Hadoop核心组件的HDFS安装与配置(二)
环境资源
操作系统版本
]$ cat /etc/centos-release
CentOS Linux release 7.5.1804 (Core)
安装HDFS
IP规划
| 角色 | 主机名 | IP地址 |
|---|---|---|
| NameNode(nn),SecondaryNameNode | nn | 192.168.1.60 |
| DataNode(DN)1 | node1 | 192.168.1.61 |
| DataNode(DN)2 | node2 | 192.168.1.62 |
| DataNode(DN)3 | node3 | 192.168.1.63 |
如果对HDFS等相关节点的设置不明白请参考
Hadoop核心组件的介绍(一)
https://mp.csdn.net/postedit/102629533
准备工作
1.所有节点主机安装Java环境
Hadoop是使用Java编写的,所以我们需要安装Java环境
[root@nn01 ~]# for i in nn node{1..3};do ssh $i "yum -y installed java-1.8.0-openjdk-devel"
安装完成后会产生jps命令
[root@nn ~]# jps
2907 Jps
2.所有主机修改/etc/hosts文件
[root@nn ~]# vim /etc/hosts
192.168.1.60 nn
192.168.1.61 node1
192.168.1.62 node2
192.168.1.63 node3
[root@nn01 ~]# for i in nn node{1..3};do scp /etc/hosts $i:/etc/hosts ;done
3.配置nn主机对所有主机(包括自己)的ssh免密操作
NameNode对DataNode节点和自己的操作都是通过SSH来实现的,所以我们需要对所有主机进行免密操作
[root@nn ~]# ssh-keygen -f ~/.ssh/id_rsa -N ''
[root@nn ~]# for i in nn node{1..3};do ssh-copy-id $i;done
使用nn主机远程登录其他主机进行测试
[root@nn ~]# ssh node1
[root@nn ~]# ssh node2
[root@nn ~]# ssh node3
4.nn主机修改/etc/ssh/ssh_config文件,实现远程登录免输yes操作
[root@nn ~]# vim /etc/ssh/ssh_config
Host *
GSSAPIAuthentication yes
StrictHostKeyChecking no #需要手动添加这条命令,取消yes输入
5.所有禁用SELinux和FireWalld
[root@nn ~]# vim /etc/selinux/config
SELINUX=disabled
[root@nn ~]# reboot
[root@nn ~]# systemctl stop firewalld
[root@nn ~]# systemctl mask firewalld
在nn节点主机上开始安装Hadoop
1.解压安装包
[root@nn ~]# tar -xf hadoop-2.7.7.tar.gz
[root@nn ~]# cp -r hadoop-2.7.7 /usr/local/hadoop
将hadoop的工作目录修改为/usr/local/
2.修改hadoop-env.sh文件
hadoop-env.sh文件中定义了Java安装路径和hadoop配置文件路径,这里需要修改这两项的配置
[root@nn ~]# vim /usr/local/hadoop/etc/hadoop/hadoop-env.sh
25 export JAVA_HOME="/usr/lib/jvm/java-1.8.0-openjdk-1.8.0.161-2.b14.el7.x86_64/jre"
33 export HADOOP_CONF_DIR="/usr/local/hadoop/etc/hadoop"
#将这两项的配置与实际对应起来
3.修改core-site.xml
[root@nn ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
[root@nn ~]# vim /usr/local/hadoop/etc/hadoop/core-site.xml
#在
fs.defaultFS #文件系统配置参数
hdfs://nn01:9000
hadoop.tmp.dir #数据目录配置参数
/var/hadoop #指定hadoop数据的存储目录
具体的配置参数名称可以从
http://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-common/core-default.xml中寻找
4.修改hdfs-site.xml
[root@nn ~]# vim /usr/local/hadoop/etc/hadoop/hdfs-site.xml
#在
dfs.namenode.http-address #NameNode地址声明
nn01:50070
dfs.namenode.secondary.http-address #SecondaryNameNode地址声明
nn01:50090
dfs.replication #数据文件冗余份数
2
具体的配置参数名称可以从
http://hadoop.apache.org/docs/r2.7.7/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml中寻找
5.修改slaves文件
[root@nn ~]# vim /usr/local/hadoop/etc/hadoop/slaves
#添加DataNode节点主机名
node1
node2
node3
6.将修改完的同步给其余的NameNode节点主机
Hadoop所有节点的配置参数完全一样,在nn主机上配置好后把配置文件同步到其他主机上即可
[root@nn ~]# for i in nn node{1..3};do rsync -aXSH /usr/local/hadoop $i:/usr/local/ &
> done
7.nn主机上格式化操作
[root@nn ~]# cd /usr/local/hadoop
[root@nn ~]# ./bin/hdfs namenode -format
会出现成功的信息:
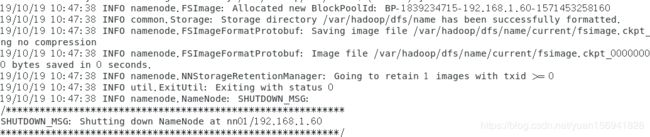
这里很容易出现错误,如果出现错误,检查下是否配置nn主机对所有主机的SSH免密操作,再检查配置4个配置文件的参数和值有没有写错.
8.在nn主机上启动集群
[root@nn ~]# cd /usr/local/hadoop
[root@nn ~]# ./sbin/start-dfs.sh
出现如下的信息:

通过命令
[root@nn ~]# cd /usr/local/hadoop
[root@nn ~]# ./bin/hdfs dfsadmin -report
查看集群节点信息:
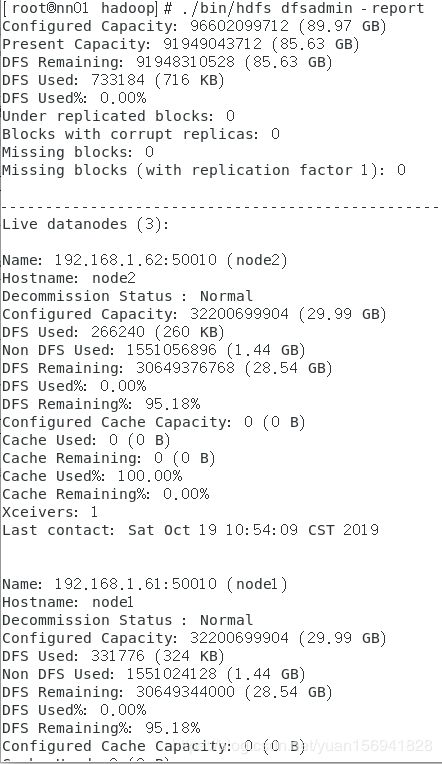
如果不出现节点信息,全部为0,请检查4个配置文件,查看具体参数和值有没有书写错误.
所有节点主机查看角色验证
[root@nn ~]# cd /usr/local/hadoop
[root@nn ~]# jps
到这里,我们的HDFS组件就算是搭建完成了,唯一比较困难的就是书写core-site.xml和hdfs-site.xml配置文件,首先要注意这两配置文件的书写格式:
参数名称
值
参数名称和值需要到官方网站
http://hadoop.apache.org/docs/ 中找到安装使用Hadoop的版本,在左下角Configuration中寻找对应的配置文件默认参数及其值,对使用者的英文要求比较高.
9.遇到的问题
-
Hadoop集群启动,NameNode节点启动不起来,出现如下问题:
jps查看不到NameNode的信息
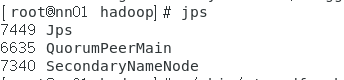
错误日志出现如下报错:
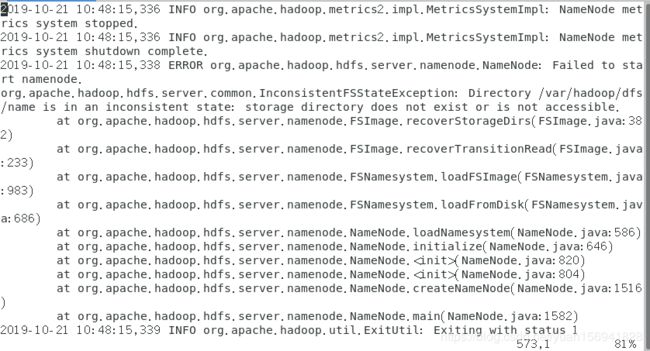
**分析原因:**可能是由于关机的时候直接断电,没有使用poweroff命令关机,导致数据出现问题
解决方法:
- 先停止[Hadoop集群 : /usrl/local/hadoop/sbin/stop-all.sh
- 在删除工作目录下的所有数据: rm -rf /var/hadoop/*
- 再重新格式化NameNode: /usrl/local/hadoop/bin/hdfs namenode -format
- 然后重新启动集群: /usrl/local/hadoop/sbin/start-all.sh
- 最后重新查看信息: jps
HDFS的用法
| HDFS命令 | Shell命令 |
|---|---|
| # ./bin/hadoop fs -ls / | # ls / |
| # ./bin/hadoop fs -mkdir /abc | # mkdir /abc |
| # ./bin/hadoop fs -touchz /abc/a.txt | # touch /abc/a.txt |
| # ./bin/hadoop fs -put localfile /remotefile | 上传文件 |
| # ./bin/hadoop fs -get /remotefile | 下载文件 |
Hadoop词频统计(用法示例)
[root@nn ~]# cd /usr/local/hadoop
[root@nn ~]# ./bin/hadoop fs -mkdir /iniput #创建文件夹
[root@nn ~]# ./bin hadoop fs -put *.txt /input # 上传要分析的文件
[root@nn ~]#./bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.7.7.jar wordcount /input /output # 提交分析作业
[root@nn ~]#./ bin/hadoop fs -cat outpu/* # 查看结果