Kaggle——Titanic数据分析
目录
- Titanic数据分析报告
- 问题背景
- 研究方法
- 研究过程
- 获取数据
- 统计性描述
- 数据预处理
- 特征提取
- 模型构建
- 结果
Titanic数据分析报告
问题背景
泰坦尼克号沉没事故为和平时期死伤人数最为惨重的一次海难。1912年4月15日,以“永不沉没”著名的泰坦尼克号邮轮在它的处女航行中,不幸与冰山相撞并沉没。2224名船员及乘客中,1517人丧生。
本项目旨在分析具有哪些特征的乘客更有可能存活。首先从kaggle平台获取船上乘客数据,对乘客多维度属性进行处理、分析,运用机器学习方法来实现乘客幸存与否的预测,最后对预测结果进行评价。
研究方法
数据获取&结果评估:kaggle平台
编程语言:python(numpy, pandas, sklearn)
研究过程
获取数据
- 数据下载:从kaggle项目:Titanic: Machine Learning From Disaster 页面下载数据集
- 数据导入:使用pandas库的read_csv方法,并查看数据集信息。
train=pd.read_csv("./train.csv")
test=pd.read_csv("./test.csv")
train.info()
test.info()


可以看到,数据中有12个字段,分别为:PassengerId(乘客编号)、Survived(乘客是否幸存)、Pclass(船舱等级)、Name(姓名)、Sex(性别)、Age(年龄)、SibSp(兄弟姐妹/配偶数量)、Parch(父母/子女数量)、Ticket(船票编号)、Fare(船票价格)、Cabin(船舱号)、Embarked(上船码头)。其中,训练集中共有891条记录,预测集中共有418条记录。
- 合并数据集(便于数据处理)
full=train.append(test,ignore_index=True)
full.info()
full.head()

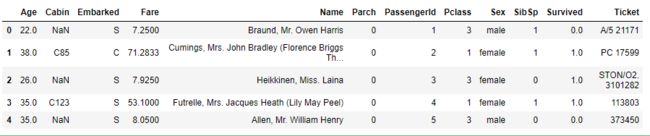
统计性描述
逐一查看各变量与最终是否存活的关系,以找出可能与存活率有关的特征。其中,PassengerId, Ticket二者仅作为编号使用,属于无关变量,不再考虑。
首先查看性别与存活率之间是否有关,使用matplotlib画图函数画出不同性别乘客中死亡和幸存的人数。
pd.crosstab(train["Sex"],train["Survived"]).plot(kind="bar")
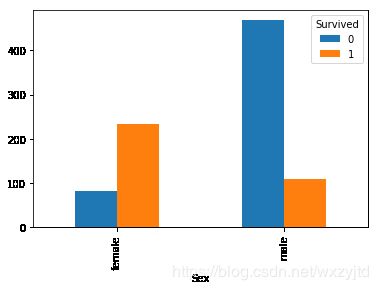
从图中可以看到,女性乘客的存活率更高,而男性乘客大多数都不能幸存(和“女士优先”的绅士文化有关),显然性别与存活率的相关性很强,后期应重点关注。
同理,找出其他变量和存活率的关系。
pd.crosstab(train["SibSp"],train["Survived"]).plot(kind="bar") #兄弟姐妹/配偶数量
pd.crosstab(train["SibSp"],train["Survived"]).plot(kind="bar") #父母/子女数量
pd.crosstab(train["Embarked"],train["Survived"]).plot(kind="bar") #登船港口
pd.crosstab(train["Pclass"],train["Survived"]).plot(kind="bar") #船舱等级
pd.crosstab(train["Fare"],train["Survived"]).plot() #船票价格
pd.crosstab(train["Age"],train["Survived"]).plot() #年龄
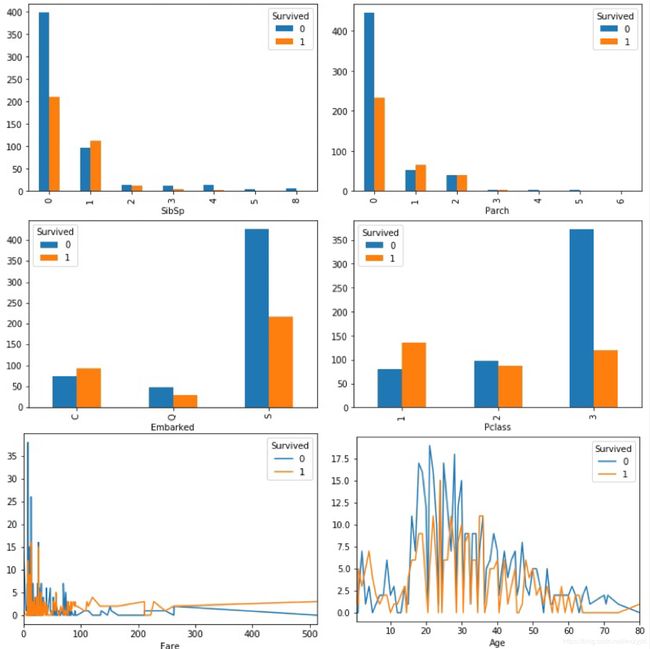
从图中可以得出以下结论:
- 家族人数为1-2人的乘客幸存率更大
- 船舱等级越高(1>2>3)/船票价格越高,幸存率越大
- 15岁以下儿童的存活率似乎比成年人更高,可能获得了成年人的帮助
- 登船港口C的生存率更高
数据预处理
在获取数据阶段中已经看到,1309条记录中,’Age’只有1046条记录,‘Cabin’字段只有295条记录,’Embarked’字段缺失2条记录,‘Fare’字段缺失1条记录。现在进行填充缺失值工作。
- 数值型。缺失记录中,‘Age’和‘Fare’为数值型变量。对于年龄,使用随机森林模型进行预测。
from sklearn.ensemble import RandomForestRegressor
age_df = full[['Age','Fare', 'Parch', 'SibSp', 'Pclass']]
age_df_notnull = age_df.loc[(full['Age'].notnull())]
age_df_isnull = age_df.loc[(full['Age'].isnull())]
X = age_df_notnull.values[:,1:]
y = age_df_notnull.values[:,0]
model = RandomForestRegressor(n_estimators=1000, n_jobs=-1)
model.fit(X,y)
predictAges = model.predict(age_df_isnull.values[:,1:])
full.loc[full['Age'].isnull(), ['Age']]= predictAges
对于船票价格,由于票价和船舱等级是高度相关的,且缺失数据只有一条,因此选择查看该条记录的船舱等级并填充相应的票价平均值。
full[full.Fare.isnull()].Pclass #pclass=3
full['Fare']=full['Fare'].fillna(full[full.Pclass==3].Fare.mean())
- 字符型。缺失记录中,‘Embarked’和‘Cabin’为数值型变量。
由于‘Embarked‘字段缺失比较少,因此采用众数填充。
full['Embarked'].value_counts()
[out]:
S 914
C 270
Q 123
full['Embarked'] = full['Embarked'].fillna( 'S' )
而’Cabin‘字段缺失比较多,将空值用’U’(Unkown)填充。
full['Cabin']=full['Cabin'].fillna('U')
特征提取
- 分类数据
分类数据主要有以下三种:性别Sex(男/女),登船港口Embarked(Q/S/C)和船舱等级Pclass(1/2/3)。对这一类数据,进行one-hot编码即可。
首先处理Sex字段。利用字典映射,将性别转换成数字(1-男,0-女)。
sex_mapDict={'male':1, 'female':0}
full['Sex']=full['Sex'].map(sex_mapDict)
然后处理Embarked字段。对这种离散型变量,使用pandas的get_dummies()方法进行one-hot编码。
embarkedDf=pd.DataFrame()
embarkedDf=pd.get_dummies(full['Embarked'],prefix='Embarked') #列名前缀是Embarked
把这些特征合并入原表,原表中的‘Embarked’字段可以删除。
full = pd.concat([full,embarkedDf],axis=1)
full.drop('Embarked',axis=1,inplace=True)
同理,对Pclass字段进行处理。
pclassDf=pd.DataFrame()
pclassDf=pd.get_dummies(full['Pclass'],prefix='Pclass')
full=pd.concat([full,pclassDf],axis=1)
full.drop('Pclass',axis=1,inplace=True)
- 字符串数据
Name、Cabin两个字段虽然并不是直接的分类数据或数字,但还是可以从中提取出信息的。
首先处理’Name’字段。 利用命令full[ 'Name' ].head()查看乘客姓名中有什么特征。

可以发现乘客姓名的格式均为:[名], [头衔].[姓] 的格式,而从头衔中可以得出乘客性别、婚姻状况甚至是社会阶级、收入等信息。因此,要先编写一个函数,把姓名中的头衔提取出来。
def getTitle(name):
str1=name.split(',')[1]
str2=str1.split('.')[0]
title=str2.strip()
return title
随机使用一位乘客姓名进行测试:getTitle('Braund, Mr. Owen Harris'),得到结果‘Mr’,说明功能实现。将这一函数运用到所有数据中,并查看共有多少种头衔。
titleDf=pd.DataFrame()
titleDf['Title']=full['Name'].map(getTitle)
titleDf['Title'].value_counts()
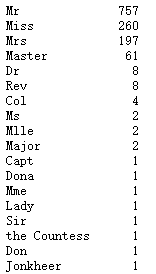
头衔数量过多,为了简化数据,根据网上查阅的信息定义以下几种头衔类别:
Officer 政府官员
Royalty 王室成员
Mr 男士
Mrs 已婚妇女
Miss 未婚女子
Master 专业技术人员
建立字典并映射到数据当中,就转换成了分类数据,再同样使用pandas的get_dummies()方法进行one-hot编码,并添加到full数据表中。
title_mapDict = {
"Capt": "Officer",
"Col": "Officer",
"Major": "Officer",
"Jonkheer": "Royalty",
"Don": "Royalty",
"Sir" : "Royalty",
"Dr": "Officer",
"Rev": "Officer",
"the Countess":"Royalty",
"Dona": "Royalty",
"Mme": "Mrs",
"Mlle": "Miss",
"Ms": "Mrs",
"Mr" : "Mr",
"Mrs" : "Mrs",
"Miss" : "Miss",
"Master" : "Master",
"Lady" : "Royalty"
}
titleDf['Title']=titleDf['Title'].map(title_mapDict)
titleDf=pd.get_dummies(titleDf['Title'])
full=pd.concat([full,titleDf],axis=1)
full.drop('Name',axis=1,inplace=True)
**再处理‘Cabin’字段。**从船舱号中提取出首字母作为船舱号的类别,再同样进行one-hot编码处理。
cabinDf=pd.DataFrame()
full['Cabin']=full['Cabin'].map(lambda s:s[0]) #提取船舱号首字母
cabinDf=pd.get_dummies(full['Cabin'],prefix='Cabin')
full=pd.concat([full,cabinDf],axis=1)
full.drop('Cabin',axis=1,inplace=True)
- 数值型数据
‘Age’,‘SibSp’,'Parch’等字段是数值类型的。
首先处理‘Age’字段。 在统计性描述分析中已经发现15岁以下的人可能有更高的存活率,因此将年龄分为15岁以下和以上两个区间。
ageDf=pd.DataFrame()
ageDf['Age_child']=full['Age'].map(lambda x:1 if x<15 else 0)
ageDf['Age_adult']=full['Age'].map(lambda x:1 if x>=15 else 0)
full=pd.concat([full,ageDf],axis=1)
然后处理’SibSp’,'Parch‘两个字段。 前述发现家庭成员规模适中的乘客更容易存活,因此首先根据这两个字段计算出每个乘客家庭成员的数量,再分成小规模、中等规模、大规模三种家庭类别,然后转换成数字编码加入full数据表内即可。
familyDf=pd.DataFrame()
familyDf['FamilySize']=full['Parch']+full['SibSp']+1
familyDf['Family_small']=familyDf['FamilySize'].map(lambda x:1 if x==1 else 0)
familyDf['Family_medium']=familyDf['FamilySize'].map(lambda x:1 if 2<=x<=4 else 0)
familyDf['Family_large']=familyDf['FamilySize'].map(lambda x:1 if x>4 else 0)
full=pd.concat([full,familyDf],axis=1)
此时,特征处理工作结束,接下来进行特征的选择。利用corr()方法查看每个特征与存活的相关系数,并画出热力图。
corrmat =full.corr()
plt.subplots(figsize=(10,10))
sns.heatmap(corrmat, vmax=0.9, square=True)
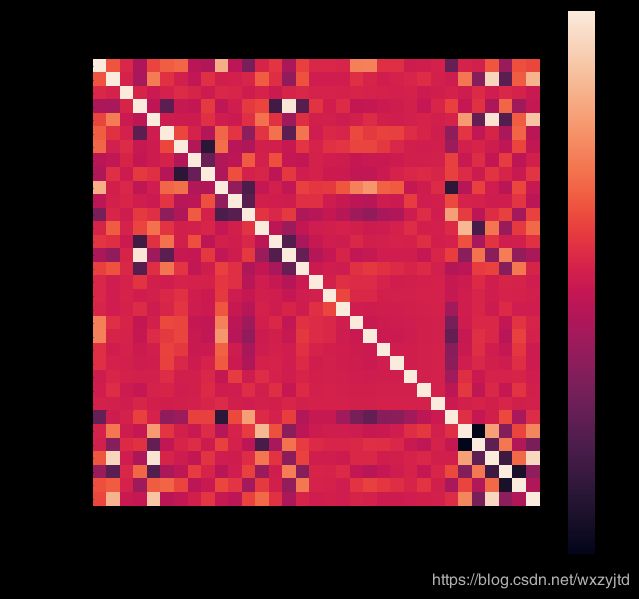
根据各个特征与Survived的相关系数大小,选择了以下特征作为模型的输入:头衔、船舱等级、家庭规模、船票价格、船舱号、登船港口、性别。
full_X=pd.concat([titleDf,#头衔
pclassDf,#客舱等级
ageDf,#年龄
familyDf,#家庭大小
full['Fare'],#船票价格
cabinDf,#船舱号
embarkedDf,#登船港口
full['Sex']#性别
] , axis=1 )
模型构建
从所有拆分出训练集、测试集和预测集,并选择一个机器学习模型开始训练。
- 随机森林模型
from sklearn.ensemble import RandomForestClassifier
row=891 #训练集共有891条记录
X=full_X.loc[0:row-1,:]
y=full.loc[0:row-1,'Survived']
pred_X=full_X.loc[row:,:]
model = RandomForestClassifier(n_estimators=100)
model.fit(X,y)
- 逻辑回归
from sklearn.linear_model import LogisticRegression
row=891 #训练集共有891条记录
X=full_X.loc[0:row-1,:]
y=full.loc[0:row-1,'Survived']
pred_X=full_X.loc[row:,:]
model = LogisticRegression()
model.fit(X,y)
模型训练完成后,使用预测集内的数据进行预测,并将结果按kaggle格式要求输出到csv文件中。
prediction=model.predict(pred_X)
prediction=prediction.astype(int)
passenger_id = test['PassengerId']
predDf = pd.DataFrame(
{ 'PassengerId': passenger_id ,
'Survived': prediction } )
predDf.to_csv('my_predictions.csv',index=False)
结果
将预测结果上传到kaggle平台,得分0.775/1,排名前58%。