SparkContext初始化流程
SparkContext的初始化,包括事件总线(LiveListenerBus),UI界面,心跳,JobProcessListner,ExecutorAllocationManager(资源动态分配管理)等等等等,总之就是有很多东西,这里我只选取几个自认为是核心的东西介绍一下:
- DAGScheduler: 负责创建Job,RDD的Stage划分以及提交,还有一些监控数据
- TaskScheduler:负责Task的调度,它所调度的Task是由DAGScheduler创建的
- ***schedulerBackend:负责连接Master并注册当前的程序;申请资源(Executor)和task具体到Executor的执行和管理,具体类型和deploy Mode有关比如standalone或者on yarn
- SparkEnv: Spark运行时环境。Executor依赖SparkEnv,它内部包含有很多组件,例如serializerManager,RpcEnv,BlockManager。(Driver中也有SparkEnv,这个是为了Local[*]模式下能运行)
DAGSchedule:
一句代码就搞定了:_dagScheduler = new DAGScheduler(this),分析下它的构造函数。发现初始化它需要6个变量:

可以看出taskSchedluer是在它之前就创建好了的。sc代表SparkContext,sc.listenerBus代表事件总线,异步监听Spark的各种事件。这里有两个不认识的变量,一个是mapOutputTracker,另外一个是blockManager.master,说一下这两个东西,非常重要。
mapOutputTracker:看名字就知道,它是用于记录map将数据结果写到哪里去了,用于reduce阶段任务获取地址以及结果。每个map/reduce任务都会有唯一ID标识,一个reduce如果到多个map任务的节点上去拉取Block,这个就叫宽依赖,它的过程叫Shuffle,这个类后面说到Shuffle那里要重点说下的。
blockManager.master:BlockManager是对Executor上的Block的数据进行管理的,而Driver上的master是对存在于Executor上的BlockManager进行统一的管理,记录Block相关的信息(位置,是否移除啊等等),这个也是后面说到Shuffle那里重点说下。
TaskScheduler & ***SchedulerBackend:

这里创建的时候,一口气创建了两个变量,taskScheduler自然不用说,是用来执行具体的task用的,另外一个schedulerBackend则是用于Application运行期间与底层资源调度系统交互,申请资源&Task的执行和管理,至于是怎么申请和执行的,下面会说到。
看下它的入参有deployMode,也是是说task的执行和调度方式适合程序设置的任务运行方式有关的,根据不同的deployMode创建不同的调度方式!此处以StandAlone运行模式为例,看下代码是怎么走的:

1.首先new TaskSchedulerImpl,这里设定了个单个Task相关的一些配置,例如每个task默认用一个cpu, host和Executors之间的映射

还有这三个很重要的变量都在这可以找到。

2.接着new ***Backend(),这里就是设置了最多可以用多少cores: conf.getOption("spark.cores.max")
3.接着就是选择调度方式,默认是FIFO:这时调度是用于调动单个App中的多个Task是用的,个人猜测可能是在多个线程对同一个RDD进行操作的时候会用到这个调度器,决定那个job先执行

4.最后执行:_taskScheduler.start()
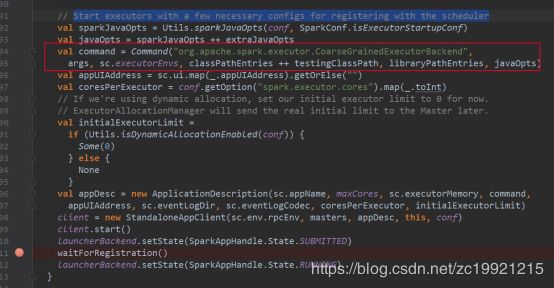
此处先启动schedulerBackend,它的启动就是创建了driverEndPoint,这个可以用来和Executor之间进行通信,这时单独开的一个线程,点到它的connect()方法里面就可以看到。

接着记录了APP的相关信息:name/maxCores/executorMemory…,将其封装在ApplicationDescription类里面。
最后,使用这个Descriptionhe/Master/SparkConf/RPCEndPoint等信息,创建并启动了StandaloneAppClient,这个是和Spark集群交互用的,用于Register应用并接受处理来自Master的这种消息:如 RegisteredApplication、ApplicationRemoved、ExecutorAdded 等,在接受到这种消息的同时会调用SchedulerBackend进行一些处理。
在client.start()中会调用它的onStart()方法,先是向Spark集群的Master注册APP,然后经过一系列的操作最终启动Executor,过程很复杂,另外写一篇博客单独分析。
从我执行任务的从日志中可以看出,执行_taskScheduler.start()的时候,Executor就已经ADD了。


start()内部是这么执行的:
SparkEnv:
SparkEnv中包括了与存储、计算、通信相关的很多功能,在Driver和Executor进程中都存在,因为两者的功能不能,所以创建出来的变量也有所不同,大致上都会创建如下功能:
序列化管理、map/shuffle管理,block管理,Memory管理等等,相当于所有资源管理功能(除了CPU核数)都会在这里创建。因为这里内容太多了,所以打算是等到看到Spark是如何执行任务的时候再一个个边看边学,这里就先不一个个细讲了,可以看下参考中的链接,大神讲的很清楚了
| 名称 |
说明 |
| SecurityManager |
主要对账户、权限及身份认证进行设置与管理。 |
| RpcEnv |
各个组件之间通信的执行环境。 |
| SerializerManager |
Spark 中很多对象在通用网络传输或者写入存储体系时,都需要序列化。 |
| BroadcastManager |
用于将配置信息和序列化后的RDD、Job以及ShuffleDependency等信息在本地存储。 |
| MapOutputTracker |
用于跟踪Map阶段任务的输出状态,此状态便于Reduce阶段任务获取地址及中间结果。 |
| ShuffleManager |
负责管理本地及远程的Block数据的shuffle操作。 |
| MemoryManager |
一个抽象的内存管理器,用于执行内存如何在执行和存储之间共享。 |
| NettyBlockTransferService |
使用Netty提供的异步事件驱动的网络应用框架,提供Web服务及客户端,获取远程节点上Block的集合。 |
| BlockManagerMaster |
负责对BlockManager的管理和协调。 |
| BlockManager |
负责对Block的管理,管理整个Spark运行时的数据读写的,当然也包含数据存储本身,在这个基础之上进行读写操作。 |
| MetricsSystem |
一般是为了衡量系统的各种指标的度量系统。 |
| OutputCommitCoordinator |
确定任务是否可以把输出提到到HFDS的管理者,使用先提交者胜的策略。 |
注意下初始化SparkEnv代码中的这个的两个功能,前一个是对Shuffle进行的优化,后一个是对内存管理进行的优化,前者在后续分析Spark Shuffled的时候会重点说先,后者是Spark动态调整的内存模型,后续会单独分析下。

至此,SparkContext的初始化已经完成,总结下就是。SparkContext先是初始化了TaskSchedule和***SchedulerBackend分别进行Task的调度和注册APP并申请资源启动Executor。然后再初始化DAGSchedule,负责Job的执行管理和RDD Stage的划分。然后还有一个SparkEnv,对存储、计算、通信等很多功能进行管理。

参考:
https://blog.csdn.net/qq_21383435/article/details/78603123(MapOutputTracker介绍)
https://blog.csdn.net/lvbiao_62/article/details/79751560(Spark/Hadoop的推测执行机制说明)
https://www.cnblogs.com/xia520pi/p/8609625.html(SparkEnv介绍,非常详细)