数据结构学习总结(六)图
文章目录
- 1. 图的定义
- 1.1 各种图定义
- 1.2 图的顶点与边间关系
- 1.3 联通图相关术语
- 1.4 连通图的生成树
- 2. 图的抽象数据类型
- 3. 图的存储结构
- 3.1 邻接矩阵
- 3.2 邻接表
- 3.3 十字链表
- 3.4 邻接多重表
- 3.5 边集数组
- 4. 图的遍历
- 4.1 深度优先遍历
- 4.2 广度优先遍历
- 5. 图的应用
- 5.1 最小生成树
- 5.1.1 普里姆(Prim)算法
- 5.1.2 克鲁斯卡尔(Kruskal)算法
- 5.2 最短路径
- 5.2.1 迪杰斯特拉(Dijkstra)算法
- 5.2.2 弗洛伊德(Floyd)算法
- 5.3 有向无环图
- 5.3.1 拓扑排序
- 5.3.2 关键路径
1. 图的定义
图(Graph)是由顶点的有穷非空集合和顶点之间的边组成,通常表示为:G(V,E),其中,G 表示一个图,V 是图 G 中顶点的集合,E 是图 G 中边的集合。
- 线性表中将数据元素叫元素,树中将数据元素叫结点,在图中数据元素称之为顶点(Vertex)。
- 顶点集合 V 有穷非空。
- 图中,任意两个顶点之间都可能有关系,顶点之间的逻辑关系用边来表示,边集可以是空的。
1.1 各种图定义
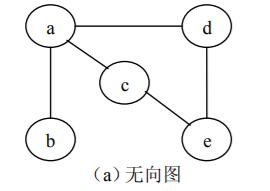
无向边:若顶点 vi 到 vj 之间的边没有方向,则称这条边为无向边(Edge),用无序偶对(vi,vj)来表示。 如果图中任意两个顶点之间的边都是无向边,则称该图为无向图。对于下图无向图 G1 来说,G1=(V1,E1),其中顶点集合 V1={a,b,c,d,e};边集合 E1={ (a,b),(a,d),(a,c),(c,e),(d,e) }
在无向图中,如果任意两个顶点之间都存在边,则称该图为无向完全图。
有向边:若顶点 vi 到 vj 之间的边有方向,则称这条边为有向边,也称为弧(Arc),用有序偶对
在有向图中,如果任意两个顶点之间都存在方向互为相反的两条弧,则称该图为有向完全图。

简单图:在图中,若不存在顶点到自身的边,且同一条边不重复出现,则称这样的图为简单图。
有很少条边的图称为稀疏图,反之称为稠密图。这里的稀疏和稠密是模糊的概念,都是相对而言的。
有些图的边或弧具有与它相关的数字,这种与图的边或弧相关的数叫做权(Weight)。这些权可以表示从一个顶点到另一个顶点的距离或耗费。这种带权的图通常称为网(Network)。
设图 G = (V,E) 和图 G’ = (V’,E’)。如果 V’ ⊆ V 且 E’ ⊆ E,则称 G’ 是 G 的一个子图(Subgraph)。如果 V’ = V 且 E’ ⊆ E,则称 G’是 G 的一个生成子图(Spanning Subgraph)。

1.2 图的顶点与边间关系
对于无向图 G = (V,E),如果边 (u,v) ∈ E,则称顶点 u 与顶点 v 互为邻接点。边 (u,v) 依附于顶点 u 和 v,或者说边 (u,v) 与顶点 u 和 v 相关联。顶点 v 的度(Degree)是和 v 相关联的边的数目。记为 TD(v)。例如在上图(a)所示的无向图中,边 (a,b) 依附于顶点 a 与 b 上,TD(a) = 3,TD(c) = TD(d) = TD(e) = 2,TD(b) = 1。而此图的边数是 5,各个顶点度的和: 3+2+2+2+1=10,经过分析后发现,边数就是各顶点度数和的一半,记为 E = ( ∑ i = 1 n T D ( v i ) ) / 2 E = (\sum_{i=1}^n TD(v_i) ) / 2 E=(∑i=1nTD(vi))/2。
对于有向图 G = ( V,E ),如果弧
图中的一条通路或路径(Path),就是由 m+1 个顶点与 m 条边交替构成的一个序列 ρ = { v0,e1,v1,e2,v2,…,em,vm },m ≥ 0,且 ei = (vi-1,vi),1 ≤ i ≤ m。路径上边的数目称为路径长度,记作 |ρ|。
长度 |ρ| ≥ 1 的路径,若路径的第一个顶点与最后一个顶点相同,则称之为环路或环 (Cycle)。
如果组成路径 ρ 的所有顶点各不相同,则称之为简单路径(Simple Path);如果在组成环的所有顶点中,除首尾顶点外均各不相同,则称该环为简单环路(Simple Cycle)。例如下图中左图是简单环而右图,由于顶点 C 的重复,它就不是简单环了。
1.3 联通图相关术语
在无向图 G 中,如果顶点 v 到顶点 v’ 有路径,则称 v 和 v’ 是连通的。如果对于图中任意两个顶点 vi、vj ∈ V,vi 和 vj 都是连通的,则称 G 是连通图(Connected Graph)。无向图中的极大连通子图称为连通分量。
注意连通分量的概念,他强调:
1、要是子图;
2、子图要是连通的;
3、连通子图含有极大顶点数;
4、具有极大顶点数的连通子图包含依附于这些顶点的所有边。
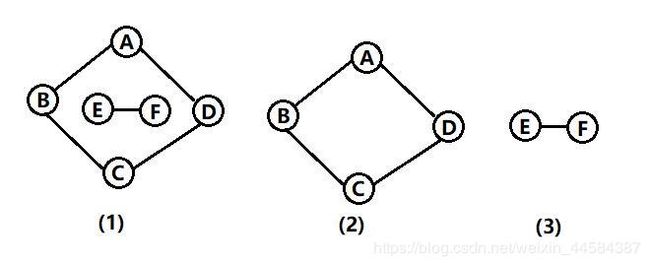
例如,下图(1)不是连通图,而图(2)和(3)是图(1)的两个连通分量。
在有向图 G 中,如果对于每一对 vi、vj ∈ V,vi ≠ vj ,从 vi 到 vj 和从 vj 到 vi 都存在路径,则称 G 是强连通图。有向图中的极大强连通子图称为强连通分量。
例如,下图(a)并不是强连通图,因为顶点 b 到顶点 a 路径不存在。图(b)就是强连通图,而且是图(a)的强连通分量。

1.4 连通图的生成树
连通图的生成树是一个极小的连通子图,它含有图中全部的 n 个顶点,但只有足以构成一棵树的 n-1 条边。比如下图 1 是一普通图,但显然它不是生成树,当去掉两条构成环的边后,比如图 2 ,就满足 n 个顶点,n-1 条边且连通的定义了,因此图 2 是一颗生成树。如果一个图有 n 个顶点和小于 n-1 条边,则是非连通图,如果它多于 n-1 条边,必定构成一个环。不过有 n-1 条边并不一定是生成树。

如果一个有向图恰有一个顶点的入度为 0,其余顶点的入度均为 1,则是一颗有向树。所谓入度为 0 其实就相当于树中的根结点,其余顶点入度为 1 就是说树中的非根节点的双亲只有一个。一个有向图的生成森林由若干颗有向树组成,含有图中全部顶点,但只有足以构成若干颗不相交的有向树的弧。如图 1 是一颗有向图。去掉一些弧后,它可以分解为两颗有向树,如图 2 和图 3 ,这两颗就是图 1 有向图的生成森林。

2. 图的抽象数据类型
ADT 图(Graph)
Data 顶点的有穷非空集合和边的集合
Operation:
CreateGraph(): 图的创建操作。
GetVex(G, v): 求图中的顶点v的值。
… …
DFSTraverse(G, V): 对图G深度优先遍历,每个顶点访问且只访问一次。
BFSTraverse(G, V): 对图G广度优先遍历,每个顶点访问且只访问一次。
end ADT
3. 图的存储结构
3.1 邻接矩阵
图的邻接矩阵(Adjacency Matrix)存储方式是用两个数组来表示图。一个一维数组存储图中顶点信息,一个二维数组(称为邻接矩阵)存储图中的边或弧的信息。
假设图 G=(V,E) 有 n 个顶点,即 V={ v0,v1,…,vn-1 },则邻接矩阵是一个 n×n 的方阵,定义为:
a r c [ i ] [ j ] = { 1 <u,v>或(u,v)∈E ∞ 反之 arc[i][j]= \begin{cases} 1& \text{<u,v>或(u,v)∈E}\\ \infty& \text{反之} \end{cases} arc[i][j]={1∞
下图中两个图的邻接矩阵分别为:
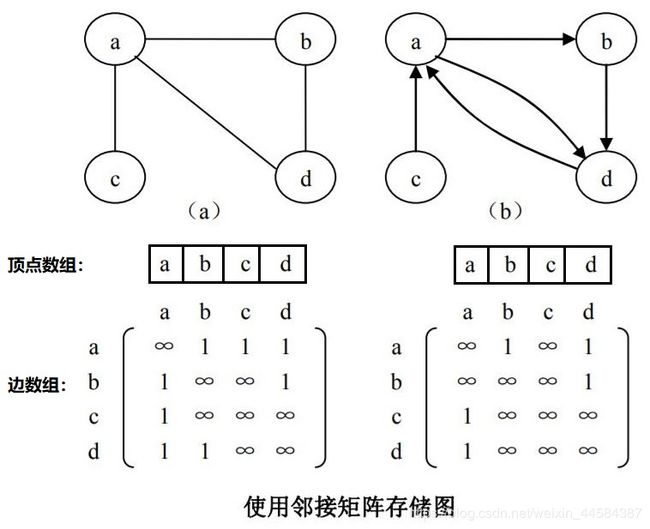
并且,此时顶点 a、b、c、d 在存储顶点的数组中所对应的下标分别为 0、1、2、3。
实际上这一表示形式也可以推广至带权图,若图 G 是网图,有 n 个顶点,则它的邻接矩阵是一个 n×n 的方阵阵,定义为:
a r c [ i ] [ j ] = { W i j <u,v>或(u,v)∈E ∞ 反之 arc[i][j]= \begin{cases} W_{ij}& \text{<u,v>或(u,v)∈E}\\ \infty& \text{反之} \end{cases} arc[i][j]={Wij∞
下图给出了一个有向网图和它的邻接矩阵。
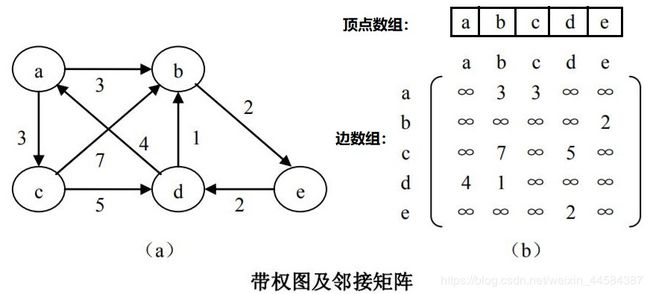
从图的邻接矩阵存储方法容易看出:首先,无向图的邻接矩阵一定是一个对称矩阵。因此,在具体存放邻接矩阵时只需存放上(或下)三角矩阵的元素即可。其次,对于无向图,邻接矩阵的第 i 行(或第 i 列)非 ∞ 元素的个数正好是第 i 个顶点的度 TD(vi)。再次,对于有向图,邻接矩阵的第 i 行(第 i 列)非 ∞ 元素的个数正好是第 i 个顶点的出度 OD(vi)(入度 ID(vi))。最后,通过邻接矩阵很容易确定图中任意两个顶点之间是否有边相连;但是,要确定图中有多少条边,则必须按行、按列对每个元素进行检测,所花费的时间代价很大。
从空间上看,不论顶点 u、v 之间是否有边,在邻接矩阵中都需预留存储空间,因为每条边所需的存储空间为常数,所以邻接矩阵需要占用 O(n2) 的空间,这一空间效率较低。具体来说,邻接矩阵的不足主要在两个方面。首先,尽管由 n 个顶点构成的图中最多可以有n2条边,但是在大多数情况下,边的数目远远达不到这个量级,因此,在邻接矩阵中大多数单元都是闲置的。其次,矩阵结构是静态的,其大小 N 需要预先估计,然后创建 N×N 的矩阵。然而,图的规模往往是动态变化的,N 的估计过大会造成更多的空间浪费,如果估计过小则经常会出现空间不够用的情况。
3.2 邻接表
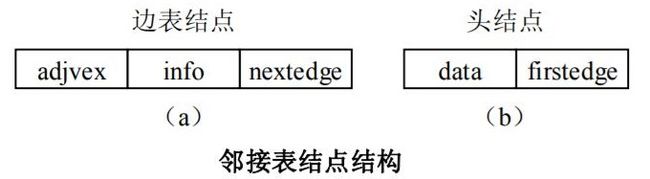
邻接表(Adjacency List)是图的一种链式存储方法,邻接表表示法类似于树的孩子链表表示法。在邻接表中对于图 G 中的每个顶点 vi 建立一个单链表,将所有邻接于 vi 的顶点链成一个单链表,并在表头附设一个表头结点,这个单链表就称为顶点 vi 的邻接表。
在邻接表中共有两种结点结构,分别是边表结点和表头结点。每个边表结点由 3 个域组成,如图(a)所示。其中邻接点域(adjvex)指示与顶点 vi 邻接的顶点在图中的位置,链域(nextedge)指向下一条边所在的结点,数据域(info)存储和边有关的信息,如权值等信息。在头结点中,结构如图(b)所示,除了设有链域(firstedge)指向链表中的第一个结点之外,还有用于存储顶点 vi 相关信息的数据域(data)。
这些表头结点(可以链接在一起)以顺序的结构形式进行存储,以便随机访问任一顶点的链表。下图给出了图的邻接表存储示例。

就存储空间而言,对于 n 个顶点、m 条边的无向图,若采用邻接表作为存储结构,则需要 n 个表头结点和 2m 个边表结点。显然在边稀疏的情况下,用邻接表存储要比使用邻接矩阵节省空间。
在无向图的邻接表中,顶点 vi 的度恰为顶点 vi 的邻接表中边表结点的个数;而在有向图中,顶点 vi 的邻接表中边表结点的个数仅为顶点 vi 的出度,为求顶点 vi 的入度必须遍历整个邻接表。在所有链表中其邻接点域的值指向 vi 的位置的结点个数是顶点 vi 的入度。为了方便求得有向图中顶点的入度,可以建立一个有向图的逆邻接表,如图(e)所示。
在邻接表中容易找到一个顶点的邻接点,但是要判定两个顶点 vi 和 vj 之间是否有边,则需要搜索顶点 vi 或顶点 vj 的邻接表,与邻接矩阵相比不如邻接矩阵方便。
3.3 十字链表
十字链表(Orthogonal List)是有向图的另一种链式存储结构,是将有向图的邻接表和逆邻接表结合起来得到的一种链表。

◆ data 域:存储和顶点相关的信息;
◆ 指针域 firstin:指向以该顶点为弧头的第一条弧所对应的弧结点;
◆ 指针域 firstout:指向以该顶点为弧尾的第一条弧所对应的弧结点;
◆ 尾域 tailvex:指示弧尾顶点在图中的位置;
◆ 头域 headvex:指示弧头顶点在图中的位置;
◆ 指针域 headlink:指向弧头相同的下一条弧;
◆ 指针域 taillink:指向弧尾相同的下一条弧;
如果是网,还可以再增加一个 weight 域来存储权值。
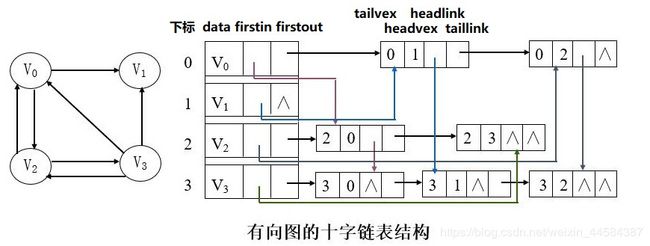
从这种存储结构图可以看出,从一个顶点结点的 firstout 出发,沿表结点的 taillink 指针构成了邻接表的链表结构,而从一个顶点结点的 firstin 出发,沿表结点的 headlink 指针构成了逆邻接表的链表结构。
关于十字链表的理解也可以参考博客 https://blog.csdn.net/WR_technology/article/details/51909432
3.4 邻接多重表
邻接多重表(Adjacency Multilist)是无向图的另一种链式存储结构。邻接多重表的结构和十字链表类似,每条边用一个结点表示;邻接多重表中的顶点结点结构与邻接表中的完全相同,而表结点结构如下图所示。

◆ data 域:存储和顶点相关的信息;
◆ 指针域 firstedge:指向依附于该顶点的第一条边所对应的表结点;
◆ ivex 和 jvex 域:分别保存该边所依附的两个顶点在图中的位置;
◆ 指针域 ilink:指向下一条依附于顶点 ivex 的边;
◆ 指针域 jlink:指向下一条依附于顶点 jvex 的边。

邻接多重表与邻接表的差别,仅仅是在于同一条边在邻接表中用两个结点表示,而在邻接多重表中只有一个结点。这样对边的操作就方便多了。
3.5 边集数组
边集数组是由两个一维数组构成。一个是存储顶点信息;另一个是存储边的信息,这个边数组每个数据元素由一条边的起点下标(begin)、终点下标(end)和权(weight)组成。

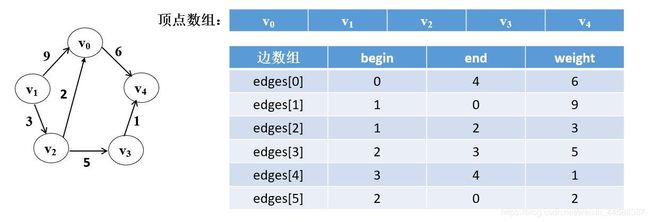
4. 图的遍历
从图中某一顶点出发访遍图中其余顶点,且使每一个顶点仅被访问一次,这一过程就叫做图的遍历(Traversing Graph)。
4.1 深度优先遍历
深度优先搜索(Depth First Search)遍历类似于树的先序遍历,是树的先序遍历的推广,简称为 DFS。
深度优先搜索的基本方法是:从图中某个顶点发 v 出发,访问此顶点,然后依次从 v 的未被访问的邻接点出发深度优先遍历图,直至图中所有和 v 有路径相通的顶点都被访问到;若此时图中尚有顶点未被访问,则另选图中一个未曾被访问的顶点作起始点,重复上述过程,直至图中所有顶点都被访问到为止。

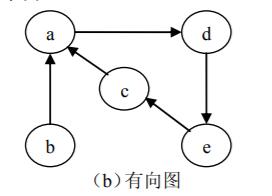
以上图(a)中无向图为例,对其进行深度优先搜索遍历的过程如图(c)所示,其中黑色的实心箭头代表访问方向,空心箭头代表回溯方向,箭头旁的数字代表搜索顺序,顶点 a 是起点。遍历过程如下:首先访问顶点 a,然后
a) 顶点 a 的未曾访问的邻接点有 b、d、e,选择邻接点 b 进行访问;
b) 顶点 b 的未曾访问的邻接点有 c、e,选择邻接点 c 进行访问;
c) 顶点 c 的未曾访问的邻接点有 e、f,选择邻接点 e 进行访问;
d) 顶点 e 的未曾访问的邻接点只有 f,访问 f;
e) 顶点 f 无未曾访问的邻接点,回溯至 e;
f) 顶点 e 无未曾访问的邻接点,回溯至 c;
g) 顶点 c 无未曾访问的邻接点,回溯至 b;
h) 顶点 b 无未曾访问的邻接点,回溯至 a;
i) 顶点 a 还有未曾访问的邻接点 d,访问 d;
j) 顶点 d 无未曾访问的邻接点,回溯至 a。
到此,a 再没有未曾访问的邻接点,也不能向前回溯,从 a 出发能够访问的顶点均已访问,并且此时图中再没有未曾访问的顶点,因此遍历结束。由以上过程得到的遍历序列为:a,b,c,e,f,d。
对于有向图而言,深度优先搜索的执行过程一样,例如上图(b)中有向图的深度优先搜索过程如图(d)所示。在这里需要注意的是从顶点 a 出发深度优先搜索只能访问到 a , b , c , e , f,而无法访问到图中所有顶点,所以搜索需要从图中另一个未曾访问的顶点 d 开始进行新的搜索,即图(d)中的第 9 步。
4.2 广度优先遍历
广度优先搜索(Breadth First Search)遍历类似于树的层序遍历,它是树的按层遍历的推广,简称为 BFS。 例如下图中,将第一幅图稍微变形成第二幅图,这样就比较有层次感,此时在视觉上图的形状发生了改变,其实顶点和边的关系还是完全相同的。

DFS 与 BFS Java 代码
package graph;
import java.util.ArrayList;
import java.util.LinkedList;
public class AMWGraph {
private ArrayList vertexList;// 存储顶点的链表
private int[][] edges;// 邻接矩阵,用来存储边
private int numOfEdges;// 边的数目
boolean[] isVisited;
public AMWGraph(int n) {
// 初始化矩阵,一维数组,和边的数目
edges = new int[n][n];
vertexList = new ArrayList(n);
numOfEdges = 0;
}
// 得到结点的个数
public int getNumOfVertex() {
return vertexList.size();
}
// 得到边的数目
public int getNumOfEdges() {
return numOfEdges;
}
// 返回结点i的数据
public Object getValueByIndex(int i) {
return vertexList.get(i);
}
// 返回v1,v2的权值
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
// 插入结点
public void insertVertex(Object vertex) {
vertexList.add(vertexList.size(), vertex);
}
// 插入结点
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
numOfEdges++;
}
// 删除结点
public void deleteEdge(int v1, int v2) {
edges[v1][v2] = 0;
numOfEdges--;
}
// 得到第一个邻接结点的下标
public int getFirstNeighbor(int index) {
for (int j = 0; j < vertexList.size(); j++) {
if (edges[index][j] > 0) {
return j;
}
}
return -1;
}
// 根据前一个邻接结点的下标来取得下一个邻接结点
public int getNextNeighbor(int v1, int v2) {
for (int j = v2 + 1; j < vertexList.size(); j++) {
if (edges[v1][j] > 0) {
return j;
}
}
return -1;
}
// 私有函数,深度优先遍历
private void depthFirstSearch(boolean[] isVisited, int i) {
// 首先访问该结点,在控制台打印出来
System.out.print(getValueByIndex(i) + " ");
// 置该结点为已访问
isVisited[i] = true;
int w = getFirstNeighbor(i);
while (w != -1) {
if (!isVisited[w]) {
depthFirstSearch(isVisited, w);
}
w = getNextNeighbor(i, w);
}
}
// 对外公开函数,深度优先遍历,与其同名私有函数属于方法重载
public void depthFirstSearch() {
isVisited = new boolean[vertexList.size()];
for (int i = 0; i < getNumOfVertex(); i++) {
// 因为对于非连通图来说,并不是通过一个结点就一定可以遍历所有结点的。
if (!isVisited[i]) {
depthFirstSearch(isVisited, i);
}
}
}
// 私有函数,广度优先遍历
private void broadFirstSearch(boolean[] isVisited, int i) {
int u, w;
LinkedList queue = new LinkedList();
// 访问结点i
System.out.print(getValueByIndex(i) + " ");
isVisited[i] = true;
// 结点入队列
queue.addLast(i);
while (!queue.isEmpty()) {
u = ((Integer) queue.removeFirst()).intValue();
w = getFirstNeighbor(u);
while (w != -1) {
if (!isVisited[w]) {
// 访问该结点
System.out.print(getValueByIndex(w) + " ");
// 标记已被访问
isVisited[w] = true;
// 入队列
queue.addLast(w);
}
// 寻找下一个邻接结点
w = getNextNeighbor(u, w);
}
}
}
// 对外公开函数,广度优先遍历
public void broadFirstSearch() {
isVisited = new boolean[vertexList.size()];
for (int i = 0; i < getNumOfVertex(); i++) {
if (!isVisited[i]) {
broadFirstSearch(isVisited, i);
}
}
}
public static void main(String args[]) {
int n = 8, e = 9;// 分别代表结点个数和边的数目
String labels[] = { "1", "2", "3", "4", "5", "6", "7", "8" };// 结点的标识
AMWGraph graph = new AMWGraph(n);
for (String label : labels) {
graph.insertVertex(label);// 插入结点
}
// 插入九条边
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
graph.insertEdge(1, 0, 1);
graph.insertEdge(2, 0, 1);
graph.insertEdge(3, 1, 1);
graph.insertEdge(4, 1, 1);
graph.insertEdge(7, 3, 1);
graph.insertEdge(7, 4, 1);
graph.insertEdge(6, 2, 1);
graph.insertEdge(5, 2, 1);
graph.insertEdge(6, 5, 1);
System.out.println("深度优先搜索序列为:");
graph.depthFirstSearch();
System.out.println();
System.out.println("广度优先搜索序列为:");
graph.broadFirstSearch();
}
}
5. 图的应用
5.1 最小生成树
在图的定义那一小节曾提到过,连通图的生成树是一个极小的连通子图,它含有图中全部的 n 个顶点,但只有足以构成一棵树的 n-1 条边,如此,对于一个连通网(连通带权图)来说,生成树不同,每棵树的代价(树中每条边上权值之和)也可能不同,我们把代价最小的生成树称为图的最小生成树(Minimum Spanning Tree)。
最小生成树在许多领域都有重要的应用,例如利用最小生成树就可以解决如下工程中的实际问题:网络 G 表示 n 个城市之间的通信线路网,其中顶点表示城市,边表示两个城市之间的通信线路,边上的权值表示线路的长度或造价。可通过求该网络的最小生成树达到求解通信线路长度或总代价最小的最佳方案。
需要进一步指出的是,尽管最小生成树必然存在,但不一定唯一。
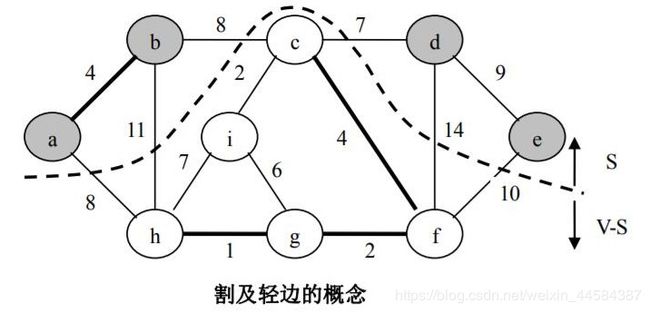
在介绍下面的算法之前,我们先介绍几个概念。无向图 G = (V,E) 中,(S,V - S) 是对顶点集的一个划分。下图说明了这个概念。当边 (u,v)∈E 的一个顶点在 S 中,而另外一个顶点在 V - S 中,我们说边 (u,v) 横切割 (S,V - S)。在横切割的所有边中,权最小的边称为轻边。需要注意的是横切割的轻边可能不止一条。例如图 7-17 中边 (a,h)、(b,h)、(b,c)、(d,c)、(d,f)、(e,f) 横切割 (S,V - S),其中 (d,c) 是轻边。
5.1.1 普里姆(Prim)算法
此算法可以称为“加点法”,每次迭代选择代价最小的边对应的点,加入到最小生成树中。假设 G = (V,E) 是连通网,A 是 G 上最小生成树的边的集合。算法从 S = { u0 }(u0∈V),A = { } 开始,重复执行下述操作:找到横切割 (S,V - S) 的轻边 (u0,v0) 并入集合 A,同时 v0 并入 S,直到 S = V 为止。
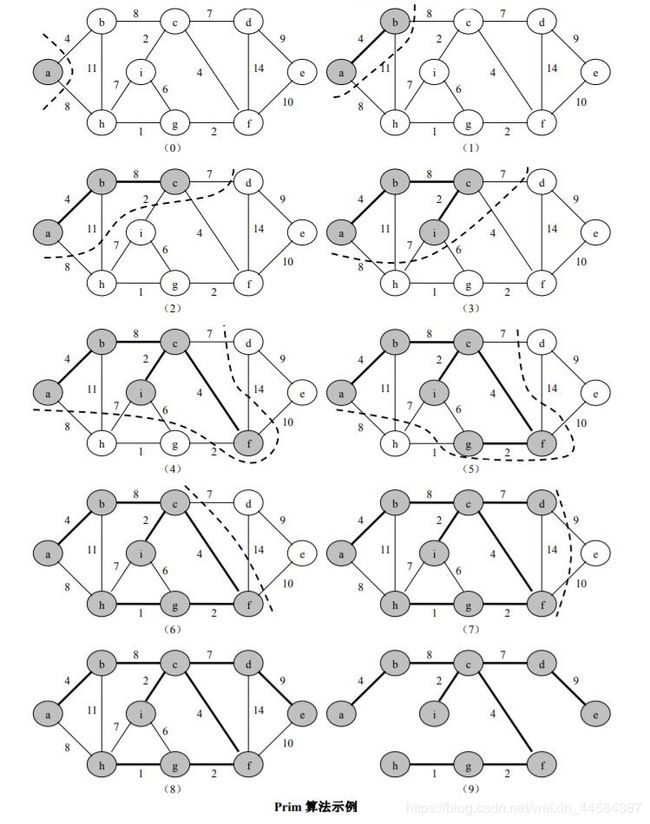
在上图所示的构造最小生成树过程中,横切割 (S,V - S) 的边会随着新加入 S 的顶点 k 变化而变化。为找到横切割 (S,V - S) 的轻边,可以转化为如下操作:求出从 S 中顶点到达 V - S 中各个顶点的最短横切边,轻边是这些最短横切边中最小的一个。例如图(4)中,当 S = { a,b,c,i } 时,到达 V - S 中每个顶点的最短横切边是:(c,d) = 7、(c,f) = 4、(i,g) = 6、(i,h) = 7、到 e 为 ∞,横切割 (S,V - S) 的轻边为 (c,f) = 4。
5.1.2 克鲁斯卡尔(Kruskal)算法
此算法可以称为“加边法”,初始最小生成树边数为 0,每迭代一次就选择一条满足条件的最小代价边,加入到最小生成树的边集合里。假设 G = (V,E) 是连通网,则令最小生成树的初始状态为只有 n 个顶点而无边的非连通图,图中每个顶点自成一个连通分量。在 E 中选择权值最小的边,若该边依附的顶点落在 T 中的不同连通分量上,则将此边加入 T 中,否则舍去此边选择下一条代价最小的边。以此类推,直到 T 所有顶点都在同一连通分量上为止。

5.2 最短路径
对于网图来说,最短路径,是指两顶点之间经过的边上权值之和最少的路径,并且称路径上的第一个顶点是源点,最后一个顶点是终点;对于非网图来说,可以理解为权值为 1 的网图。
下面介绍两种求最短路径的算法,Dijkstra 算法和 Floyd 算法,Dijkstra 算法是求图中一个顶点到其他顶点的最短路径而 Floyd 算法是求图中每对顶点之间的最短路径。
5.2.1 迪杰斯特拉(Dijkstra)算法
Dijkstra (迪杰斯特拉) 算法是典型的单源最短路径算法,用于计算一个结点到其他所有结点的最短路径。主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止。问题描述为,在带权图 G = (V,E) 中,已知源点为 v0∈V,求 v0 到其余各顶点的最短路径。
算法思想说明
设给定源点为 V0,S 为已求得最短路径的终点集,开始时令 S = { V0 } 。当求得第一条最短路径 (V0 ,Vi) 后,S 为 { V0,Vi } 。根据以下结论可求下一条最短路径。
设下一条最短路径终点为 Vj,则 Vj 只有:
◆ 源点到终点有直接的弧
◆ 从 V0 出发到 Vj 的这条最短路径所经过的所有中间顶点必定在 S 中。即只有这条最短路径的最后一条弧才是从 S 内某个顶点连接到 S 外的顶点 Vj 。
◆ 定义数组 dist[v] 表示 v0 到 v 的最短路径长度和;数组 pre[v] 的值为前驱顶点的下标,例如若 pre[v] = k,表示从 v0 到 v 的最短路径中,v 的前一个顶点是 vk,即最短路径序列是 (v0,…,vk,v) ;数组 final[w],标识一个顶点 vw 是否已加入 S 中,如果为 1,则表示已加入,为 0,则表示未加入。
例如,求下图中源点 v0 到各个顶点的最短路径。
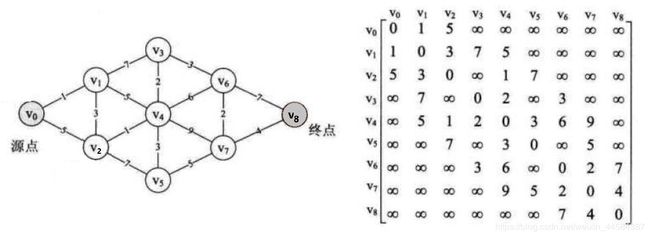
- 刚开始 final 数组为 { 1,0,0,0,0,0,0,0,0 },表示 v0 已加入集合 S 中;dist 数组为 { 0,1,5,∞,∞,∞,∞,∞,∞ },因为 v0 与 v1 和 v2 的边权值为 1 和 5;pre 数组全为 0,表示目前没有路径;集合 S = { v0 } 。
- 根据 dist[1] =1 可得最短距离是 1,将 v1 加入到集合 S 中,此时 S = { v0,v1 },final[1] = 1,pre[1] = 0 。
- 在 v0 与 v1 的最短路径的基础上,对 v1 与其他顶点的边进行计算,得到 v0 与它们的当前最短距离。v0→v1→v2 = 4 < dist[2] = 5,所以更新 dist[2] = 4,pre[2] = 1;v0→v1→v3 = 8 < dist[3] = ∞,所以更新 dist[3] = 8,pre[3] = 1;v0→v1→v4 = 6 < dist[4] = ∞,所以更新 dist[4] = 6,pre[4] = 1;最后得 dist 数组当前值为 { 0,1,4,8,6,∞,∞,∞,∞ },pre 数组为 { 0,0,1,1,1,0,0,0,0 } 。
- 根据 dist[2] = 4,可得最短距离是 4(因为 final[0] = 1 和 final[1] = 1,所以 dist[0] 与 dist[1] 不参与比较)。因此将 v2 加入到 集合 S 中,此时 S = { v0,v1,v2 },final[2] = 1,此时 final 数组为 { 1,1,1,0,0,0,0,0,0 } 。
- 在 v0 与 v2 的最短路径的基础上,对 v2 与其他顶点的边进行计算,得到 v0 与它们的当前最短距离。v0→v2→v4 = 5 < dist[4] = 6,所以更新 dist[4] = 5,pre[4] = 2;v0→v2→v5 = 11 < dist[5] = ∞,所以更新 dist[5] = 11,pre[5] = 2;最后得 dist 数组当前值为 { 0,1,4,8,5,11,∞,∞,∞ };pre 数组为 { 0,0,1,1,2,2,0,0,0 } 。注意:这里的 v0→v2 指的是 v0 到 v2 的最短路径。
- 根据 dist[4] = 5,可得最短距离是 5,将 v4 加入到 集合 S 中,此时 S = { v0,v1,v2,v4 },final[4] = 1,此时 final 数组为 { 1,1,1,0,1,0,0,0,0 } 。
- 以此类推。。。
- 最终 final 全为 1;dist 数组为 { 0,1,4,7,5,8,10,12,16 },它表示 **v0**到各个顶点的最短路径数,比如 dist[8] = 1+3+1+2+3+2+4 = 16;pre 数组为 { 0,0,1,4,2,4,3,6,7 },pre[8] = 7,它表示要查看 v0 到 v8 的最短路径时,顶点 v8 的前驱是 v7,再由 pre[7] = 6 表示要查看 v0 到 v7 的最短路径时,顶点 v7 的前驱是 v6,同理,pre[6] = 3 表示 v6 的前驱是 v3。这样就可以得到:v0 到 v8 最短路径为 v0→v1→v2→v4→v3→v6→v7→v8 。
5.2.2 弗洛伊德(Floyd)算法
Floyd 算法是解决任意两点间的最短路径的一种算法,可以正确处理有向图或负权的最短路径问题,同时也被用于计算有向图的传递闭包。Floyd 算法的时间复杂度为O(n3),空间复杂度为O(n2)。
算法思想原理:
Floyd 算法是一个经典的动态规划算法。用通俗的语言来描述的话,首先我们的目标是寻找从点 i 到点 j 的最短路径。从动态规划的角度看问题,我们需要为这个目标重新做一个诠释(这个诠释正是动态规划最富创造力的精华所在)
从任意结点 i 到任意结点 j 的最短路径不外乎两种可能,一是直接从 i 到 j,二是从 i 经过若干个结点 k 到 j。所以,我们假设 dist(i,j) 为结点 u 到结点 v 的最短路径的距离,对于每一个结点 k,我们检查 dist(i,k) + dist(k,j)<dist(i,j) 是否成立,如果成立,证明从 i 到 k 再到 j 的路径比 i 直接到 j 的路径短,我们便设置 dist(i,j) = dist(i,k) + dist(k,j),这样一来,当我们遍历完所有结点 k,dist(i,j) 中记录的便是 i 到 j 的最短路径的距离。
算法描述:
a. 从任意一条单边路径开始。所有两点之间的距离是边的权,如果两点之间没有边相连,则权为无穷大。
b. 对于每一对顶点 u 和 v,看看是否存在一个顶点 w 使得从 u 到 w 再到 v 比己知的路径更短。如果是更新它。
Floyd 算法过程矩阵的计算——十字交叉法
方法:两条线,从左上角开始计算一直到右下角,如下所示
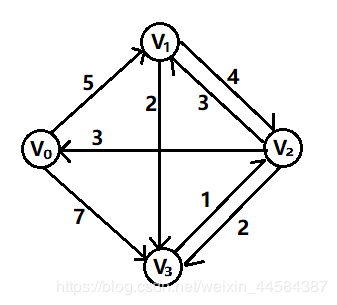
给出矩阵,其中矩阵 A 是邻接矩阵,而矩阵 Path 记录 u,v 两点之间最短路径所必须经过的点



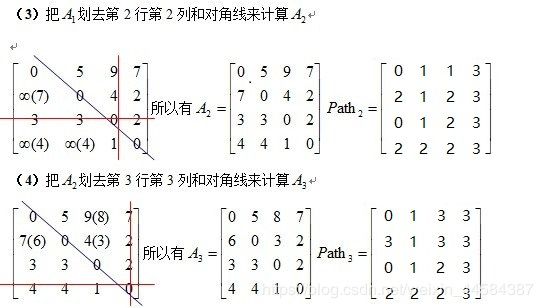
最后 A3、Path3 即为所求。
那么如何由 Path 这个路径数组得出具体的路径呢?以 v1 到 v0 为例,从图中可得,Path[1][0] = 3,得到要经过顶点 v3,然后将 3 取代 1 得到 Path[3][0] = 2,说明要经过顶点 v2,…,这样很容易就推导出最终的最短路径值为 v1→v3→v2→v0 。
注:Floyd 算法参考 https://www.cnblogs.com/biyeymyhjob/archive/2012/07/31/2615833.html
5.3 有向无环图
有向无环图(Directed Acyclic Graph) 是指一个无环的有向图,简称 DAG。有向无环图是描述一项工程或系统进行过程的有效工具。除最简单的情况之外,几乎所有的工程都可分为若干个称做活动(Activity) 的子工程,而这些子工程之间,通常受着一定条件的约束,如其中某些子工程的开始必须在另一些子工程完成之后。
对整个工程和系统,人们关心的是两个方面的问题:一是能否顺利进行,应该如何进行;二是估算整个工程完成所必须的最短时间,对应于有向图,即为进行拓扑排序和求关键路径的操作。
5.3.1 拓扑排序
如果在一个有向图 G =
例如,一件商品的生产就是一项工程,它可以用一个 AOV 网络来表示,如图(a)所示。假设该商品的生产包含 4 项活动:
a. 购买原材料;
b. 生产零件 1;
c. 用零件 1 加工零件 2;
d. 生产零件 3;
e. 组装零件 2、3 得到成品。
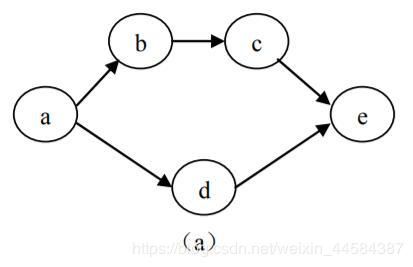
拓扑排序(Topological Sort) 即将 AOV 网络各个顶点 (代表各个活动)排列成一个线性有序的序列,使得 AOV 网络中所有应存在的前驱和后继关系都能得到满足。故拓扑排序就是构造 AOV 网络顶点的拓扑有序序列的运算。
在一个 AOV 网中是不能存在环的,因为如果存在环,说明某项活动的开始必须是以自身的结束作为前提的。需要注意的是 AOV 网的拓扑序列不是唯一的,例如上图中 AOV 网的拓扑序列可以是 a b c d e,也可以是 a d b c e。
为得到 AOV 网的拓扑序列,可以使用以下方法:
(1)从 AOV 网中选一个入度为 0 的顶点,并输出之;
(2)从图中删去该顶点,并删除以此顶点为尾的弧;
(3)重复以上(1)、(2)步, 直到输出全部顶点,或者 AOV 网中不存在入度为 0 的顶点。
下图为拓扑排序的过程。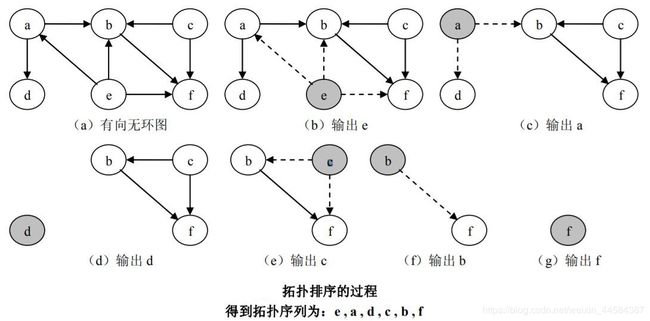
5.3.2 关键路径
与 AOV 网络对应的是边表示活动的 AOE 网络。如果在有向无环的带权图中,用有向边表示一个工程中的各项活动,用边上的权值表示活动的持续时间,用顶点表示事件,则这样的有向图叫做用边表示活动的网络,简称 AOE 网 (Activity On Edge Network)。我们把 AOE 网中没有入边的顶点称为始点或源点,没有出边的顶点称为终点或汇点。由于一个工程只有一个开始点和一个完成点,所以在正常情况下,AOE 网络中只有一个源点和一个汇点。
AOE 网络在某些工程估算方面非常有用。例如,AOE 网络可以使人们了解:(1) 完成整个工程至少需要多少时间,(2) 为缩短完成工程所需的时间,应当加快哪些活动。
例如上图用 AOV 网络表示的工程,可以用下图所示的 AOE 网络表示,并假设活动 a 需时 3 天、活动 b 需时 1 天、活动 c 需时 2 天、活动 d 需时 5 天、活动 e 需时 2 天。在图中我们可以看到,从工程开始到结束,总共至少需要 10 天时间,并且如果能够减少完成活动 a、d、e 所需的时间,则完成整个工程所需的时间可以减少。

我们把路径上各个活动所持续的时间之和称之为路径长度,从源点到汇点具有最大长度的路径叫关键路径,在关键路径上的活动叫做关键活动。图中所示的 AOE 网络中的关键路径为 ρ = (v1,v2,v4,v5),其长度为 10。需要注意的是关键路径可能不只一条。
关键路径算法原理
找到所有活动的最早开始时间和最晚开始时间,并且比较它们,如果相等就意味着此活动是关键活动,活动间的路径为关键路径,否则就不是。
在图 G = { V,E } 中,假设 V = { v0,v1,…,vn-1 },其中 n = |V|,v0 是源点,vn-1是汇点。为求关键活动,我们定义以下变量:
- 事件的最早发生的时间 etv(earliest time of vertex),即顶点 vk 的最早发生时间。
- 事件的最晚发生的时间 ltv(latest time of vertex),即顶点 vk 的最晚发生时间,也就是每个顶点对应的事件最晚需要开始的时间,超出此时间将会延误整个工期。
- 活动最早开工时间 ete(earliest time of edge),即弧 ak 的最早发生时间。设活动 ak 在边
- 活动最晚开工时间 lte(latest time of edge),即弧 ak 的最晚发生时间,也就是不推迟工期的最晚开工时间。设活动 ak 在边
) 。其中,dur() = weight( 是完成 ak 所需的时间。
为找出关键活动,需要求各个活动的 ete[k] 与 lte[k],以判别是否 lte[k] = ete[k]。为求得 ete[k] 与 lte[k],需要先求得从源点 v0 到各个顶点 vi 的 etv[i] 和 ltv[i]。
为求 etv[i] 和 ltv[i] 需分两步进行:
(1)从 etv[0] = 0 开始向汇点方向推进
etv[j] = Max { etv[i] + dur(
(2)从 ltv[n-1] = etv[n-1] 开始向源点方向推进
ltv[i] = Min { ltv[j] - dur(
例如在下图(a)所示的 AOE 网络上求关键活动的过程如图(b)。在图(b)中首先求出了各个顶点的最早开始时间和最迟开始时间,然后求出各个活动的最早开始时间和最迟开始时间,最后活动时间余量为 0 的活动即为关键活动,由关键活动组成的路径是关键路径,即 ρ = (v1,v2,v4,v6) 为关键路径。
