https://www.cnblogs.com/guiyuanself/p/5284136.html
界面卡顿问题比较喜欢问


/*
1.weak
1> OC对象
2.assign
1> 基本数据类型
2> OC对象
3.strong
1>OC 对象
5.使用weak和assign修饰OC对象的区别
1> 成员变量
2> assign生成的成员变量用_unsafe_unretained修饰的
2>__weak和_unsafe_unretained
1)都不是强指针,不是强引用,不能包住对象的命
2)__weak : 所指向的对象销毁后,会自动变成nil指针 (空指针)
_unsafe_unretained:所指向的对象销毁后,仍旧指向已经销毁的这个对象
*/
第一题
atomic
atomic 与 nonatomic 区别
atomic : 变量默认是有该有属性的,这个属性是为了保证在多线程的情况下,编译器会自动生成一些互斥加锁的代码,避免该变量的读写不同步的问题。
nonatomic : 如果该对象无需考虑多线程的情况,这个属性会让编译器少生成一些互斥代码,可以提高效率。
atomic 的意思是setter/getter 这个函数,是一个原语操作,如果有多个线程同时调用setter的话,不会出现某一个线程执行完setter全部语句之前,另一个线程开始执行setter情况,相当于函数头尾加了锁一样,可以保证数据的完整性。nonatamic 不保证setter/getter 的原语行,所以你可能会取到不完整的东西。因此,在多线程的环境下的原子操作是非常必要的,狗有可能会引起错误的结果。
比如setter函数里改变了两个成员变量,如果你用nonatomic的话,getter 可能会取到只更改了其中一个变量时候的状态,这样取到的东西会有问题,就是不完整的。当然如果不需要多线程支持的话,用nonatomic就够了,因为不涉及到线程锁的操作,所以它执行效率相对快些。
例如加了atomic的例子:
{lock}
if(proprity!=newValue){
[property release];
property = [newValue retain];
}
{unlock}
所以,atomic 会在多线程设值取值的时候加锁,中间的执行层是处于被保护的一种状态,atomic 是oc使用的一种线程保护技术,基本上讲,就是防止在写入未完成的时候被另外一个线程读取,造成数据错误。而这种机制是耗费系统资源的,所以在iPhone这种小型设备上,如果没有使用多线程间的通讯编程,那么nonatomic是一个非常好的选择!
readwrite:默认属性,可读可写,生成setter和getter方法。
assign适用于基本数据类型,weak是适用于NSObject对象,并且是一个弱引用。
assign其实也可以用来修饰对象。那么我们为什么不用它修饰对象呢?因为被assign修饰的对象(一般编译的时候会产生警告:Assigning retained object to unsafe property; object will be released after assignment)在释放之后,指针的地址还是存在的,也就是说指针并没有被置为nil,造成野指针。对象一般分配在堆上的某块内存,如果在后续的内存分配中,刚好分到了这块地址,程序就会崩溃掉。
那为什么可以用assign修饰基本数据类型?因为基础数据类型一般分配在栈上,栈的内存会由系统自己自动处理,不会造成野指针。
weak修饰的对象在释放之后,指针地址会被置为nil。所以现在一般弱引用就是用weak。weak使用场景:
在ARC下,在有可能出现循环引用的时候,往往要通过让其中一端使用weak来解决,比如: delegate代理属性,通常就会声明为weak。
自身已经对它进行一次强引用,没有必要再强引用一次时也会使用weak。比如:自定义 IBOutlet控件属性一般也使用weak,当然也可以使用strong。
第二道题
1、MVC
从字面意思来理解,MVC 即 Modal View Controller(模型 视图 控制器),是 Xerox PARC 在 20 世纪 80 年代为编程语言 Smalltalk-80 发明的一种软件设计模式,至今已广泛应用于用户交互应用程序中。其用意在于将数据与视图分离开来。在 iOS 开发中 MVC 的机制被使用的淋漓尽致,充分理解 iOS 的 MVC 模式,有助于我们程序的组织合理性。
MVC 的几个明显的特征和体现:
View 上面显示什么东西,取决于 Model。
只要 Model 数据改了,View 的显示状态会跟着更改。
Control 负责初始化 Model,并将 Model 传递给 View 去解析展示。
2、MVP
从字面意思来理解,MVP即Modal View Presenter(模型 视图 协调器),MVP实现了Cocoa的MVC的愿景。MVP的协调器Presenter并没有对ViewController的声明周期做任何改变,因此View可以很容易的被模拟出来。在Presenter中根本没有和布局有关的代码,但是它却负责更新View的数据和状态。
MVP 是第一个如何协调整合三个实际上分离的层次的架构模式,既然我们不希望 View 涉及到 Model,那么在显示的 View Controller(其实就是 View)中处理这种协调的逻辑就是不正确的,因此我们需要在其他地方来做这些事情。例如,我们可以做基于整个 App 范围内的路由服务,由它来负责执行协调任务,以及 View 到 View 的展示。这个出现并且必须处理的问题不仅仅是在 MVP 模式中,同时也存在于以下集中方案中。
MVC和MVP的区别就是,在MVP中M和V没有直接通信。
3.MVVM
从字面意思来理解,MVVM 即 Modal View ViewModel(模型 视图 视图模型)。MVC 是一个用来组织代码的权威范式,也是构建 iOS App 的标准模式。Apple 甚至是这么说的。在 MVC 下,所有的对象被归类为一个 model,一个 view,或一个 controller。Model 持有数据,View 显示与用户交互的界面,而 View Controller 调解 Model 和 View 之间的交互。然而,随着模块的迭代我们越来越发现 MVC 自身存在着很多不足。因此,MVVM 从其他应用而出,在 iOS 中从此我们完全将业务逻辑加以区分并使用这套思想。在 MVVM 中他的设计思路和 MVC 很像。它正式规范了视图和控制器紧耦合的性质,并引入新的组件 ViewModel。此外,它还有像监管版本的 MVP 那样的绑定功能,但这个绑定不是在 View 和 Model 之间而是在 View 和 ViewModel 之间。
我们注重架构, 注重分层都是为了开发效率, 说到底还是为了开心. 所以, 在实际开发i不应该拘泥于某一种架构, 根据实际项目出发, 一般普通的MVC就能应对大部分的开发需求, 至于MVP和MVVM, 可以尝试, 但不要强制.
总之, 希望大家能做到: 设计时, 心中有数. 撸码时, 开心就好.
第三题
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。 线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
第四题
一般情况下我们使用线程,在多个线程共同访问同一块资源。为保护线程资源的安全和线程访问的正确性。
在IOS中我们一般情况下使用以下三种线程同步代码方式:
第一种和第二种代码同步的使用方法,一般情况下我们只需要使用NSLock和NSCondition申明2个属性。然后给此属
性赋对应的值。那么即可作为安全防控的线程手段。
同时也可以保证线程的资源安全。
1:NSLock方式
[xxxlock lock] //上锁
同步代码块
[xxxlock unlock]//解锁
2:NSCondition方式
[xxxCondition lock] //上锁
同步代码块
[xxxCondition unlock]//解锁
第三种方式:在使用synchronized的时候,括号中我们一般情况下只需要传一个self即可。同步代码块 当有线程
进去之后会把括号里面对象的锁旗标锁上,其他线程会在外面等着 当进去的线程出去的时候会把锁打开 其余线程
再进一个。这样才能保护线程放问资源的安全性。
3:@synchronized( 同一对象){
线程执行代码;
}
线程资源防控示例代码:
[objc]view plaincopyprint?在CODE上查看代码片派生到我的代码片
-(void)sellTickets{
while (YES) {
NSString *name = [NSThread currentThread].name;
// 同步代码块 当有线程进去之后会把括号里面对象的锁旗标锁上,其他线程会在外面等着 当进去的线程
出去的时候会把锁打开 其余线程再进一个
// @synchronized(self){
// [self.myLock lock];
[self.myCondition lock];
NSLog(@"%@开始卖%d号票",name,self.selledCount+1);
[NSThread sleepForTimeInterval:.2];
self.selledCount++;
NSLog(@"%@卖掉了%d号票,还剩%d张",name,self.selledCount,self.totalCount-
self.selledCount);
// [self.myLock unlock];
[self.myCondition unlock];
}
// }
}
第五题
所谓的持久化,就是将数据保存到硬盘中,使得在应用程序或机器重启后可以继续访问之前保存的数据。在iOS开发中,有很多数据持久化的方案,接下来我将尝试着介绍一下5种方案:
plist文件(属性列表)
preference(偏好设置)
NSKeyedArchiver(归档)
SQLite 3
CoreData
第六题
抱歉,没拍到,等我想起来,再补上
第七题
一、插入语句
insert into [table] ([column],[column],[column])
values(?,?,?)
二、删除语句
delete
from [table]
where column = ?
三、修改语句
update [table]
set column = ?
where column = ?
四、查询语句
1)查询单条记录的所有字段
select *
from [table]
where [column] = ?
2)查询所有记录的所有字段
select *
from [table]
order by [column] asc
第八题
App混合开发(英文名:Hybrid App),是指在开发一款App产品的时候为了提高效率、节省成本即利用了原生的开发技术还应用了HTML5开发技术,是原生和HTML5技术的混合应用。目前App的开发主要包含三种方式:原生开发、HTML5开发和混合 开发。
原生应用开发,是在Android、IOS等移动平台上利用官方提供的开发语言、开发类库、开发工具进行App开发。比如android是利用java、eclipse、Android studio,IOS是利用Objective-C 和Xcode进行开发。原生应用由于利用的是官方提供的语言和工具并且能够直接操控硬件设备(比如多点触控、NFC、读取短信等),在应用性能上和交互体验上应该是最好的,但是原生应用的可移植性比较差,特别是一款原生的App,Android和IOS都要各自开发,同样的逻辑、界面要写两套。
HTML5应用开发,是利用Web技术进行的App开发,我们知道web技术本身需要浏览器的支持才能进行展示和用户交互。主要用到的技术是HTML5、JavaScript、CSS等。现在还有一些开发框架可以利用,比如phoneGap、bootstrap、jquery等。H5开发的好处是可以跨平台,编写的代码可以同时在Android、IOS、Windows上进行运行。由于Web技术本身的限制,H5移动应用不能直接访问设备硬件和离线存储,所以在体验和性能上有很大的局限性。
混合应用开发正是结合原生和H5开发的技术,取长补短的一种开发模式,原生代码部分利用WebView插件或者其它的框架为H5提供了一个容器,程序主要的业务实现、界面展示是利用H5相关的Web技术进行实现的。比如现在的京东、淘宝、今日头条等都是利用的混合开发模式。
混合开发的优缺点:
优点是:
1、开发效率高,节约时间同一套代码Android和IOS基本都可用
2、更新和部署比较方便,不需要每次升级都要上传到App Store进行审核了,只需要在服务器端升级就可以
3、代码维护方便、版本更新快,降低产品成本
缺点是:
1、由于不能直接操控硬件有些方面性能不是很好
2、另外有技术比较新版本的兼容性比较差,还有就是即懂原生开发又懂H5开发的高端人才难找。
混合App开发是未来的趋势,目前混合开发中使用的技术也很多,主要的混合开发技术有jQuery Mobile、React Native、Cordova、APICloud、AppCan等。虽然混合开发能够提高效率节省成本,但也有很多的限制,除了硬件、缓存等的限制,各大平台之间的兼容性也不足。有的也比较消耗资源
第九题
哈希表是存储数据的一种结构,增加的数据对应哈希表的特定地址,一个地址只允许有一个数据。要增加的数据应该存放在哪个地址是由散列函数确定的,但是不管散列函数如何取,总是避免不了计算的结果是同一个地址的情况,这时就不知道冲突的地方应该放哪个数据好,这种情况被称为哈希冲突。
为了缓解哈希冲突,一般采用的方法有以下四种:
1)链地址法
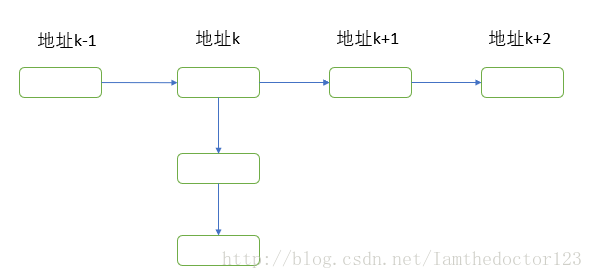
这种方法的基本思想是将所有哈希地址为i的元素构成一个称为同义词链的单链表,并将单链表的头指针存在哈希表的第i个单元中,因而查找、插入和删除主要在同义词链中进行。
链地址法适用于经常进行插入和删除的情况。
结构示意图如下:
2)开放地址法
这个方法的基本思想是:当发生地址冲突时,按照某种方法继续探测哈希表中的其他存储单元,直到找到空位置为止。
这个过程可用下式描述:
H i ( key ) = ( H ( key )+ d i ) mod m ( i = 1,2,…… , k ( k ≤ m – 1))
其中: H ( key ) 为关键字 key 的直接哈希地址, m 为哈希表的长度, di 为每次再探测时的地址增量。
采用这种方法时,首先计算出元素的直接哈希地址 H ( key ) ,如果该存储单元已被其他元素占用,则继续查看地址为 H ( key ) + d 2 的存储单元,如此重复直至找到某个存储单元为空时,将关键字为 key 的数据元素存放到该单元。
增量 d 可以有不同的取法,并根据其取法有不同的称呼:
( 1 ) d i = 1 , 2 , 3 , …… 线性探测再散列;
( 2 ) d i = 1^2 ,- 1^2 , 2^2 ,- 2^2 , k^2, -k^2…… 二次探测再散列;
( 3 ) d i = 伪随机序列 伪随机再散列;
例1设有哈希函数 H ( key ) = key mod 7 ,哈希表的地址空间为 0 ~ 6 ,对关键字序列( 32 , 13 , 49 , 55 , 22 , 38 , 21 )按线性探测再散列和二次探测再散列的方法分别构造哈希表。
解:
( 1 )线性探测再散列:
32 % 7 = 4 ; 13 % 7 = 6 ; 49 % 7 = 0 ;
55 % 7 = 6 发生冲突,下一个存储地址( 6 + 1 )% 7 = 0 ,仍然发生冲突,再下一个存储地址:( 6 + 2 )% 7 = 1 未发生冲突,可以存入。
22 % 7 = 1 发生冲突,下一个存储地址是:( 1 + 1 )% 7 = 2 未发生冲突;
38 % 7 = 3 ;
21 % 7 = 0 发生冲突,按照上面方法继续探测直至空间 5 ,不发生冲突,所得到的哈希表对应存储位置:
下标: 0 1 2 3 4 5 6
49 55 22 38 32 21 13
( 2 )二次探测再散列:
下标: 0 1 2 3 4 5 6
49 22 21 38 32 55 13
注意:对于利用开放地址法处理冲突所产生的哈希表中删除一个元素时需要谨慎,不能直接地删除,因为这样将会截断其他具有相同哈希地址的元素的查找地址,所以,通常采用设定一个特殊的标志以示该元素已被删除。
3)再哈希法
这种方法同样是按照按某种方法探测哈希表中的其他存储单元,直到找到空位置为止。具体来看是同时构造多个不同的哈希函数:
Hi=RH1(key) i=1,2,…,k
Hi=RH2(key) i=1,2,…,k
。。。。。。
当哈希地址Hi=RH1(key)发生冲突时,再计算Hi=RH2(key)……,直到冲突不再产生。这种方法不易产生冲突,但增加了计算时间。
4)建立公共溢出区
这种方法的基本思想是:将哈希表分为基本表和溢出表两部分,凡是和基本表发生冲突的元素,一律填入溢出表。
第十题
快速排序(Quicksort)是对冒泡排序的一种改进。
快速排序由C. A. R. Hoare在1962年提出。它的基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
先来感受一下快速排序动态过程
[图片上传失败...(image-76e322-1530176702907)]
快速排序实现方案
设要排序的数组是mutableArray对象,首先任意选取一个数据(通常选用数组的第一个数)作为关键数据,然后将所有比它小的数都放到它前面,所有比它大的数都放到它后面,这个过程称为一次快速排序。
步骤讲解
1 ).设置两个变量i,j ,排序开始时i = 0,就j = mutableArray.count - 1;
2 ).设置数组的第一个值为比较基准数key,key = mutableArray.count[0];
3 ).因为设置key为数组的第一个值,所以先从数组最右边开始往前查找比key小的值。如果没有找到,j--继续往前搜索;如果找到则将mutableArray[i]和mutableArray[j]互换,并且停止往前搜索,进入第4步;
4 ).从i位置开始往后搜索比可以大的值,如果没有找到,i++继续往后搜索;如果找到则将mutableArray[i]和mutableArray[j]互换,并且停止往后搜索;
5 ).重复第3、4步,直到i == j(此时刚好执行完第三步或第四部),停止排序;
排序演示
假设mutableArray = [@(6),@(3),@(7),@(1),@(5),@(8)]
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 数据 | 4 | 3 | 7 | 1 | 5 | 8 |
第一步:i = 0; j = 5; key = 4;
第二步:要找比key小的指,从右往前找,j不断递减,直到找到第一个比key小的,然后将mutableArray[i]和mutableArray[j]互换
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 数据 | 1 | 3 | 7 | 4 | 5 | 8 |
i = 0; j = 3; key = 4;
第三步:要找比key大的指,从左往后找,i不断递增,直到找到第一个比key大的,然后将mutableArray[i]和mutableArray[j]互换
| 下标 | 0 | 1 | 2 | 3 | 4 | 5 |
|---|---|---|---|---|---|---|
| 数据 | 1 | 3 | 4 | 7 | 5 | 8 |
i = 2; j = 3; key = 4;
接着j--,则i==j;这样就称为一次循环
然后将key左边,右边的值分别当做一个数组重复上面步骤
OC代码实现
- (void)viewDidLoad {
[super viewDidLoad];
NSMutableArray *arr = [[NSMutableArray alloc] initWithObjects:@(6), @(1),@(2),@(5),@(9),@(4),@(3),@(7),nil];
[self quickSortArray:arr withLeftIndex:0 andRightIndex:arr.count - 1];
NSLog(@"%@",arr);
}
- (void)quickSortArray:(NSMutableArray *)array withLeftIndex:(NSInteger)leftIndex andRightIndex:(NSInteger)rightIndex
{
if (leftIndex >= rightIndex) {//如果数组长度为0或1时返回
return ;
}
NSInteger i = leftIndex;
NSInteger j = rightIndex;
//记录比较基准数
NSInteger key = [array[i] integerValue];
while (i < j) {
/**** 首先从右边j开始查找比基准数小的值 ***/
while (i < j && [array[j] integerValue] >= key) {//如果比基准数大,继续查找
j--;
}
//如果比基准数小,则将查找到的小值调换到i的位置
array[i] = array[j];
/**** 当在右边查找到一个比基准数小的值时,就从i开始往后找比基准数大的值 ***/
while (i < j && [array[i] integerValue] <= key) {//如果比基准数小,继续查找
I++;
}
//如果比基准数大,则将查找到的大值调换到j的位置
array[j] = array[I];
}
//将基准数放到正确位置
array[i] = @(key);
/**** 递归排序 ***/
//排序基准数左边的
[self quickSortArray:array withLeftIndex:leftIndex andRightIndex:i - 1];
//排序基准数右边的
[self quickSortArray:array withLeftIndex:i + 1 andRightIndex:rightIndex];
}
这就是笔试题部分,关于面试题小编感觉毫无挑战性,感觉面试官虽然是技术总监,但是好像丝毫不懂技术,一些问题都没办法深入和我交流,而且他对编程部分有很多错误的认识,我也不好指出来了。
不过他问了banner是怎么实现的,这个问题我觉得各位可以去查阅,如何自己实现一个轮播图效果,重点是怎么消除最后一张和开始一张的视觉错乱。附上一个链接,可以点进去看一下。
天气很热,各位找工作的同行,还是精心准备,好好总结吧。