飞桨动态图重大升级,全面提升灵活性、易用性

最新发布的飞桨开源深度学习框架1.7版本,带来多项重要更新。非常值得关注的是,飞桨“动态图”能力有了重大升级,不但编程体验极大提升,而且训练性能已媲美“静态图”,部署能力也有全面强化。
有过深度学习框架编程体验的开发者都知道,目前主要有声明式和命令式两种编程范式,一般被称为静态图模式和动态图模式。相对于静态图模式,动态图类采用“define-by-run”的执行方式,写一行代码即可即时获得结果,在编程体验、调试便捷性等方面有绝佳的优势;而静态图采用先编译后执行的方式,事先定义好整体网络结构再执行,能够对全局编译优化,更有利于性能的提升,也有利于模型的保存和部署。
飞桨作为源于产业实践的深度学习框架,并致力于让深度学习技术的创新与应用更简单,目前同时支持动态图和静态图,兼顾开发的灵活性和高性能。
飞桨开源深度学习框架自1.3版增加动态图功能,1.5版本发布动态图编程范式预览版,经过多个版本的持续完善,目前已经在易用性、运行效率、模型部署能力等方面有很大的增强。飞桨将持续强化编程开发灵活性易用性的同时,保持更强劲的性能优势和全面的部署能力,助力开发者快速实现AI想法、快速上线AI业务。
下面我们就来看看,本次飞桨在动态图方面带来哪些新升级:
深度效率优化,媲美静态图的训练性能
训练性能表现对一个深度学习框架而言非常重要,尤其是在工业生产应用场景中。动态图模式在带来了编程体验提升的同时,也让很多人顾虑它的性能损失问题。飞桨在对动态图支持的实现上,特别考虑到执行效率的优化问题。在1.6版本中,对于很多任务模型,动态图的执行性能已经能和静态图模式相接近。在1.7版本中,进一步对Python与C++交互效率、C++端运行效率等方面做了深度优化,整体训练性能已和静态图图相媲美。即使对于RNN一类的动态图的性能短板任务,飞桨动态图也达到了极高的速度水平。
我们可以看到,在P40环境下,基于LSTM实现的语言模型任务,当下的训练速度相比1.6版本有近三倍的提升。

下面来看一下,本次升级对应的关键技术点:
-
提升Python与 C++交互效率
我们知道,为了保证运行效率,框架底层的运算逻辑都是使用C++实现的,而为了编程的便利性,框架的用户编程接口为Python。在动态图模式下,每一个OP执行时,都需要进行一次Python与C++交互,即将Python端的对象传递给C++端,这相对于静态图模式是一种显著的额外开销。新版本中,优化了Python与C++交互的数据结构,传递的结构更加精简,大大提升了执行效率。
在1.6版本的实现中,动态图的VarBase对象包含在Variable对象当中的,python与c++交互处理的是Variable对象,但是在Python的底层,这种对象保护关系是通过map进行实现的,我们获取或者修改包含的元素,性能都非常的差,在1.7中,我们重新设计了动态图的VarBase对象,python与c++直接传递VarBase对象,节省map的查找和修改开销,从而提高性能。
-
优化C++端运行效率
动态图模式下,每个OP执行时,均需要做一次数据构造,OP运行结束之后进行析构。由于Op中包含了复杂的map等结构,这种结构的构造和析构会都带来很大的开销,在1.7版本中,我们通过框架的优化,移除了这种map的构造和析构。简化数据结构,降低构造开销,由此提升执行效率。
-
【提升运行效率】优化DataLoader,提升整体性能
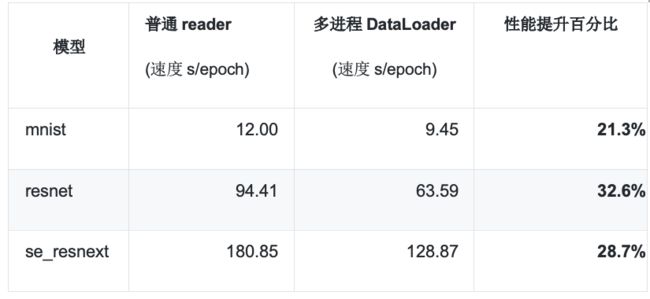
DataLoader虽然不算是动态图核心功能,但却是影响任务整体训练性能的重要因素。由于动态图执行模式下的差异性,对应的DataLoader的设计和实现需要有不同于静态图模式的更多考量。动态图模式下若每个op执行时,都申请python的全局锁(Global Interpreter Lock),会导致异步DataLoader中数据处理的线程效率受到很大影响,如果训练时每个batch的数据量比较大,DataLoader的性能就不如静态图模式下那么高效。为此,飞桨新版本的动态图模式在原来的基础上引入了multi-processing进行数据处理,这种进程间的处理不受全局锁的影响,进而提升执行效率。在resnet,se_resnext等任务上,整体性能提升约30%。
-
优化反向计算策略,删除冗余Tensor空间,降低显存占用。
针对部分OP,在执行反向计算时不依赖正向Tensor值,只依赖Tensor shape的情况,引入策略,删除不需要的Tensor空间,只保留需要的Tensor shape信息,以降低显存占用。在Resnet等任务上,同一个硬件设备上,能够设置最大batch size 提升了20%左右。

强化部署能力,追求极佳产业应用实践
在工业界,深度学习模型的部署是技术落地非常关键的部分。动态图模式采用命令式执行,并使用python原生语法来构建网络的形式,带来灵活性和便利性的同时,对于模型在C++端的自动部署产生了巨大的挑战。因为动态图模式下,没有一个整体的静态的网络结构内部表达,需要将python语法自动映射到C++端。
飞桨在推出动态图编程模式的同时,周密考虑了对训练后部署的支持。针对网络中不包含依赖数据的控制流的模型, 我们提供了基于TracedLayer的方案来将动态图模型转换为静态图的方案,完成自动部署的功能;对于网络中存在依赖数据的控制流模型,飞桨实现了基于python语法解析和重构的技术,可以将python的控制流解释为飞桨控制流op,整体映射为静态图图表达,这种方案将支持绝大部分任务完成推理部署功能,会在下个版本发布。
TracedLayer 使用方法如下:
import paddle.fluid as fluid
from paddle.fluid.dygraph import Linear, to_variable, TracedLayer
import numpy as np
#自动一个Layer
class ExampleLayer(fluid.dygraph.Layer):
def __init__(self):
super(ExampleLayer, self).__init__()
self._fc = Linear(3, 10) # 包含一个Linear层
def forward(self, input):
return self._fc(input)
with fluid.dygraph.guard():
layer = ExampleLayer()
in_np = np.random.random([2, 3]).astype('float32') # 需要一个fake的数据
in_var = to_variable(in_np)
#调用trace方法
out_dygraph, static_layer = TracedLayer.trace(layer, inputs=[in_var])
# 内部使用Executor运行静态图模型
out_static_graph = static_layer([in_var])
print(len(out_static_graph)) # 1
print(out_static_graph[0].shape) # (2, 10)
# 将静态图模型保存为预测模型
static_layer.save_inference_model(dirname='./saved_infer_model')
对于上述操作保存的文件,可以直接使用静态图的C++部署方案,进行部署上线。
提升易用性,追求极致编码体验
在追求框架极限性能和部署能力的同时,飞桨也一直持续优化框架的易用性,在编程接口和模块使用上不断的打磨,精益求精,努力让大家的使用成本最低。在1.7版本中通过优化反向自动剪枝策略,在提升执行效率的同时,对于没有反向的op输出,不用显式设置stop_gradient的属性;Layer的构造函数中移除了name_scope,减少参数的传递;并移除Layer中的 build_once接口,方便大家更方便的进行参数的初始化、模型预测等;增加了一系列容器,包含Sequencial,LayerList,ParameterList,更加方便Layer和参数的管理,并能够降低大家使用时出错的概率。关于新版本的功能优化接口升级的细节可查看官网。
我们来看一个demo示例,针对上述一系列的改动,模型的代码会更加简洁。
# 1.6版本示例
class MyLayer(fluid.Layer):
def __init__(self):
...
# 在1.6中类似的Layer需要单独定义
self.conv2d1 = Conv2D("conv1", 3, 5)
self.conv2d2 = Conv2D("conv2", 3, 5)
self.conv2d3 = Conv2D("conv3":, 3, 5)
self.layer_list = [TestLayer(shapes[i]) for i in range(10)]
# 1.6中 列表中的Layer需要单独调用 add_sublayer, 增加使用成本
# 而且add_sublayer的第一个参数必须唯一,唯一出错
for i, layer in enumerate(self.layer_list):
self.add_sublayer("layer_" + str(i), layer)
def forward(self, x, y):
# 使用的时候,需要单独调用
y = self.conv2d1(x)
y = self.conv2d2(y)
y = self.conv2d3(y)
for layer in self.layer_list:
x, y = layer(x, y)
return x, y
# 1.7版本示例
class MyLayer(fluid.Layer):
def __init__(self):
...
# 在1.7中,Layer可以统一放入Sequencial容器进行管理
# Sequencial中的Layer必须是单输入、单输出的
self.sequential = Sequential([
Conv2D(3, 3, 5), # Conv2D的构造不再需要name_scope
Conv2D(5, 3, 5),
Conv2D(5, 3, 5)])
# 在1.7中,多个Layer可以通过LayerList统一管理,不在调度调用 add_sublayer
# 由于这个Layer的输入和输出都是两个,不能放入Sequencial中
self.layer_list = fluid.dygraph.LayerList(
[TestLayer(shapes[i]) for i in range(10)])
def forward(self, x, y):
# Sequencial的对象在调用时,内部包含的Layer会依次执行,不必单独调用
y = self.sequential(x)
for layer in self.layer_list:
x, y = layer(x, y)
return x, y
目前动态图功能已趋于完善,接口也趋于稳定,在后续新版本会最大可能保持前向兼容,飞桨将持续为广大开发者提供灵活高效的产业级深度学习框架。
如果您加入官方QQ群,您将遇上大批志同道合的深度学习同学。官方QQ群:703252161。
如果您想详细了解更多飞桨的相关内容,请参阅以下文档。
官网地址:
https://www.paddlepaddle.org.cn
飞桨PGL项目地址:
https://github.com/PaddlePaddle/PGL
飞桨开源框架项目地址:
GitHub: https://github.com/PaddlePaddle/Paddle
Gitee: https://gitee.com/paddlepaddle/Paddle
