(连载)词向量的理解——词嵌入向量(word embedding)
文章均从个人微信公众号“ AI牛逼顿”转载,文末扫码,欢迎关注!
上篇文章的结尾指出了one-hot向量有重大缺陷,缺陷是啥?
 此种编码使得任意两个向量的乘积都为0
此种编码使得任意两个向量的乘积都为0
也就是说,虽然可以算距离,但是距离都一样,还是没法体现出词的相似性。比如:“爸”与“爹”,是同义词;“大”与“小”是反义词。按照上面的编码方式,词的相似性没法加以区分。
如何解决这个问题?
如果我们给定几个评判标准,然后每个词都按照这几个标准给出一个值,把这些值组成向量,用来刻画词语,会怎么样呢?
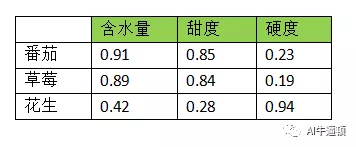
那么这三个词的向量表示分别为:
番茄[0.91, 0.85, 0.23]
草莓[0.86, 0.84, 0.19]
花生[0.42, 0.28, 0.94]
显然,这种向量表示要比one-hot好得多,体现在如下几个方面:
1、能较好的体现词之间的关系。这里番茄和草莓就比较相似,花生算另类。稍微想象一下,把这三个向量放到空间直角坐标系里,番茄和草莓这两个点就很接近,花生离的就比较远。
2、向量的长度比较短。假设这三个指标是通用的,那么不管有多少个词,每个词的向量长度都是3。而one-hot向量的长度直接等于词的个数。
 欧几里得的《几何原本》,所有的结论都是建立在几个公设之上。但是我们这里没法找到这么一组通用的标准来刻画所有的词。
欧几里得的《几何原本》,所有的结论都是建立在几个公设之上。但是我们这里没法找到这么一组通用的标准来刻画所有的词。
既然找不到,那就人为规定!!!注意,不是规定具体的标准是什么(找都找不到,咋规定),而是规定标准的个数!!!也就是规定每个向量的长度。至于这个定长向量里的值是什么,要先说一下统计语言模型。
n-gram语言模型
简单的说,就是根据前面出现的n-1个词,推断出下一个最可能是什么词。

这个很好理解呀,配合默契的两人,其中一人说完上句,另一个就能猜出下句,就是n-gram的体现。之所以是猜,因为下一句有可能存在好几种情况,猜的人只是回答最可能的那句话。数学刻画就是让下面的这个条件概率最大。
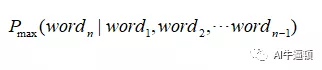
训练词向量
接下来就是利用n-gram语言模型,训练一个简单的全连接神经网络了。先去准备很多数据吧,长成这样就行:
我要去打球啦。
今天又要上班,不开心。
一年只放两次假,每次放半年,很好。
训练神经网络,需要带标签的数据。原始数据就是一些句子,没有标签。不过,根据n-gram模型,我们可以不断的构造出标签。比如把n取3,就是根据前两个词,预测第三个词。这样,我们就可以把原始数据处理成下面的样子:

第一句原始数据就处理成了4条带标签(有目标)的训练数据,通过训练神经网络,希望它能用已知词去预测出对应的目标。
标准的网络结构及其细节可以查阅文末提供的参考链接。这里只是把主要流程展现出来。
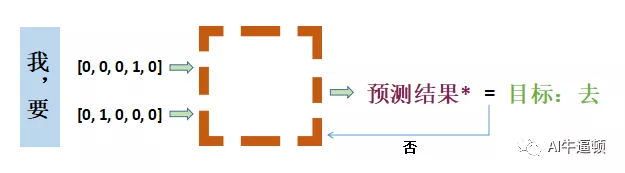 全连接神经网络的计算,大部分就是矩阵的乘法
全连接神经网络的计算,大部分就是矩阵的乘法
线框就是一个矩阵,把one-hot向量和它相乘。要使预测结果与目标相同,不断调整矩阵里的值即可。
这个矩阵不仅要满足第一条训练数据的预测要求,还要满足其它所有训练数据的预测要求。可以想象,这个矩阵里的值要不断的调整,使得在一定精度条件下,满足所有数据的预测要求。
 和线性回归一个道理,直线虽不能拟合所有的点,但是能让大部分点均匀分布在直线的周围,反映出点的分布特点就行了。
和线性回归一个道理,直线虽不能拟合所有的点,但是能让大部分点均匀分布在直线的周围,反映出点的分布特点就行了。
前文提到的通用标准的个数,其实就是矩阵的一个维度(列数)。一般这个值取50~300之间(实验效果较好)。假设我们现在把这个参数设置为150。矩阵的另一个维度(行数)是字典里所有字的个数。
通过反复的训练之后,我们就能得到这个重要的参数矩阵。矩阵的行数表示原始数据里字(词)的总个数,列数就是这里设置的150。
具体到每个词的向量是什么呢?很简单了,用每个词的one-hot向量去乘以这个矩阵,就能把对应的这个词的向量表示给找出来。所以呀,one-hot向量又像是个查询标签。

N表示字的总数量。图中的one-hot向量里,1在第二个位置,与参数矩阵相乘后,就是第二行的值。这个结果就是这个词的向量表示,称为word embedding向量(词嵌入向量)。
 这就是嵌入!啥玩意都可以包在这里面
这就是嵌入!啥玩意都可以包在这里面
词嵌入就是把所有的词都映射到这个150维的空间里(用上面的“番茄”、“草莓”、“花生”的例子去想像,就是所有的词都放到一个立体空间中)。而且这些向量是用大量的数据通过训练得到的,用来刻画词之间的关系,其效果肯定得到了很大的提升。
当然了,这150个维度具体代表了什么含义,没人说得清楚。所以词向量的可解释性很差,但是好用呀。所谓只可意会不可言传。
结语
利用大量数据,基于语言模型,结合神经网络就能训练出一个参数矩阵,从而得到了词语的向量表示。这种向量表示能不能完全表征出词语的信息?这种思路还可以得到怎样的发展?下一篇就该目前为止的大杀器登场了。
注:大名鼎鼎的word2vector在网络构造上与文中的理解有些偏差。另外,关于很多细节也忽略了,比如:去掉停用词、负采样、未登录词等。详情可以参考文末的一些链接。

千里之行始于足下!定期分享人工智能的干货,通俗展现原理和案例实现,并探索案例在中学物理教育过程中的使用。还有各种有趣的物理科普哟。坚持原创分享!坚持理解并吸收后的转发分享!欢迎大家的关注与交流。