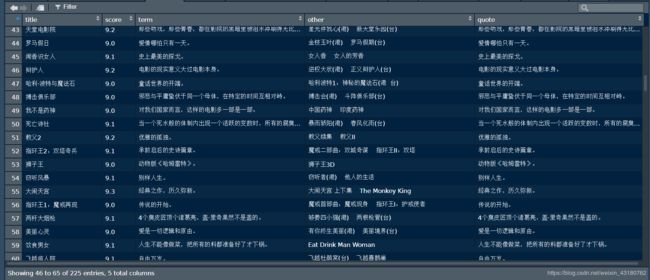
本例探究的是爬取网页中的文本数据,注意得从网页源代码找规律,同时注意对文本数据字符串的处理方法。
常用去除特殊符号的方法:
Fen_red<- data$文本数据
for(ii in 1:length(Fen_red)){
Fenone <- str_c(Fen_red[ii],sep = "")
Fenone <- str_remove_all(Fenone,pattern = "[:punct:]")
Fenone <- str_remove_all(Fenone,pattern = "\n")
Fenone <- str_remove_all(Fenone,pattern = "\r")
Fenone <- str_remove_all(Fenone,pattern = " ")
Fenone <- str_remove_all(Fenone,pattern = "\t")
Fenone <- str_remove_all(Fenone,pattern = "c")
Fenone <- str_remove_all(Fenone,pattern = "\u3000")
Fen_red[ii] <- Fenone`
}
fen<-as.data.frame(Fen_red)#此时Fen_red即为剔除特殊符号的了
当然在数据提取中即剔除则更加简洁便利,如下程序:
other <-top250 %>% html_nodes("span.other") %>% html_text%>%str_trim()%>%str_replace_all("\\/|","")%>%str_replace_all("(\u00A0)", "")
quote <-top250 %>% html_nodes("p.quote") %>% html_text()%>%str_trim()%>%str_replace_all("\\\n|","")
str_trim()%>%str_replace_all("\\n|","") 剔除特殊符号十分便捷。