fastai2019深度学习课堂笔记
文章目录
- deep learning pipeline
- 获得源数据
- 数据处理
- 处理源数据
- data segmentation
- progressive resizing
- normalization归一化
- processors & transformers
- datablocks
- 使用均方根误差RMSPE
- 数据增强
- 模型构建
- 16位浮点运算
- wd - 正则化惩罚参数
- Adam = momentum-动量法 + RMSprop
- dropout
- 批量归一化
- Res block
- 选择一个合适的代价方程
- gan_critic
- 模型训练
- fit_one_cycle
- 迁移学习transfer learning
- discriminative learning
- 模型评估
- 训练集误差和验证集误差
- 交叉熵 - cross entropy
- Interpretation
- 模型调试
- y_range
- pca
- 实战经验
- Broken pipe报错
- GPU内存溢出
- jargon
- RNN
- 协同过滤
- 关注你在乎的,而不是人人都在讨论的
作为自学党,走入深度学习所面临的主要问题不是理论知识多少,而是怎样理论结合实际,也就是说:怎么写代码。为此,基于pytorch高度封装的fastai是很好的选择,其相关课程内容也注重代码,能够比较好地帮助初学者学以致用,迅速上手。当然,fastai的学习不是深度学习的唯一亦或终点,但是对于新手来说,无疑是一个难度适中,不容易劝退,同时也能够收获满满的选择。
本文收录自认为fastai practical deep learning v3中的重点方法、经验、概念和自己的总结以及心得。
时间宝贵,笔记只起一个总结和帮助回忆的辅助作用而且其中很多详细的理论内容看吴恩达的深度学习系列课程效果会好得多,原课程内容以及实战应用才是重点。当然,也期待以后能有更加全面美观的笔记内容出现~
本文会随着fastai的更新以及我对课程的内容回顾而不断调整内容。
如果对fastai感兴趣欢迎关注百度贴吧fastai,一起交流讨论,我和其他人包括课程负责人会持续在上面发布内容帮助所有感兴趣的人学习深度学习,以及最新的课程资源等等。

deep learning pipeline
总的而言,深度学习的pipeline和机器学习是类似的:
- 获得源数据
- 数据处理
- 模型构建
以下三步重复进行,知道获得满意的结果
- 模型训练
- 模型评估
- 模型调试
接下来,我将根据pipeline中的各项步骤对其进行逐一的细分,总结并且注明注意事项。
获得源数据
- 下载
- 解码(一般是解码)
- 读取
关于数据源的获取,第一堂课后的笔记有相信的介绍,各取所需即可。
数据处理
数据处理可以说是fastai中最tricky,最繁琐的一个阶段。其特性在深度学习中普遍适用。
处理源数据
获得的源数据不满足深度学习的条件时,我们需要先进行一定的处理,使其具有统一的格式以及可用于训练检验的标签。
data segmentation
对于图片识别问题而言,是要对图片中的每一个像素进行分类,同类(往往就是同一种物体)通过整形的像素值表示成统一的颜色,分类后的图片单独保存,其中每种颜色的像素区域(亦即颜色)起到监督学习中标签的作用,实际大概是这样:
注意:使用data segmentation处理后的图像使用unet模型更好
progressive resizing
往往用于图像训练,其实是属于图像迁移学习的一部分。
- 使用缩小后的数据集进行训练(往往缩小1/2,比如256的图片缩成128,64意义不大)
- 进行模型调试,获得满意结果
- 迁移到原图片进行训练。所谓迁移,其实就是使用原大小的图片再训练几轮即可~
作用是在“不”影响模型表现得情况下极大地缩短时间成本。
normalization归一化
一般而言,imagenet数据集就应该使用imagenet.stats进行归一化。自己的归一操作很有可能消去原有图片的一些特征
processors & transformers
出现在第四课处理表格数据
- 前者多用于文本处理,尤其是表格数据;后者多用于图片。
- processors在整个训练过程中只出现一次,而且只在模型训练之前;transformers可以在训练过程中做多次变形,多次使用,可以在训练之前,也可以在训练期间。
datablocks
datablocks是fastai中数据处理的重要概念,前提是我们已经获得了统一数据形式且拥有标签来源的数据。
使用均方根误差RMSPE
均方根误差广泛使用于人口预测,销售额预测等长尾分布的,在意比值差异而非精确数值或绝对值差异的数据集中。
在label_from_df方法中加入log=True即可使用RMSPE
具体内容待补充。
数据增强
- 提供更多的数据
- 提供正则化的效果
数据增强常用于计算机视觉领域,包括对比度、曝光度、旋转、对称、亮度等等,fastai对于图片处理是具有相当优势的。而如何将数据增强应用到其他领域也是下载广泛关注的一个问题。
fastai中数据增强最好的padding_mode是reflection,因为填充了黑边从而使图形更接近现实情况。
模型构建
16位浮点运算
![]()
建模时一步即可,前提是NVidia显卡+cuda驱动~,使用16位浮点计算可以显著降低GPU负担,甚至获得更好的分类模型!原理大概是泛化运算减缓了32位精确运算中的过拟合,增强模型的通用性。
wd - 正则化惩罚参数
参数越多模型越复杂?事实不是这样的,如果有大量的接近于0的参数,那么模型仍不容易过拟合,且能够拟合复杂的曲线,这是深度学习解决实际问题所需要的。
所以应该如何评价模型参数的复杂度呢?求他们的平方和,然后就可以通过将他们限定在一定的范围内。而wd就是对这个平方和值进行惩罚的参数,即机器学习正则化中的 l a m b d a lambda lambda
一般能够提供较好表现的wd=0.1,然而默认为0.001,这也能够提供较好的模型效果。
Adam = momentum-动量法 + RMSprop
优化梯度下降。
momentum通过导数方向左右来回寻找最低点而不是沿一个方向不断下降,其实就是对参数更新值指数加权平均值。通常而言momentum=0.9是比较好的,值越大,正则化效力越强。
RMSprop也是通过加权平均,但是用到了参数求导项上,然后使用:
![]()
来更新参数,这样一来前进的每一步要是过小的话就能够被调大,太大的话又能够通过惩罚减小步伐。之后你可以再对得到的这个新参数使用动量法。但是动量法和RMSprop到底谁先谁后呢~
而Adam就是记录momentum + RMSprop的一种算法,然后使用它们进行参数更新。
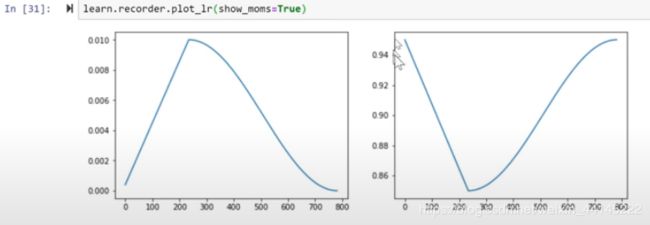
而真实的fit-one-cycle其实是变化的学习率和momentum值的合体;左为learning rate,由为momentum,可见两者是反过来的,可提速十倍及以上。
dropout
一种用于避免过拟合的正则化方法(regularization),一般不用于input data和测试期:

为了避免欠拟合的发生:
- ps:float list/float,probablity for dropout in each layer from the first not input layer
- emb_drop: drop embedding as in cotinuous data can not use dropout but the embedding (each layer’s activation values) can be dropped out
以上两者可以一起用,而且一起用时效果更好,面对大量参数一般1e-3至1e-2之间即可
批量归一化
批量归一化实际上是底层的东西,必用,看不到但是随时随地都在用。
作用的原理是增加两个参数构成线性方程来对激活值进行左右旋转和上下摆动,从而增强梯度下降的效率和准确性。一般而言这个调整是基于动量化处理之后的结果的。
Res block
residual block

可以设置kernel为0从而使该层的input data直接传递到下一层,从而使得深层神经网络可以适当降低其深度从而避免层数过多时卡在局部优化区域从而导致损失值反而增大的情形。
由此发展而出的dense net远离基本相同,只不过将输出函数由加法改成了concatenate。dense net仍然保存了原始的输入数据,对小数据集表现极佳。在fastai中,初始化ResBlock类时添加self.dense=True即可。
选择一个合适的代价方程
代价方程相比其它种种更加容易被人忽略,但是作为推导向后传播的基石,合适的代价方程能够给予模型很好的纠错能力,在不少问题中具有重要的地位。
比如在图片生成和清晰化的问题中,选择平方和作为代价函数不能够放映出图片细节,因为好坏图片像素的颜色大体相同,于是代价函数的值都很小,不能够很好地帮助模型进行调整。
gan_critic
对抗生成网络使用的critic learner一方使用的模型不是resnet而是gan_critic,一个预训练的分类模型。可以用resnet代替,如果能够使用经过spectral归一化的resnet也可行;但何必那么麻烦呢~
对抗神经网络中一般不适合使用动量法,因为参数在两者之间变来变去的,动量法会使得参数继承到另一个神经网络的参数影响。
模型训练
fit_one_cycle
使用fit_one_cycle而不是fit进行训练和调试,前者进行后续调试的学习率和误差都呈先上升,再下降的趋势(原理第三节课),其表现优于fit,主要也是由于引入了权重衰减这一调优方法。
迁移学习transfer learning
迁移学习适用于计算机视觉分析,也适用于NLP,其本质即使用现有的数据对提前训练好的预置模型进行微调。
迁移学习的重要意义体现在NLP中(必须掌握)。预置模型(比如使用维基百科训练好的模型)包含了大量的常识和语言逻辑,而现实模型(比如IMDB影评)则应足够对原有的知识库进行补充和拓展,这是迁移学习成功的基础。
为了确保现实模型的训练力度,在kaggle之类的比赛中,可以将训练集和测试机的文本一起作为corpus丢给模型进行学习(因为标签对我们知识库的微调没有意义,文本本身才有意义),然后验证集就可以减少(0.1 - 0.15)。
NLP中的迁移学习分为了知识库学习(理解文本)和分类学习(预测文本属性)两个部分,前者负责学习新的文本材料,后者负责进行分类,详细请见课堂笔记。
discriminative learning
针对不同的神经网络层采用不同的学习率。这对于迁移学习而言十分重要:预先训练的前几层一般都是最基础的分类且表现良好,此时参数改变应较小,即学习率较小;而越往后的层数模型则应改变越大,从而适应迁移的数据集。因此我们在面对fit-one-cycle时有三种方法:
- 1e-3:所有的层数都使用学习率0.001。
- slice(1e-3):最后一层使用1e-3,之前层全部使用1e-3/3。
- slice(1e-5, 1e-3):第一层使用1e-5,最后层使用1e-3,中间层等比取值。
事实上这些东西都是对于layer groups而言,而不是单独的每一层。
模型评估
训练集误差和验证集误差
训练集误差低于验证集误差为好,否则是欠拟合。没错机器学习理论大师会用一副经典的图来证明训练集误差高于验证集才是正常情况,很可惜,实践才是检验真理的唯一标准。
如果训练集误差总是大于验证集误差,为了避免欠拟合:
- 降低后几次训练的方法的学习率
- 降低regularization效力
- 。。。
交叉熵 - cross entropy
只要自信预测,不要不自信的预测结果,比如文字识别等分类问题,怎么做到呢?
在满足 ∀ x p ( X = x ) ϵ [ 0 , 1 ] \forall x p(X=x) \epsilon[0,1] ∀xp(X=x)ϵ[0,1] 月 ∑ x p ( X = x ) = 1 \sum_{x} p(X=x)=1 ∑xp(X=x)=1的前提下:
H ( p , q ) = − ∑ x p ( x ) log q ( x ) H(p, q)=-\sum_{x} p(x) \log q(x) H(p,q)=−x∑p(x)logq(x)
激活函数q一般选择的是softmax函数,因为这需要满足所有的激活也同样相加等于1。于是,熵值越接近0,预测正确的自信度越高;越接近1,预测错误的自信度越高。
Softmax:
Interpretation
fastai learner类无疑已经为我们封装了大量的内容,包括训练模型,训练数据等等。但是一些关键的分析内容还是无法由learner直接给出。
这时我们需要额外的方法对learner中的内容进行编译,为此我们新建ClassificationInterpret对象,然后就可以直接调用top_losses和plot_matrix等方法进一步进行模型评估了。
模型调试
模型调试最常用的方法就是lr_find(),对于怎么选择slice的范围,大概总结了这几点:
- 最低点左右都有明显的坡度(一般选定学习率之后第一次训练的结果都是这种类型),找左边下降最陡的那一段,一般右端至初始学习率的十分之一至二分之一左右(有1/3有1/5,这个自己选应该问题不大)。
- 最低点左边比较平缓,具有波动但是没有光滑地下降曲线(一般经过调试后的曲线会是这样),取即将上升处的最低点学习率的十分之一为左端,右端至最低点及其三分之一之间(可不取,只输入左端点)
- 类似第二种情况,但曲线始终是一个上升的趋势,没有明显的最低点,左端在基于明显上升起始点缩小100倍左右,右端靠近起始点(图中lr初始值为0.01):
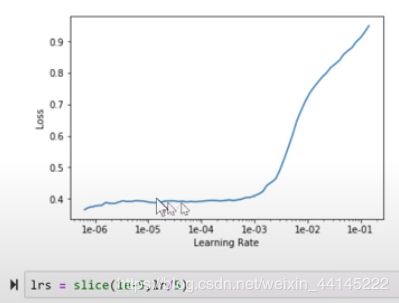
注意:这些都只是能够基本保证模型表现的经验之谈,不是真理。自己多尝试才是王道。
y_range
获得模型处理所需要的y_range对精度也有影响,限定了数据归一化后的取值范围,一般而言相对预测对象稍大一点的范围效果最好
pca
使用pca进行数据降维,从而节省时间并且给予人类认知可分析性。经典案例就是协同过滤优化latent factors。
实战经验
Broken pipe报错
broken pipe,原理未知,十分烦恼,具有劝退能力,第二次课程就碰到了。
预防措施:
- 在imageList之类的数据处理操作前加上
语句进行线程保护,保险起见,可保护到报错broken pipe的语句为止(包括)。之后的代码一般能够正常运行。if __name__ == '__main__': data = ImageFileList ...
出错后的处理措施:
- 迅速将代码加入代码保护的语句块中。如果仍然报错,重启电脑吧,不然多运行几次电脑可能就帮你重启了。。。
GPU内存溢出
由于pytorch的缓存机制,数据加载以及每一次的训练都会占用GPU内存,所以如果你连续训练,很有可能会出现GPU内存不够的情况,由于深度学习往往需要不断地尝试和调试,出现这种情况意味着你的模型半途而废了,很烦人,本人10875h + 2070super(8G)出现过不少这种问题。
google和百度都没有很好的,明确的释放缓存的解决方案,尝试过过各种kill,del,no_grad,clean_cache()都没用。于是自己另外总结了解决方法:
- 课堂上对这个问题的答案就是减小bs,batch size。没错这是个好方法,可是8G理论上bs=32是没问题的,有些问题却要调到bs=8,太浪费了。
- 课堂上提高的另一种方法涉及到了释放显存,那就是设置占用内存的对象(一般是learner)为None,然后运行gc.collect()收集垃圾缓存,从而释放部分内存。
- 另外就是自己尝试总结的方法。很简单,重启:先shutdown笔记本,重启jupyter notebook,不行再重启电脑。使用前提是分离出模型分离和调试的代码,每完成一次训练就save,出现错误了就export,然后重启后运行库的引入和数据处理代码,读取模型再战。这种方法其实比降低bs要省时。
大概就总结出了这两种方法,希望有人能够发现更好的解决方案。
jargon
- discriminative learning
- affine function - 映射函数:联想矩阵相乘,得到的线性函数
- n-embedding:想使用one-hot-encoding但是不需要实现one-hot-encoding而是用n-embedding来实现one-hot-encoding即数组查找。。。
- latent factors- 潜在因子:不明显包含于数据中但是通过深度学习可以发现的特征,不需要人为定义,相当于神经网络中的权重。然后使用偏置来对整体进行一个评价。在协同过滤中,item和user对象的latent factors长度相同。注意协同过滤对于latent factors(weights)和bias的分析是很重要的,因为它们都有明确的现实意义。
- average-pooling-平均汇聚:将多channel的三维张量对长宽平面矩阵各元素取均值来降至一维。其实每个长宽平面矩阵代表的都是对象的某个特征,而其均值则是对象中包含此特征的成分。
- identity function-skip connection: Deep Residual Learning for Image Recognition, 属于Res block。
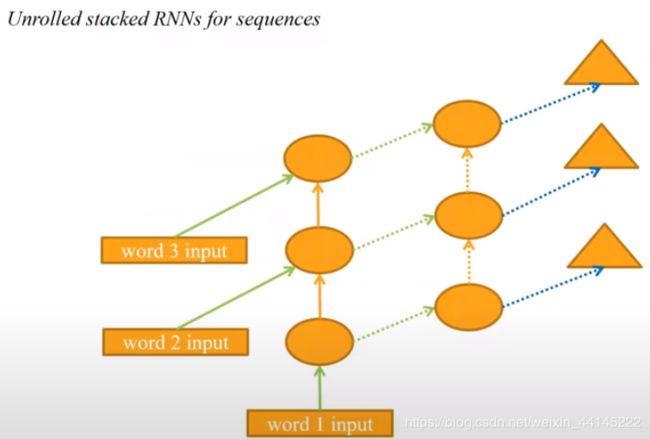
RNN
协同过滤
基于表格数据的训练方法,往往用于推荐系统当中
现实中的协同过滤面临着冷启动问题,即面对新用户和新对象无法进行训练,解决方法通常有三种:
- 数据补充:推荐平均值或者较好表现的对象。
- 用户体验UX:就是一开始就让你选什么喜欢什么不喜欢的那种。
- 获取源数据:根据新用户或对象已有的数据,如地理位置、年龄、性别、导演、演员等。