Python 从Web抓取信息
如果帮到你的话,请点个赞,创作不易,谢谢
'Web下载’即一个术语,利用Python程序从网页下载信息并处理它,即我们所说的爬虫,一些搜索引擎也是利用无数个Web抓取程序,对网页进行索引从而实现用户的搜索需求。Web抓取需要积极模块,比如:
(1)webbrowser;Python自带的,打开浏览器获取指定页面
(2)requests
文章目录
- 1.1 利用webbrowser的Seekaddress.py
- 1.1.1 编写一个函数Seekaddress.py
- 1.2 用requests模块从网页下载文件
- 1.2.1 用requests.get()下载一个网页
- 1.2.2 检查错误
- 1.3 将下载的文件保存到硬盘
- 1.4 HTML
- 1.4.1 学习html的基础
- 1.4.2 查看网页的HTML源代码
- 1.4.3 使用开发者工具
- 1.4.4使用开发者工具来寻找HTML元素
- 1.5 用BeautifulSoup模块解析HTML
- 1.5.1 从html创建一个BeautifulSoup对象
- 1.5.2 用select()方法寻找元素
- 1.5.3 通过元素的属性获取数据
1.1 利用webbrowser的Seekaddress.py
通过import引入webbrowser模块,该模块的open函数可以调用一个浏览器(默认浏览器)打开网站,
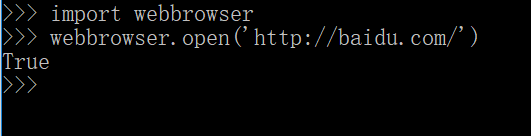
open函数还可以做一些其它的事情,比如查找地址。查找地址一般分为以下几步:
(1)打开搜索网站,比如百度
(2)输入搜索地址或者勾选高亮地址,并进行复制
(3)在搜索栏进行粘贴,然后回车
编写程序的话需要以下几步:
(1)从剪贴板中或命令行参数中获得地址内容
(2)打开浏览器,并粘贴地址进入网站找寻地址
这将意味着代码要做下面的事:
(1)从sys.argv[] 读取命令行参数或者读取剪贴板内容
(2)调用webbrowser.open()函数打开网页
1.1.1 编写一个函数Seekaddress.py
第一步:弄清楚URL
当你从命令行执行它时,要使用命令行参数(先cd 路径 切换到py文件的目录)
![]()
我们需要弄清楚URL,怎样才能通过open函数直接打开浏览器转到该地址所代表的网页下,当我们在百度中寻找地址时,URL诸如此类地址后面还加了许多文件名的`,(因为是超链接,分布在服务器的每一个文件里,检索的时候需要搜索文件)但是你会发现https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd=地址,这样也可以打开同一个网页。剪贴板上可以这样然后复制,然后不需要加参数就可以攒文本编辑界面运行程序

第二步:处理命令行参数
代码如下:
#python 3.7
# Seekaddress.py-Seeking a position in the browser using an address from the
# command line or clipboard
import webbrowser,sys,pyperclip
if len(sys.argv)>1:
address=' '.join(sys.argv[1:])
# TODO:Get addres from clipboard
在程序的解释行下通过import 引入webbrowse模块,用来开启浏览器并打开网站,引入sys模块用来判断命令行参数和程序本身(即py 文件名),关于sys可以看这,并且引入pyperclip模块,处理以后的粘贴板上带的地址。sys这个变量保存了参数和程序本身的列表,sys.argv[0]返回文件本身,sys.argv[1:]往后的值之包含参数。如果len(sys.argv)大于1,表明这个命令行不只有文件名,否则说明地址在剪贴板上。
命令行参数通常用空格分隔开,在这段代码中,所有参数将被作为一整个字符串当作地址,因为sys.argv是字符串列表,可以使用 join() 方法来将其所包含的参数连接为一个字符串.sys.argv包含的字符串列表类似于这样 [‘山西省’,‘忻州市忻府区’],join()方法将这样的列表转为为address这样的变量,这个变量是这样的,‘山西省忻州市忻府区’
第三步:处理剪贴板内容,加载浏览器
通过webrowser的open函数,将地址加入到url中并打开此网页
#python 3.7
# Seekaddress.py-Seeking a position in the browser using an address from the
# command line or clipboard
import webbrowser,sys,pyperclip
if len(sys.argv)>1:
address=' '.join(sys.argv[1:])
# TODO:Get addres from clipboard
else:
address=pyperclip.paste()
webbrowser.open('https://www.baidu.com/s?ie=utf-8&f=8&rsv_bp=1&rsv_idx=1&tn=baidu&wd='+address)
1.2 用requests模块从网页下载文件
requests模块让你很容易从Web下载文件不需要担心一些不必要的问题,比如网络错误,连接问题和数据压缩,在Python命令行输入import requests,如果没有安装此模块,则在dos命令界面输入pip install requests来联网下载此模块
1.2.1 用requests.get()下载一个网页
通过import引入requests模块,然后requests.get()传入一个下载地址的URl字符串,通过在requests.get()的返回值上调用type,可以看到返回一个Response对象,其中包含了Web服务器对你的请求作出的响应
import requests
book=requests.get(‘http://www.kusuu.net/dlurl.php?id=839212&name=%B4%F3%D6%F7%D4%D7&ln=1’)
type(book)
book.status_code==requests.codes.ok
Truelen(book.text)
51462
通过返回对象的status_code判断book.status_code==requests.codes.ok,可以得出当前状态正常(协议中’ok’的状态码为200,页面丢失状态码为404)
1.2.2 检查错误
Response返回对象有一个status_code属性,来检查下载是否正常。检查成功还有一个方法,就是在Response对象上调用raise_for_status()方法。如果下载文件出错,将抛出异常。如果下载成功,则无应答。

raise_for_status()方法可以在程序出错时暂停下来。如果你希望程序在下载时发生错误而不是程序终止,可以利用try 和 except 语句来处理这个异常,使程序能够继续执行下去,将异常传递给一个变量,将这个变量输出
import requests
book=requests.get('http://d.bxwx666.org/txt/40/52989/52989.txt')
try:
book.raise_for_status()
except Exception as error:
print('There was a problem :%s'%(error))
在调用resquests.get()后继续执行raise_for_status()方法确保下载成功后继续执行。
1.3 将下载的文件保存到硬盘
我们可以使用标准的open和write方法,将Web页面保存到一个文件中,但与普通文件不同的是,必须用二进制模式打开该文件,即向open函数传入第二个参数’wb’。即使该页面是纯文本的,也需要写入二进制数据,而不是文本数据,目的是为了保存文本中的Unicode编码。
为了将内容写入文件。可以利用for循环以及Response对象的iter_content()方法
iter_content()方法在每次的迭代中都会返回一段内容,该内容为Byte字节,需要给该字节指定大小,所创建的文件存储在当前工作目录,requests模块只负责获取文件,即使你切断与该网页的数据连接,数据内容仍保存在你的计算机中。需要利用write方法来将内容写入你创建的文件中,并在最后使用close()方法来关闭文件时文件生效。
for循环和iter_content()方法是为了在下载过程中不占用太大的内存,而使计算机正常工作。
![]()


![]()
1.4 HTML
在我们拆解网页之前,我们需要学习一些HTML知识,学习如何利用Web浏览器的强大的开发者工具,利用他们使得从Web抓取信息更容易
1.4.1 学习html的基础
学习html的基础可以来这里,菜鸟教程
1.4.2 查看网页的HTML源代码
可以在浏览器中的任意页面,在空白区域点击右键,会有查看网页源代码选项,诸如下图:
了解一些网页编写框架以及方式,有助于你更好的编写程序来抓取网页上的内容
1.4.3 使用开发者工具
一般浏览器都可使用F12来使用开发者工具,包括Chrome,Firefox,IE浏览器,QQ浏览器等,Opera浏览器等需要在选项中选择开发者选项,点击页面元素内容然后右键点击检查元素,就可查看相应的代码
1.4.4使用开发者工具来寻找HTML元素
在利用requests模块下载一个网页的内容后,会将该内容所对应的HTML值作为一个字符串,你需要筛选来找到你感兴趣的内容。
接下来就可以利用开发者工具,假定你编写了一个程序,需要获取某个地方的年降水量,就可以点击该网页上的年降水量所对应的HTML源代码,然后利用BeautifulSoup来寻找该源代码所在的类所包含的该信息。
1.5 用BeautifulSoup模块解析HTML
利用BeautifulSoup模块来解析HTML元素(此模块比正则表达式匹配html元素合适),BeautifulSoup模块的名称是bs4(意思为BeautifulSoup 第四版),在python界面输入import bs4来引入该模块,如果出错,则在dos界面输入pip install BeautifulSoup4 来进行安装该模块。BeautifulSoup模块可以在HTML不同的标签和属性中查找特定的元素。下面引用菜鸟教程的html代码块
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8">
<title>菜鸟教程(runoob.com)</title>
</head>
<body>
<a href="//www.runoob.com">访问菜鸟教程!</a>
</body>
</html>
1.5.1 从html创建一个BeautifulSoup对象
bs4.BeautifulSoup()函数调用时需要用到一个字符串,该函数将返回一个BeautifulSoup对象,该对象保存在一个变量中
import requests,bs4
res=requests.get(‘https://www.runoob.com/try/try.php?filename=tryhtml_link_test’)
res.raise_for_status()
runSoup=bs4.BeautifulSoup(res.text)
type(runSoup)
len(res.text)
7601
利用requests模块从网页下载内容以后 ,先检查该下载内容是否正常,然后将该内容的text属性的文本内容传递给bs4.BeauifulSoup()函数,然后该函数返回对象赋值给变量runSoup。
(2)也可以从硬盘加载html并利用bs4.BeautifulSoup()函数

1.5.2 用select()方法寻找元素
在html中查找特定元素,可以使用select()方法来传入不同的参数,从而实现对不同的标签,以及类的查找,类似于正则表达式。
| soup.select(‘p’) | 查找所有标签为 的元素 |
|---|---|
| soup.select(‘div’) | 查找所有标签为 的元素 |
| soup.select(’#demo’) | 查找所有id属性为demo的元素 |
| soup.select(’#author’) | 查找所有id属性为author的元素 |
| soup.select(’.center’) | 查找所有class属性名为center的元素 |
| soup.select(‘div span’) | 查找所有在 标签内的元素 |
| soup.select(‘div >span’) | 查找所有在 标签内的元素,中间没有其他其他元素 |
| soup.select('input[name]) | 查找所有名为的标签,其中有一个属性name,值名可以任意 |
| soup.select('input[type=“text”]) | 查找所有名为的标签,其中有一个属性type,值名为text的元素 |
>>> content=open('C:\\Users\\张朝阳\\Documents\\表单.html','rb')
>>> contentSou=bs4.BeautifulSoup(content.read())
>>> type(contentSou)
<class 'bs4.BeautifulSoup'>
>>> len(contentSou)
2
>>> elems=contentSou.select('h4')
>>> type(elems)
<class 'bs4.element.ResultSet'>
>>> len(elems)
9
>>> elems[0].getText()
'这是单选框'
>>> str(elems[0])
'这是单选框
'
第一步:打开html文件 第二步:通过bs4.BeautifulSoup()方法将之转化为HTML对象
第三步:通过select()方法将所要的元素查找出来,返回一个Tag对象的列表
elems[0]为得到的字符串的第一个元素
getText()方法为输出文本内容
str()将返回的Tag值转换为一个字符串
>>> import requests,bs4
>>> res=requests.get('https://www.runoob.com/try/try.php?filename=tryhtml_a_href')
>>> res.raise_for_status()
>>> resSoup=bs4.BeautifulSoup(res.text)
>>> type(resSoup)
<class 'bs4.BeautifulSoup'>
>>> elems=resSoup.select('p')
>>> type(elems)
<class 'bs4.element.ResultSet'>
>>> len(elems)
1
>>> type(elems[0])
<class 'bs4.element.Tag'>
>>> elems[0].getText()
'Copyright © 2013-2020菜鸟教程'
>>> str(elems[0])
'Copyright © 2013-2020菜鸟教程
'
1.5.3 通过元素的属性获取数据

、

attrs 方法为将返回的Tag值转化为字典