词云图的制作
制作词云图
效果如下图:
准备工作
1、jieba库
2、wordcloud库
3、PIL模块 (官方的图像处理库,必装)
4、numpy(数据处理库)
1、jieba库
安装:
pip install jieba
jieba模块是python中常用的分词模块,简单介绍它的作用:
结巴分词的分词模式分为三种:
- (1) 全模式:把句子中所有的可以成词的词语都扫描出来, 速度快,但是不能解决歧义问题
- (2) 精确模式:将句子最精确地切开,适合文本分析
- (3) 搜索引擎模式:在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词
【以下,都返回一个生成器`generator`】
# 全模式
jieba.cut(text, cut_all=True)
# 精确模式 (该模式是默认的模式,参数`cut_all=False`可不写)
jieba.cut(text, cut_all=False)
# 搜索引擎模式
jieba.cut_for_search(text)
2、wordcloud库
参考文档资料如下:https://amueller.github.io/word_cloud/generated/wordcloud.WordCloud.html
安装:
pip install wordcloud
(一)wordcloud模块中有三个函数分别是:
- wordcloud.WordCloud() # 主要使用该函数!!!
- wordcloud.ImageColorGenerator( )
- wordcloud.random_color_func( )
① wordcloud.WordCloud() # 【用于生成或者绘制词云的对象】
该函数携带多个参数,依次介绍如下:
- font_path : 字体路径(需要设置什么样的字体,就将字体路径以字符串的形式传入。默认为
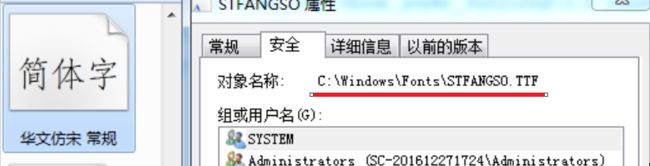
wordcloud库下的DroidSansMono.ttf字体)ps:如果选用默认字体的话,是不能够显示中文字的。为使得能够显示中文,可以自己设置字体。系统字体一般都在C:\Windows\Fonts目录下。之前别人博客中提到的设置为STFANGSO.TTF就是华文仿宋。选择自己想要设置的字体,然后右击属性,复制路径然后赋值给font_path即可。(如下图)
- width: 画布宽度(默认为400像素)
- height: 画布高度(默认为200)
- margin: 每个单词间的间隔 (默认为2)
- prefer_horizontal : 词语水平方向排版出现的频率(默认为0.9,注意水平排版和垂直排版概率之和为1,因此默认垂直方向排版为0.1)
- mask: nd-array or None (default=None), 简单理解为绘制模板。【当mask不为0时,那么之前依据height和width设置的画布则作废,此时“画布”形状大小由mask决定】
- scale: float (default=1). 计算和绘图之间的比例(就是放大画布的尺寸,也可以叫比例尺)。对于大型词云图,使用比例尺比设置画布尺寸来得更加快速,但是单词匹配不是很好。
- max_words: number (default=200) 最大显示单词字数。
- max_font_size: int or None (default=None) 最大单词的字体大小,如果没有设置的话,直接使用画布的大小。
- stopwords: set of strings or None 被淘汰不用于显示的词语(又叫屏蔽词),默认使用内置的stopwords。
- background_color: color value (default=”black”) 词云图像的背景色,默认为黑色。
- mode: string (default=”RGB”) 当
mode=“RGBA”且background_color=“None”时,将生成透明的背景。 - relative_scaling: float (default=’auto’) 词频大小对字体大小的影响度。如果设置为1的话,如果一个单词出现两次那么其字体大小为原来 的两倍。
- color_func: callable, default=None 生成新颜色的函数,如果为空,则使用self.color_func。注意的是如果你想要使得字体颜色为统一的颜色,使用如下:
color_func=lambda *args, **kwargs: "white" #所有字体为白色
# 或者通过设置RGB来解决.
color_func=lambda *args, **kwargs: (255,0,0) #所有字体颜色为红色
- regexp: string or None (optional) 使用正则表达式分割输入的字符。没有指定的话就使用
r"\w[\w']+"。 - collocations: bool, default=True 是否包括两个词的搭配(双宾语)
- colormap: string or matplotlib colormap, default=”viridis”。颜色映射方法,每个单词对应什么颜色,就是根据这个colormap的。如果设置 color_func ,则这个设置作废。
- repeat : bool, default=False 是否需要重复单词以使得总单词数量达到 max_words。
② wordcloud.ImageColorGenerator() # 【基于彩色图像的颜色生成器】
wordcloud.ImageColorGenerator(image, default_color=None)
》根据RGB图像生成颜色。单词将使用彩色图像中包围的矩形的平均颜色进行着色。参数:image用于生成单词颜色的图像。
》生成的对象用法:
- 1、可以传入给 wordcloud.WordCloud() 构造函数中的
color_func参数。 - 2、可以传入给 recolor() 函数中的
color_func参数。
③ wordcloud.random_color_func() # 【随机色调颜色生成】
wordcloud.random_color_func(word=None, font_size=None, position=None, orientation=None, font_path=None, random_state=None)
》随机色调颜色生成。如果给定一个随机对象,则用于生成随机数
(二)wordcloud输出形式:
fit_words(frequencies)# 根据词频生成词云generate(text)# 根据文本生成词云generate_from_frequencies(frequencies[, ...])# 根据词频生成词云generate_from_text(text)# 根据文本生成词云process_text(text)# 将长文本分词并去除屏蔽词(此处指英语,中文分词还是需要自己用别的库先行实现,使用上面的 fit_words(frequencies))recolor([random_state, color_func, colormap])# 对现有输出重新着色。重新上色会比重新生成整个词云快很多to_array()# 转化为 numpy arrayto_file(filename)# 输出到文件
实战
from wordcloud import WordCloud # 导入词云库
from PIL import Image # 导入PIL图库
import jieba # 导入jieba分词库
import numpy as np # 导入数据处理库
def read_word(text_path):
with open(text_path, 'r', encoding="utf-8") as f:
cut_word = jieba.cut(f.read()) # 分词处理
result = " ".join(cut_word) # 分词后在单独个体之间加上空格
img = Image.open("timg.png") # 打开背景图片
img_array = np.array(img) # 设置词云形状
stop_words = ["说", "说道", "道", " "]
# 自定义词云
wc = WordCloud(
font_path=r"C:\Windows\Fonts\微软雅黑\msyh.ttc", # 设置字体样式(中文文字需要添加中文字体)
background_color="white", # 背景颜色(默认黑色背景,也是可以实现效果,但是不太漂亮)
mask=img_array, # 遮罩层,除白色背景外,其余图层全部绘制
scale=8, # 使用比例尺比设置画布尺寸
max_font_size=100,
repeat=False, # 去除重复词汇
stopwords=stop_words # 屏蔽词(list格式)
)
wc.generate_from_text(result)
wc.to_file("dan_mu.png") # 保存词云图
if __name__ == '__main__':
read_word("dan_mu.txt")
结尾
》本案例是接着 “爬b站弹幕” 的拓展部分,将弹幕信息生成词云图。弹幕爬虫可以访问下文链接:
https://blog.csdn.net/ytraister/article/details/107361218
》通过本文,可以了解到其他python库的用法,制作出好看的词云图海报。
》本文参考如下几个博客✍:
- https://blog.csdn.net/csdnnews/article/details/106754771
- https://blog.csdn.net/moshanghuali/article/details/84667136
- https://blog.csdn.net/qq_39985298/article/details/90234830