Kafka实践七:Kafka自带工具及常见异常处理文档
Kafka自带常用工具
Kafka的bin目录下shell脚本是kafka自带的管理工具,提供topic的创建/删除/配置修改、消费者的监控、分区重载、集群健康监控、收发端TPS压测、跨机房同步等能力,Kafka运维者可以使用这些工具进行集群的管理;
Kafka节点的启/停
------kafka 运行:
bin/kafka-server-start.sh -daemon ../config/server.properties &------kafka 停止:
bin/kafka-server-stop.sh如果上面命令并未停止掉相应的进程,建议执行kill –s TERM $pid,完成进程关闭;
Topic的创建/删除/配置修改
Kafka的bin目录下有若干shell脚步,提供很多工具,完成kafka的元数据的监控和管理;
------创建topic
./kafka-topics.sh --zookeeper xxxx --replication-factor 3 --partitions 10 --create --topic xxxx------查看topic
./kafka-topics.sh --zookeeper xxxx --describe –topic xxxx------删除topic
./kafka-topics.sh --delete --zookeeper xxxx--topic xxxx------查看集群中的topic:
./kafka-topics.sh --zookeeper xxxx –list------查看指定topic配置
./kafka-topics.sh --zookeeper xxxx --describe --topic xxx------修改超时时长
./kafka-topics.sh --zookeeper xxxx --alter --topic xxxx --config retention.ms=864000------增加topic分区数
./kafka-topics.sh --zookeeper xxxx --alter --partitions 5 --topic xxxxTopic的生产/消费
------kafka生产消息
./kafka-console-producer.sh --broker-list xxxx --topic xxxx------消费kafka
./kafka-console-consumer.sh --zookeeper xxxx --topic xxxx -from-beginning若不需要重头消费,去掉from-beginning
查看/修改消费偏移量
------kafka_0.10前查看kafka的消费积压
./kafka-run-class.sh kafka.tools.ConsumerOffsetChecker --zookeeper xxxx --topic xx -group xx------kafka_1.0新版本后查看kafka的消费积压
./kafka-consumer-groups.sh --bootstrap-server xxxx --describe --group xxx;------修改zk中保存的偏移量
./zkCli.sh –server xxxx:xx
set /consumer/xxx/xx
------修改kafka中保存的偏移量
kafka_0.10前版本不支持修改偏移量操作,0.11后版本支持;
./kafka-consumer-groups.sh --bootstrap-server xxxx –group xxx –topic xxx:xx –shift-by xxxx --execute![]()
参考:https://blog.csdn.net/yezonggang/article/details/95593220
Topic的分区重载
一般分区重载在集群新加节点(kafka集群增加节点后,旧topic不会进行数据的重载)和分区备份列表扩增的时候需要用到,分区重载需要预先设定重载的json配置文件;
------指定需要分配的broker列表
./bin/kafka-reassign-partitions.sh --zookeeper xxxx --topics-to-move-json-file xx.json --broker-list "1,2,3,4,5" --generate b------执行重载计划
./kafka-reassign-partitions.sh --zookeeper xxxx --reassignment-json-file xxx.json –execute------验证重载计划
./kafka-reassign-partitions.sh --zookeeper xxxx --reassignment-json-file xxx.json --verify参考:https://blog.csdn.net/yezonggang/article/details/95593220
集群TPS压测
Kafka提供压测脚本,可以进行生产者和消费者的压测,同时可以虚拟各种收发端的参数设置(包括ack机制、线程数);
------发送者压测
./kafka-producer-perf-test.sh --topic topic_for_test --num-records 500000000 --record-size 50 --throughput -1 --producer-props bootstrap.servers=xxx acks=-1------生产者压测
./kafka-consumer-perf-test.sh --broker-list xxxx --messages 50000000 --topic xxx跨机房同步工具Kafka-Mirror-Maker
该工具效率高且配置简单,用于跨机房/跨网络传输,具体的配置和优化可参考:
https://blog.csdn.net/yezonggang/article/details/99762465
其他
Kafka有prefered leader机制,即最适合的leader,若集群中有节点宕掉,或者其他原因的leader切换,会造成多个分区在同一个节点上,宕掉的节点恢复后,可以使用工具调整分区的prefered leader;
Kafka-preferred-replica-election.sh通过设定的json文件完成分区的preferred leader分配;
Kafka还提供了很多基于kafka-run-class.sh的工具,需要可以在官网研究;
Kafka常见问题
处理Kafka常见问题的思路是首先检查集群健康,在实时监控集群节点运行日志的基础上找出影响集群状态的问题,broker状态不正常会导致发端问题和消费积压,确认集群节点正常后,发送端和消费端的问题可以通过调优解决;
Broker常见问题
1、分区ISR列表出现频繁Expanding, Shinking,导致broker不可用
Kafka的集群中有节点日志出现大量的ISR列表频繁Expanding, Shinking问题造成当前节点不可用问题,该问题出现的原因为:Kafka的每个topic有若干个分区partition,每个partiton可能有多个备份,这样就单个分区而言,多个备份中有leader和follower两种角色,follower会定时从leader同步数据,每个分区都有一个ISR列表,该列表表征了分区的多个备份是否在同步中,若follower挂掉或者网络抖动,则被移除ISR列表,若恢复正常,则加入到ISR列表;
若出现ISR频繁的Expanding和 Shinking表明可能是单个分区的数据量过大导致部分分区的follower无法及时备份,或者follower无法及时同步足够的消息已满足ISR判定条件,从而被Shinking清除出ISR列表,瞬间又追上复制速度,从而Expanding加入到ISR列表;
解决方法:修改kafka的配置文件,增加单个broker的复制数据的线程数,降低ISR列表判定条件(时长+条数);

2、节点OOM问题
Kafka的默认启动内存256M,Kafka的生产端首先将数据发送到broker的内存存储,随机通过主机的OS层的数据刷盘机制将数据持久化,因此Kafka需要一定大小的内存空间,在生产环境一般建议将启动内存调整,官方建议内存在4-8G左右大小;
若节点出现OOM,进程运行日志会出现OOM关键词(目前已加入关键字告警),随即kafka进程宕掉;
修改方式:修改${KAFKA_HOME}/bin/kafka-server-start.sh脚步;
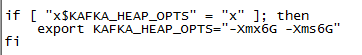
3、java.io.IOException Connection to xx was disconnected before the response was read xxxxxxxxxxxxxxxxxx
针对此问题,网上的意见不一。导致该报错的问题有很多,Kafka集群中的各个节点,均会自主发起同步其他节点数据的线程,用以已达到数据备份目的,若集群中有broker节点不正常或负载过高,其他broker节点同步该节点数据的线程即会出现这种报错,因此该类问题通常伴随着ReplicaFetcherThread线程shutdown日志;
解决方法:
1.观察集群的其他节点是否有同样报错,多个报错日志中是否都指向固定的kafka节点(连接问题),若指向同一broker,则表明数据同步线程无法读取该节点的消息,该节点存在问题,观察该节点的iostat,是否存在读写瓶颈(硬件+OS层均需要巡检);
2.若集群的多个节点均存在同样的报错,且报错信息指向不同的节点(该问题较少出现),则排除单个broker问题造成的问题,观察不影响数据收发,可忽略该报错;
4、broker上kafka进程正确启/停
生产中遇到过单个物理机部署多个Kafka实例的场景,在执行./kafka-server-stop.sh脚本,该脚本会匹配机器上所有运行的kafka实例,并全部关闭,如下,因此若一个机器上有多个kafka实例,需要关闭特定的Kafka实例,建议使用kill –s TERM $pids 方式停止进程;

Kafka的启动方式使用:
./kafka-server-start –daemon ../conf/server.properties &
关于启/停的验证:kafka进程的启动/关闭状态,可通过log/server.log跟踪,但在启动时一般需要大量的时间恢复文件和index,关闭时需要shutdow一些同步数据的线程,因此根据zookeeper中的节点信息判定是否正确完成启动/关闭:
1.使用./zkCli.sh –server host:port进入到zk的元数据树;
2.查看get /brokers/ids/ 得到加入zk的节点数;
5、broker运行日志大量topic不存在报错,导致节点不可用
若broker的运行日志大量刷topic不存在的WARN,并导致节点不可用;表明该集群存在topic被删除,但有发端仍使用该topic发送数据,此时需要检查broker上的2个配置项:
delete.topic.enable
auto.create.topics.enable生产环境下需要进行规范化的topic管理,难免进行topic的增删,建议将自动创建topic开关关闭,将可删除topic的开关打开,设置:
delete.topic.enable=true
auto.create.topics.enable=falseProducer常见问题
当前公司的commonlog封装的是0.8版本的发端(scala版),发送效率低且默认的发送机制存在问题,官方建议尽早升级,后续将不再支持0.8版本的发送端发送消息;
1、kafka.common.MessageSizeTooLargeException
Kafka的broker和发送端、消费端都会定义单条数据大小的属性,一般默认大小是0.95G,若在broker端调整了该属性,但发端未同步设置单条数据大小,则会出现报错kafka.common.MessageSizeTooLargeException,造成整个batch数据的丢失,若消费端设置的消费单条数据大小<消息的大小,同样会报错;
解决方法:修改kafka的broker配置文件、发送者、消费者的单条数据大小,综合考虑单条数据大小范围;
2、fetching topic metadata for topics [Set(test)] from broker x failed
Kafka的发端发送数据的同时会给broker发送心跳,并得到一些topic的metadata元数据信息(包括分区数、分区的leader),fetching topic metadata for topics [Set(test)] from broker x failed 报错一般表征了kafka的集群节点不健康;
解决方法:修改kafka的broker配置文件、发送者、消费者的单条数据大小,综合考虑单条数据大小范围;
3、LEADER_NOT_AVAILABLE
WARN Error while fetching metadata with correlation id 0{test=LEADER_NOT_AVAILABLE},若出现该报错,表名Topic可能正在进行leader选举 使用kafka-topics脚本检查leader信息;
4、NotLeaderForPartitionException
Kafka的生产者在得到topic某个分区的leader信息后,生产者会向topic的leader发送消息,NotLeaderForPartitionException 的报错一般发生在元数据中的leader和真实的leader不一致时候,即 leader从一个broker切换到另一个broker时,要分析什么原因引起了leader的切换;
5、TimeoutException
检查网络是否能通,如果可以通,可以考虑增加request.timeout.ms的值;
Consumer常见问题
Kafka的消费者API比较简单,默认是异步消费,关于这方便报错没有关注,消费原理可以参考;
https://blog.csdn.net/yezonggang/article/details/99743303
快速有效的解决方法
若出现集群不可用,且无法快速恢复集群状态,可参考以下方法;
鉴于当前生产环境都使用域名进行数据的收发,因此只需要保证kafka的brokerip和端口不变,生产者和消费者即可以发/读消息;
同时,由于生产环境都是5节点,若有节点长时间启动不了,影响生产数据的发送,集群并没有完全宕(zk存储的kafka元数据信息没有丢失);
通过在同一个主机上新建数据目录和kafka应用目录,并重启问题节点可以完成集群的快速恢复(默认丢弃问题节点的历史数据);