Python数据处理的一些总结-1
import pandas as pd
import numpy as np
#载入数据
train=pd.read_csv('Train.csv')
test=pd.read_csv('Test.csv')
#显示一下数据的大小
#可以通过train.shape, test.shape查看
train.dtypes#查看每个属性的类型
train.head(5)#查看前五条数据
#合并成一个总的data
train['source']='train'
test['source']='test'
data=pd.concat([train, test], ignore_index=True)注意,最后一条数据的igonore_index的属性我来解释一下啦
比如有两个表myTrain.csv, myTest.csv,其中,两个表的内容分别是:
myTrain.csv
| a | b |
| 1 | 5 |
| 2 | 6 |
| 3 | 7 |
| 4 | 8 |
| a | b |
| 1 | 5 |
| 2 | 6 |
| 3 | 7 |
| 4 | 8 |
data=pd.concat([train, test], ignore_index=True)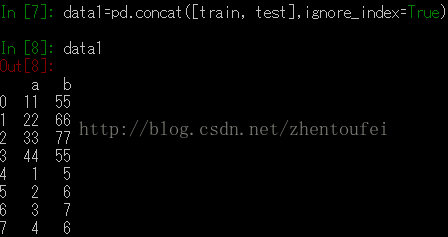
注意看前面的索引值,其实,对于myTrain.csv和myTest.csv两个表来说都有一个自己的索引值,然后在组合的时候这边忽略了
再看:
 、
、
看了这个图片就一目了然了,其实就是索引是否要重新开始而已
好了,我们继续看看下面的代码把:
#在实际的应用中很重的是观察异常点,比如说异常值;
data.apply(lambda x:sum(x.isnull()))
这里看一段代码:


关于lambda表达是解释:Python的lambda表达式可以看看这个博客,随便百度啦,很多解释的,挺容易理解的
字段,分别有多少种取值
var = ['Gender','Salary_Account','Mobile_Verified','Var1','Filled_Form','Device_Type','Var2','Source']
for v in var:
print '\n%s这一列数据的不同取值和出现的次数\n'%v
print data[v].value_counts()
#看看某一个字段与多少的不同的取值
len(data['City'].unique())#data['City'].unique()给出的结果是在该属性下不同城市的名字都列出来
#如果要删除该属性,可以用下面的额代码
data.drop('City',axis=1,inplace=True)
需要解释一下 这里的axis=1和,inplace了,话不多说,上图片
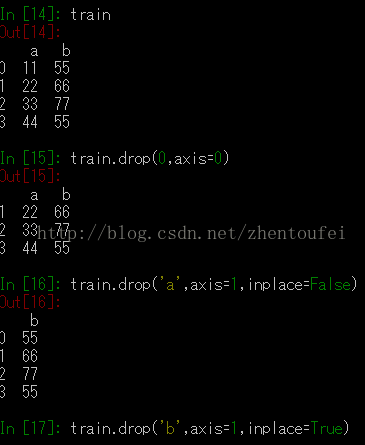
明白了把,axis=0表示的是要对横坐标操作,axis=1是要对纵坐标操作
inplace=False表示要对结果显示,而True表示对结果不显示
#DOB是出生的具体日期,咱们要具体日期作用没那么大,年龄段可能对我们有用,所有算一下年龄好了
#创建一个年龄的字段Age
data['Age'] = data['DOB'].apply(lambda x: 115 - int(x[-2:]))
data.drop('DOB',axis=1,inplace=True)#删除原先的字段
data.boxplot(column=['EMI_Loan_Submitted'],return_type='axes')#画出箱线图
#好像缺失值比较多,干脆就开一个新的字段,表明是缺失值还是不是缺失值
data['EMI_Loan_Submitted_Missing'] = data['EMI_Loan_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0)
data[['EMI_Loan_Submitted','EMI_Loan_Submitted_Missing']].head(10)
data.drop('EMI_Loan_Submitted',axis=1,inplace=True)
#看看个数
len(data['Employer_Name'].value_counts())
#看看某一字段的信息
data['Existing_EMI'].describe()
#缺省值不多,用均值代替
data['Existing_EMI'].fillna(0, inplace=True)
#找中位数去填补缺省值(因为缺省的不多)
data['Loan_Amount_Applied'].fillna(data['Loan_Amount_Applied'].median(),inplace=True)
data['Loan_Tenure_Applied'].fillna(data['Loan_Tenure_Applied'].median(),inplace=True)
#处理source
data['Source'] = data['Source'].apply(lambda x: 'others' if x not in ['S122','S133'] else x)
data['Source'].value_counts()
#数值编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
var_to_encode = ['Device_Type','Filled_Form','Gender','Var1','Var2','Mobile_Verified','Source']
for col in var_to_encode:
data[col] = le.fit_transform(data[col])原来的读入文件是:

来编码啦,继续看图:
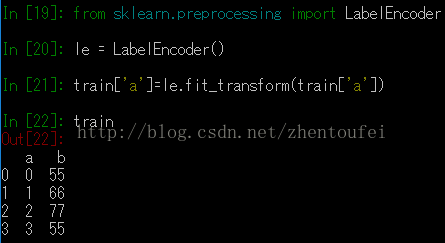
明白了,就是给不同的数字编码呀,起到区分作用的
关键部分的代码如下
import pandas as pd
import numpy as np
#载入数据
train=pd.read_csv('Train.csv')
test=pd.read_csv('Test.csv')
#显示一下数据的大小
#可以通过train.shape, test.shape查看
train.dtypes#查看每个属性的类型
train.head(5)#查看前五条数据
#合并成一个总的data
train['source']='train'
test['source']='test'
data=pd.concat([train, test], ignore_index=True)
#在实际的应用中很重的是观察异常点,比如说异常值;
data.apply(lambda x:sum(x.isnull()))
#要对数据有更深的认识,比如说,咱们看看这些字段,分别有多少种取值(甚至你可以看看分布)
var = ['Gender','Salary_Account','Mobile_Verified','Var1','Filled_Form','Device_Type','Var2','Source']
for v in var:
print '\n%s这一列数据的不同取值和出现的次数\n'%v
print data[v].value_counts()
#看看某一个字段与多少的不同的取值
len(data['City'].unique())#data['City'].unique()给出的结果是在该属性下不同城市的名字都列出来
#如果要删除该属性,可以用下面的额代码
data.drop('City',axis=1,inplace=True)
#DOB是出生的具体日期,咱们要具体日期作用没那么大,年龄段可能对我们有用,所有算一下年龄好了
#创建一个年龄的字段Age
data['Age'] = data['DOB'].apply(lambda x: 115 - int(x[-2:]))
data.drop('DOB',axis=1,inplace=True)#删除原先的字段
data.boxplot(column=['EMI_Loan_Submitted'],return_type='axes')#画出箱线图
#好像缺失值比较多,干脆就开一个新的字段,表明是缺失值还是不是缺失值
data['EMI_Loan_Submitted_Missing'] = data['EMI_Loan_Submitted'].apply(lambda x: 1 if pd.isnull(x) else 0)
data[['EMI_Loan_Submitted','EMI_Loan_Submitted_Missing']].head(10)
data.drop('EMI_Loan_Submitted',axis=1,inplace=True)
#看看个数
len(data['Employer_Name'].value_counts())
#看看某一字段的信息
data['Existing_EMI'].describe()
#缺省值不多,用均值代替
data['Existing_EMI'].fillna(0, inplace=True)
#找中位数去填补缺省值(因为缺省的不多)
data['Loan_Amount_Applied'].fillna(data['Loan_Amount_Applied'].median(),inplace=True)
data['Loan_Tenure_Applied'].fillna(data['Loan_Tenure_Applied'].median(),inplace=True)
#处理source
data['Source'] = data['Source'].apply(lambda x: 'others' if x not in ['S122','S133'] else x)
data['Source'].value_counts()
#数值编码
from sklearn.preprocessing import LabelEncoder
le = LabelEncoder()
var_to_encode = ['Device_Type','Filled_Form','Gender','Var1','Var2','Mobile_Verified','Source']
for col in var_to_encode:
data[col] = le.fit_transform(data[col])
#类别型的One-Hot 编码
data = pd.get_dummies(data, columns=var_to_encode)
data.columns#看看one-hot编码后的列是哪些
#区分训练和测试数据
train = data.loc[data['source']=='train']
test = data.loc[data['source']=='test']
train.drop('source',axis=1,inplace=True)
#保存代码
train.to_csv('train_modified.csv',index=False)
test.to_csv('test_modified.csv',index=False)