基于R语言的Kaggle案例分析学习笔记(八)

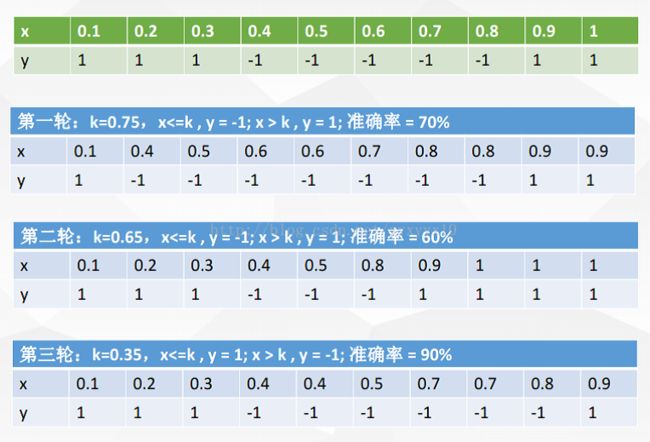
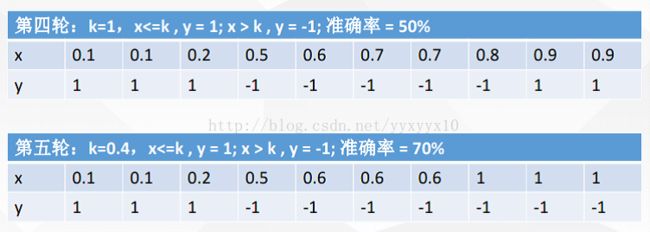
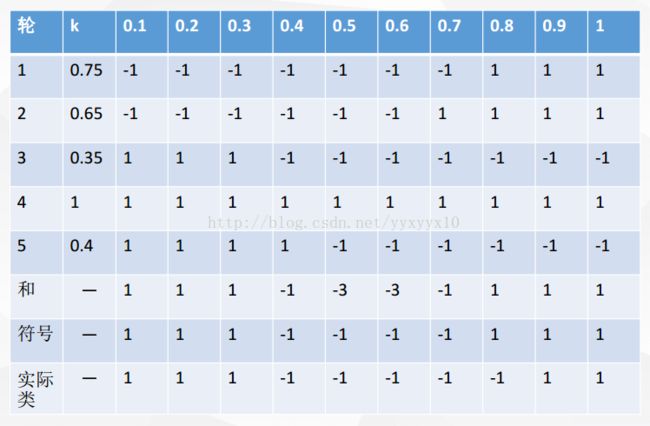
> iris2<-data.table(iris)#data.table出来的数据框多了一个带冒号的索引
> head(iris2)
Sepal.Length Sepal.Width Petal.Length Petal.Width Species
1: 5.1 3.5 1.4 0.2 setosa
2: 4.9 3.0 1.4 0.2 setosa
3: 4.7 3.2 1.3 0.2 setosa
4: 4.6 3.1 1.5 0.2 setosa
5: 5.0 3.6 1.4 0.2 setosa
6: 5.4 3.9 1.7 0.4 setosairis2[,Species]
[1] setosa setosa setosa setosa setosa setosa setosa setosa
[9] setosa setosa setosa setosa setosa setosa setosa setosa
[17] setosa setosa setosa setosa setosa setosa setosa setosa
[25] setosa setosa setosa setosa setosa setosa setosa setosa
[33] setosa setosa setosa setosa setosa setosa setosa setosa
[41] setosa setosa setosa setosa setosa setosa setosa setosa
[49] setosa setosa versicolor versicolor versicolor versicolor versicolor versicolor
[57] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[65] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[73] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[81] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[89] versicolor versicolor versicolor versicolor versicolor versicolor versicolor versicolor
[97] versicolor versicolor versicolor versicolor virginica virginica virginica virginica
[105] virginica virginica virginica virginica virginica virginica virginica virginica
[113] virginica virginica virginica virginica virginica virginica virginica virginica
[121] virginica virginica virginica virginica virginica virginica virginica virginica
[129] virginica virginica virginica virginica virginica virginica virginica virginica
[137] virginica virginica virginica virginica virginica virginica virginica virginica
[145] virginica virginica virginica virginica virginica virginica
Levels: setosa versicolor virginica
> iris2[,.(Species)]
Species
1: setosa
2: setosa
3: setosa
4: setosa
5: setosa
---
146: virginica
147: virginica
148: virginica
149: virginica
150: virginica
#在列名Species不加点的情况下,返回一个向量,加点的时候返回dataframe的Species这一列数据。
iris2[,.(sum=sum(Petal.Length),sd=sd(Sepal.Width))]#求Length列的和与Width列的方差
sum sd
1: 563.7 0.4358663 iris2[,.(sum=sum(Petal.Length)),by=.(Species)]#以Species这一列为分组标准,进行分组求和
Species sum
1: setosa 73.1
2: versicolor 213.0
3: virginica 277.6 iris2[,.N,by=.(Species)]#以Species这一列为分组标准,进行分组计数
Species N
1: setosa 50
2: versicolor 50
3: virginica 50> iris2[,Species:=NULL]#:=表示更新,这里NULL表示把Species删除,运行结果发现已经没有这一列了。 > iris2 Sepal.Length Sepal.Width Petal.Length Petal.Width 1: 5.1 3.5 1.4 0.2 2: 4.9 3.0 1.4 0.2 3: 4.7 3.2 1.3 0.2 4: 4.6 3.1 1.5 0.2 5: 5.0 3.6 1.4 0.2 --- 146: 6.7 3.0 5.2 2.3 147: 6.3 2.5 5.0 1.9 148: 6.5 3.0 5.2 2.0 149: 6.2 3.4 5.4 2.3 150: 5.9 3.0 5.1 1.8 |
|
|
4、xgboost案例
(1)xgboost回顾
1) xgboost只接受独热内编码的数据类型,不接受一般的数据类型
2) xgb的参数包括三类即通用参数、辅助和任务。
通用参数为我们提供在上升过程中选择哪种模型。常用的是树或线性模型。
辅助参数是细化上升模型。
任务参数决定学习场景。
(2)案例背景
法国巴黎银行索赔管理。数据集是关于索赔者的一些属性,包含分类变量和数字变量,根据这些属性判断索赔者属于加速索赔类的概率,为1表示合适加速批准索赔,为0表示不适合加速批准索赔。
(3)xgb解题思路
1)选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存) 选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存) 选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存) 选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存) 选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存) 选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存) 选取部分数据进行计算(因为单机运完整集耗时较长且很占用内存)
2)特征工程,将 V22 V22列与其他几相结合,因为作者通过多次试验发现 列与其他几相结合,因为作者通过多次试验发现 列与其他几相结合,因为作者通过多次试验发现 列与其他几相结合,因为作者通过多次试验发现 列与其他几相结合,因为作者通过多次试验发现 V22 V22和其他几列结合产生的新 和其他几列结合产生的新 和其他几列结合产生的新 和其他几列结合产生的新 特征能提高 CV 的准确率。
3)将字符类型的数据换成target均值
(4)用xgboost分类求解
gtool包的combination函数让某些变量进行以某种形式进行组合,combination(m,n,data),m表示data的m个变量进行n n组合,若m等于3,n等于2则表示data的3个变量进行两两组合。以上解题思路的2)、3)都是特征工程部分,这部分比较难。以下给出代码:
数据下载地址:https://www.kaggle.com/c/bnp-paribas-cardif-claims-management/data.
library(gtools)
library(xgboost)
library(methods)
library(data.table)
data.train<-fread('D:/R语言kaggle案例实战/Kaggle第八节课/data/train.csv')
data.test<-fread('D:/R语言kaggle案例实战/Kaggle第八节课/data/test.csv')
data.train[is.na(data.train)]<- -1#将空值赋值为-1
data.test[is.na(data.test)]<- -1
x.train<-data.train[,-1,with=F]#将ID列去除,with=F表示可以用数字表示列名
x.test<-data.test[,-1,with=F]
y.train<-data.train$target#训练集的目标列提取出来
id.test<-data.test$ID#提取测试集的ID提取出来
omit.var<-c(1:3,4:9,11,13,15:20,23,25:29,32:33,35:37,39,41:46,48:49,51,53:55,57:61,63:65,67:71,73:74,76:78,80:90,92:107,108:111,115:128,130:131)#因为数据比较多,所以提取重要的列,omit.var是不重要的列
x.train<-x.train[,-(omit.var+1),with=F]#去除omit.var这些不重要的列,+1是因为x.train中有target列,要跳过这一列
x.test<-x.test[,-(omit.var),with=F]
char.var<-colnames(x.train)[sapply(x.train,is.character)]#提取训练集的字符类型的列的列名
cmb<-combinations(length(char.var),2,char.var)#combination让数据类型为字符类型的列名进行两两组合
head(cmb)
for( i in 1:nrow(cmb)){#循环的目的是将上面列名两两组合的结果变成这些列的数据进行两两组合
x.train[[paste0(cmb[i,1],cmb[i,2])]]<-paste(x.train[[cmb[i,1]]],x.train[[cmb[i,2]]])
x.test[[paste0(cmb[i,1],cmb[i,2])]]<-paste(x.test[[cmb[i,1]]],x.test[[cmb[i,2]]])
}
cmb<-combinations(length(char.var)-1,2,char.var[-match("v22",char.var)])#根据解题思路,“v22"与其他列组合会提高准确率,
#-match("v22",char.var)表示除了”v22"之外的列
#cmb就是除了"v22"之外的的变量进行两两组合。
for( i in 1:nrow(cmb)){
x.train[[paste0("v22",cmb[i,1],cmb[i,2])]]<-paste(x.train[["v22"]],x.train[[cmb[i,1]]],x.train[[cmb[i,2]]])#将"v22"这个变量与cmb两两组合结果进行组合变成了”v22“与char.var的变量三三组合
x.test[[paste0("v22",cmb[i,1],cmb[i,2])]]<-paste(x.test[["v22"]],x.test[[cmb[i,1]]],x.test[[cmb[i,2]]])
}
cmb<-combinations(length(char.var)-1,length(char.var)-3,char.var[-match("v22",char.var)])#进行十十组合
#以下累计合并
for( i in 1:nrow(cmb)){
new.var.train<-x.train[["v22"]]
new.var.test<-x.test[["v22"]]
new.var.name<-"v22"
for(v in 1:ncol(cmb)){
new.var.train<-paste(new.var.train,x.train[[cmb[i,v]]])
new.var.test<-paste(new.var.test,x.test[[cmb[i,v]]])
new.var.name<-paste0(new.var.name,cmb[i,v])
}
x.train[[new.var.name]]<-name.var.train
x.test[[new.var.name]]<-new.var.test
}
#以下将字符型的数据换成target列的均值
for(var in colnames(x.test)) {
if(is.character(x.test[[var]])) {
target.mean <- x.train[, list(pr=mean(target)), by=eval(var)]#将判断出来的字符型列var的数据换成target均值
x.test[[var]] <- target.mean$pr[match(x.test[[var]], target.mean[[var]])]#将相同var赋予相同target均值
temp <- rep(NA, nrow(x.train))
for(i in 1:4) {
ids.1 <- -seq(i, nrow(x.train), by=4)
ids.2 <- seq(i, nrow(x.train), by=4)
target.mean <- x.train[ids.1, list(pr=mean(target)), by=eval(var)]
temp[ids.2] <- target.mean$pr[match(x.train[[var]][ids.2], target.mean[[var]])]
}
x.train[[var]] <- temp
}
}
params<-list("ets"=0.1,"max_depth"=6,"colsample_bytree"=0.45,
"objective"="binary:logistic","eval_metric"="logloss")#目标函数为二分类逻辑回归。
x.train[, target:=NULL]
exp.var <- as.data.frame(colnames(x.train))
x.train <- as.matrix(x.train)
x.test <- as.matrix(x.test)
x.train <- matrix(as.numeric(x.train), nrow(x.train), ncol(x.train))
x.test <- matrix(as.numeric(x.test), nrow(x.test), ncol(x.test))
xgb.train <- xgb.DMatrix(x.train, label=y.train)
model.xgb <- xgb.train(param=params, data=xgb.train, nrounds=nrounds, watchlist=list(train=xgb.train), print.every.n=50)
predict <- predict(model.xgb, x.test)
predict <- cbind(ID=data.test$ID, PredictedProb=predict)
write.csv(predict, paste0("Submission2.csv"), row.names=FALSE)