Python爬虫之BeautifulSoup库的简单使用
一、介绍BeautifulSoup库
Beautiful Soup是用Python写的一个HTML/XML的解析器,它可以很好的处理不规范标记并生成剖析树(parse tree)。 它提供简单又常用的导航navigating,搜索以及修改剖析树的操作。它可以大大节省你的编程时间。
BeautifulSoup的用法简单讲解下,使用“爱丽丝梦游仙境”的官方例子:
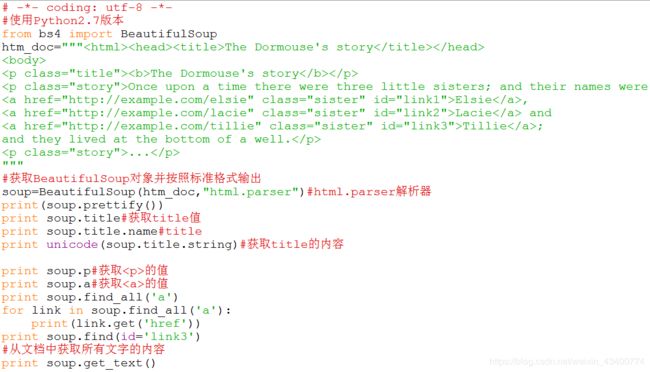
温馨提示:当运行过程中可能会报错:TypeError: an integer is required,则采取以下方式解决:
‘’’
当你使用“print soup.title.string”获取title的值时,可能会遇到该错误。如下:
它应该是IDLE的BUG,当使用命令行Command没有任何错误。参考:stackoverflow。同时可以通过下面的代码解决该问题:
print unicode(soup.title.string)
print str(soup.title.string)
‘’’
二、Beautiful Soup常用方法介绍
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:Tag、NavigableString、BeautifulSoup、Comment|
1、tag标签
tag对象与XML或HTML文档中的tag相同,它有很多方法和属性。其中最重要的属性name和attribute。用法如下:
 在Python2.7版本运行以上代码会出现警告的提示,如下:
在Python2.7版本运行以上代码会出现警告的提示,如下:
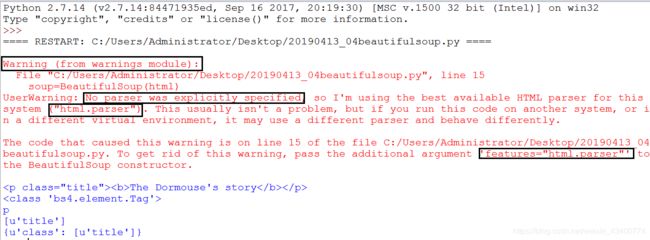 解决以上问题:把以上的“soup=BeautifulSoup(html)”
解决以上问题:把以上的“soup=BeautifulSoup(html)”
up=BeautifulSoup(html,“html.parser”)”即可
总结:使用BeautifulSoup每个tag都有自己的名字,可以通过.name来获取;同样一个tag可能有很多个属性,属性的操作方法与字典相同,可以直接通过“.attrs”获取属性。至于修改、删除操作请参考文档。
2.NavigableString
字符串常被包含在tag内,Beautiful Soup用NavigableString类来包装tag中的字符串。一个NavigableString字符串与Python中的Unicode字符串相同,并且还支持包含在遍历文档树和搜索文档树中的一些特性,通过unicode()方法可以直接将NavigableString对象转换成Unicode字符串。

运行以上程序结果如下:

这是获取“
The Dormouse’s story
”中tag = soup.p的值,其中tag中包含的字符串不能编辑,但可通过函数replace_with()替换。NavigableString 对象支持遍历文档树和搜索文档树 中定义的大部分属性, 并非全部。尤其是一个字符串不能包含其它内容(tag能够包含字符串或是其它tag),字符串不支持 .contents 或 .string 属性或 find() 方法。
如果想在Beautiful Soup之外使用 NavigableString 对象,需要调用 unicode() 方法,将该对象转换成普通的Unicode字符串,否则就算Beautiful Soup已方法已经执行结束,该对象的输出也会带有对象的引用地址。这样会浪费内存。
3.Beautiful Soup对象
该对象表示的是一个文档的全部内容,大部分时候可以把它当做Tag对象,它支持遍历文档树和搜索文档树中的大部分方法。
注意:因为BeautifulSoup对象并不是真正的HTML或XML的tag,所以它没有name和 attribute属性,但有时查看它的.name属性可以通过BeautifulSoup对象包含的一个值为[document]的特殊实行.name实现—— soup.name。
Beautiful Soup中定义的其它类型都可能会出现在XML的文档中:CData , ProcessingInstruction , Declaration , Doctype 。与 Comment 对象类似,这些类都是 NavigableString 的子类,只是添加了一些额外的方法的字符串独享。
4.Command注释
Tag、NavigableString、BeautifulSoup几乎覆盖了html和xml中的所有内容,但是还有些特殊对象容易让人担心——注释。Comment对象是一个特殊类型的NavigableString对象。

运行以上程序结果:
5.遍历文档树
一个Tag可能包含多个字符串或其它的Tag,这些都是这个Tag的子节点。BeautifulSoup提供了许多操作和遍历子节点的属性。引用官方文档中爱丽丝例子操作文档最简单的方法是告诉你想获取tag的name,如下:

运行结果如下:

子节点
在分析HTML过程中通常需要分析tag的子节点,而tag的 .contents 属性可以将tag的子节点以列表的方式输出。字符串没有.contents属性,因为字符串没有子节点。

运行程序结果如下:

通过tag的 .children 生成器,可以对tag的子节点进行循环:

运行结果如下:
子孙节点:同样 .descendants 属性可以对所有tag的子孙节点进行递归循环:

运行结果如下:

父节点:通过 .parent 属性来获取某个元素的父节点.在例子“爱丽丝”的文档中,head标签是title标签的父节点,换句话就是增加一层标签。
注意:文档的顶层节点比如html的父节点是 BeautifulSoup 对象,BeautifulSoup 对象的 .parent 是None。

运行结果如下:

兄弟节点:因为 标签和标签是同一层:他们是同一个元素的子节点,所以和可以被称为兄弟节点。一段文档以标准格式输出时,兄弟节点有相同的缩进级别.在代码中也可以使用这种关系。

运行结果如下:

在文档树中,使用 .next_sibling 和 .previous_sibling 属性来查询兄弟节点。标签有.next_sibling 属性,但是没有.previous_sibling 属性,因为标签在同级节点中是第一个。同理标签有.previous_sibling 属性,却没有.next_sibling 属性:

运行结果:

本文大部分源于:
https://blog.csdn.net/Eastmount/article/details/44593165,根据原作者的程序在Python2.7版本运行,学到了Python爬虫中的BeautifulSoup库中的对象、方法和属性,以及如何遍历文档树等。如果以上有不对和不足之处,希望大家及时指点。